Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Why is Spark creating multiple jobs for one action...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Why is Spark creating multiple jobs for one action?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2021 05:33 AM
I noticed that when launching this bunch of code with only one action, I have three jobs that are launched.
from pyspark.sql import DataFrame from pyspark.sql.types import StructType, StructField, StringType from pyspark.sql.functions import avgdata: List = [("Diamant_1A", "TopDiamant", "300", "rouge"), ("Diamant_2B", "Diamants pour toujours", "45", "jaune"), ("Diamant_3C", "Mes diamants préférés", "78", "rouge"), ("Diamant_4D", "Diamants que j'aime", "90", "jaune"), ("Diamant_5E", "TopDiamant", "89", "bleu") ]schema: StructType = StructType([ \ StructField("reference", StringType(), True), \ StructField("marque", StringType(), True), \ StructField("prix", StringType(), True), \ StructField("couleur", StringType(), True) ])dataframe: DataFrame = spark.createDataFrame(data=data,schema=schema)dataframe_filtree:DataFrame = dataframe.filter("prix > 50")dataframe_filtree.show()From my understanding, I should get only one. One action corresponds to one job.
I don't know why I have 3 jobs.
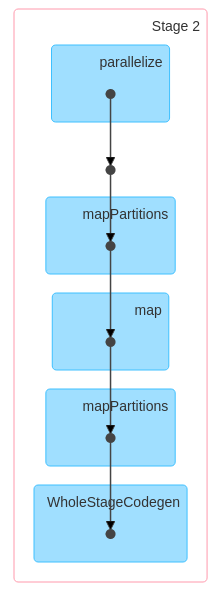
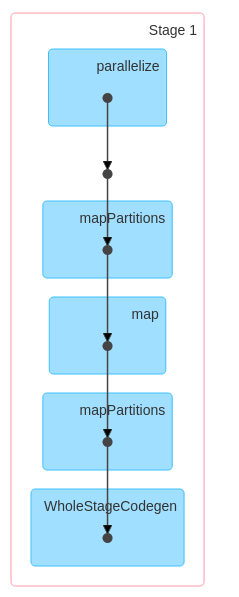
Here is the first one :

Here is the second one :


3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-02-2021 05:56 AM
Hi @ Nastasia! My name is Kaniz, and I'm a technical moderator here. Great to meet you, and thanks for your question! Let's see if your peers on the Forum have an answer to your questions first. Or else I will follow up shortly with a response.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-18-2023 09:34 AM
I am very curious about this. Any answer?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-19-2023 01:33 PM
The above code will create two jobs.
JOB-1. dataframe: DataFrame = spark.createDataFrame(data=data,schema=schema)
The createDataFrame function is responsible for inferring the schema from the provided data or using the specified schema.Depending on the data source, this might involve reading a small sample of the data to infer the schema correctly.This operation might be triggered lazily but can sometimes cause Spark to execute certain tasks immediately.
So, in practical terms, while createDataFrame is usually considered a transformation, there might be scenarios,
especially with certain data sources, where it involves internal actions for schema inference
JOB-2. dataframe_filtree.show()
Announcements




{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Add Visualization in Notebook to Dashboard, how to set default add to Dashboard Bottom in Warehousing & Analytics
- Connect Timeout - Error when trying to run a cell in Data Engineering
- Operations on Unity Catalog take too long in Administration & Architecture
- Shared job clusters on Azure Data Factory ADF in Data Engineering
- Custom JobGroup in Spark UI for cluster with multiple executions in Data Engineering