Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Double job execution caused by databricks' RemoteS...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Double job execution caused by databricks' RemoteServiceExec using databricks-connector
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-18-2021 11:48 AM
Hello!
I'm using databricks-connector to launch spark jobs using python.
I've validated that the python version (3.8.10) and runtime version (8.1) are supported by the installed databricks-connect (8.1.10).
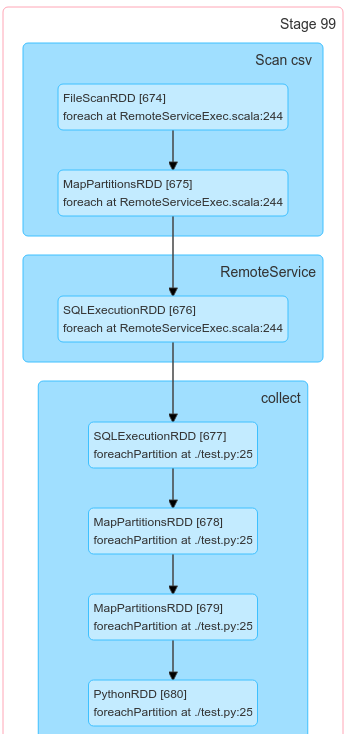
Everytime a mapPartitions/foreachPartition action is created this results in two spark jobs executing, one after the other, duplicating every stage/step that happened before it.
An example code follows:
#!/usr/bin/env python
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, LongType
schema = StructType([
StructField('key', LongType(), True),
StructField('value', StringType(), True)
])
spark = SparkSession.builder.appName('test').getOrCreate()
data = spark.read.schema(schema) \
.option('header', 'true') \
.csv('s3://path/to.csv')
def fun(rows):
print(f"Got a partition with {len(list(rows))} rows")
# these only trigger one job
# data.collect()
# data.count()
# this triggers two!
data.foreachPartition(fun)
This executes two jobs (which is fast in this example but not in real world code!):
The first job, which is the one that I'm not sure why it spawns:

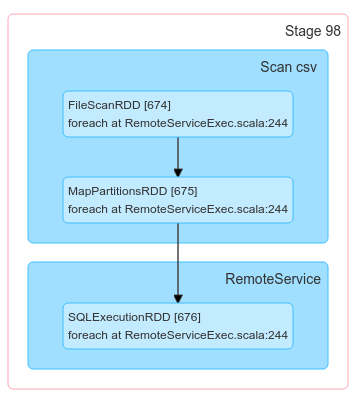
org.apache.spark.rdd.RDD.foreach(RDD.scala:1015)
com.databricks.service.RemoteServiceExec.doExecute(RemoteServiceExec.scala:244)
org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:196)
org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:240)
org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:236)
org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:192)
org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:163)
org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:162)
org.apache.spark.sql.Dataset.javaToPython(Dataset.scala:3569)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:498)
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
py4j.Gateway.invoke(Gateway.java:295)
py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
py4j.commands.CallCommand.execute(CallCommand.java:79)
py4j.GatewayConnection.run(GatewayConnection.java:251)
And then the actual job:

Any idea why this happens and how I can prevent the first job to run and only run the actual code?
I've confirmed that in the first pass, none of the code in the foreachPartitions runs.
Using .cache() is not recommended for real world scenarios because the datasets are large and would take even longer to persist than to execute the job again (possibly failing on disk availability).
One thing this shows is that it looks related to databricks' RemoteServiceExec code. Maybe its unknowingly causing the dataset/rdds to be materialized?
Anyone can help?
Thanks
Labels:
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2021 06:28 AM
I've also confirmed this doesn't happen in vanilla spark in local mode. Nor does it happen when running the same code directly in a databricks notebook.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-20-2021 03:09 AM
A community forum to discuss working with Databricks Cloud and Spark. ... Double job execution caused by databricks' RemoteServiceExec using databrick.
MyBalanceNow
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-20-2021 06:31 AM
I don't understand your comment. This only happens in Databricks cloud.



{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.