Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Delete row from table is not working.
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-12-2021 11:54 PM
I have created External table using spark via below command. (Using Data science & Engineering)
df.write.mode("overwrite").format("parquet").saveAsTable(name=f'{db_name}.{table_name}', path="dbfs:/reports/testing")I have tried to delete a row based on filter condition using SQL endpoint (Using SQL )
DELETE FROM
testing.mobile_number_table
WHERE
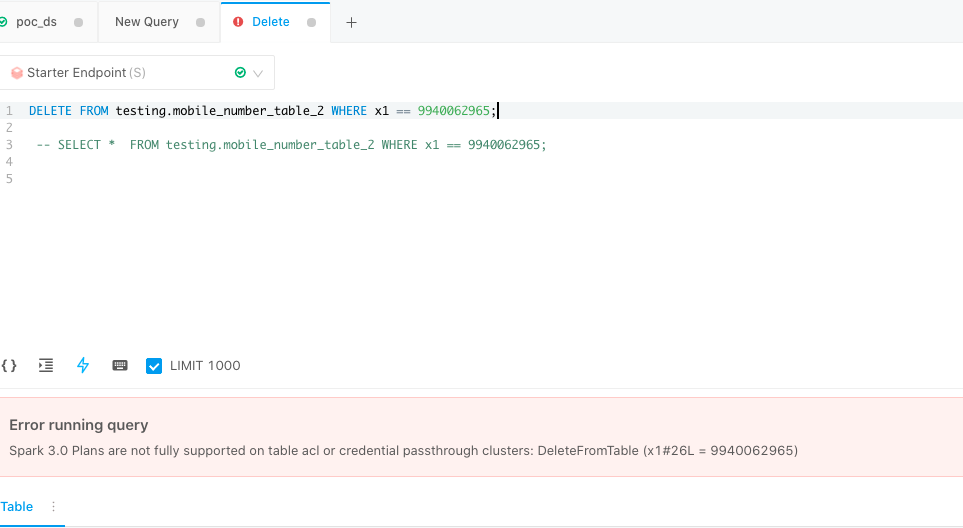
x1 == 9940062964Getting below error message.
Spark 3.0 Plans are not fully supported on table acl or credential passthrough clusters: DeleteFromTable (x1#6341L = 9940062964)
Labels:
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-13-2021 02:38 AM
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-13-2021 02:38 AM
try using :
.format("delta")if not help I would check dbfs mount
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2021 12:05 AM
Hi @Hubert Dudek , Is this(delta) is the only way for updating & deleting records.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2021 03:34 AM
using delta file format is only ("real") way to delte smth from file as it is transaction file (so it make commit that record is deleted kind of sql/git)
In other data files it will require to overwrite everything every time.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-13-2021 05:55 AM
Thank you.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-13-2021 10:41 AM
if helped you can choose my answer as best one 🙂
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-13-2021 10:46 AM
hi @karthick J ,
It seems like the error is coming from your table permissions. Are you using a high concurrency cluster? if you do, then check if have table ACLs enable. Also try to test it using a standard cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2021 11:28 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2021 02:48 PM
hi @karthick J ,
Can you try to delete the row and execute your command in a non high concurrency cluster? the reason why im asking this is because we first need to isolate the error message and undertand why is happening to be able to find the best solution. Is this issue still blocking you or you are able to mitigate/solve this error?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 12:01 AM
HI @Jose Gonzalez ,
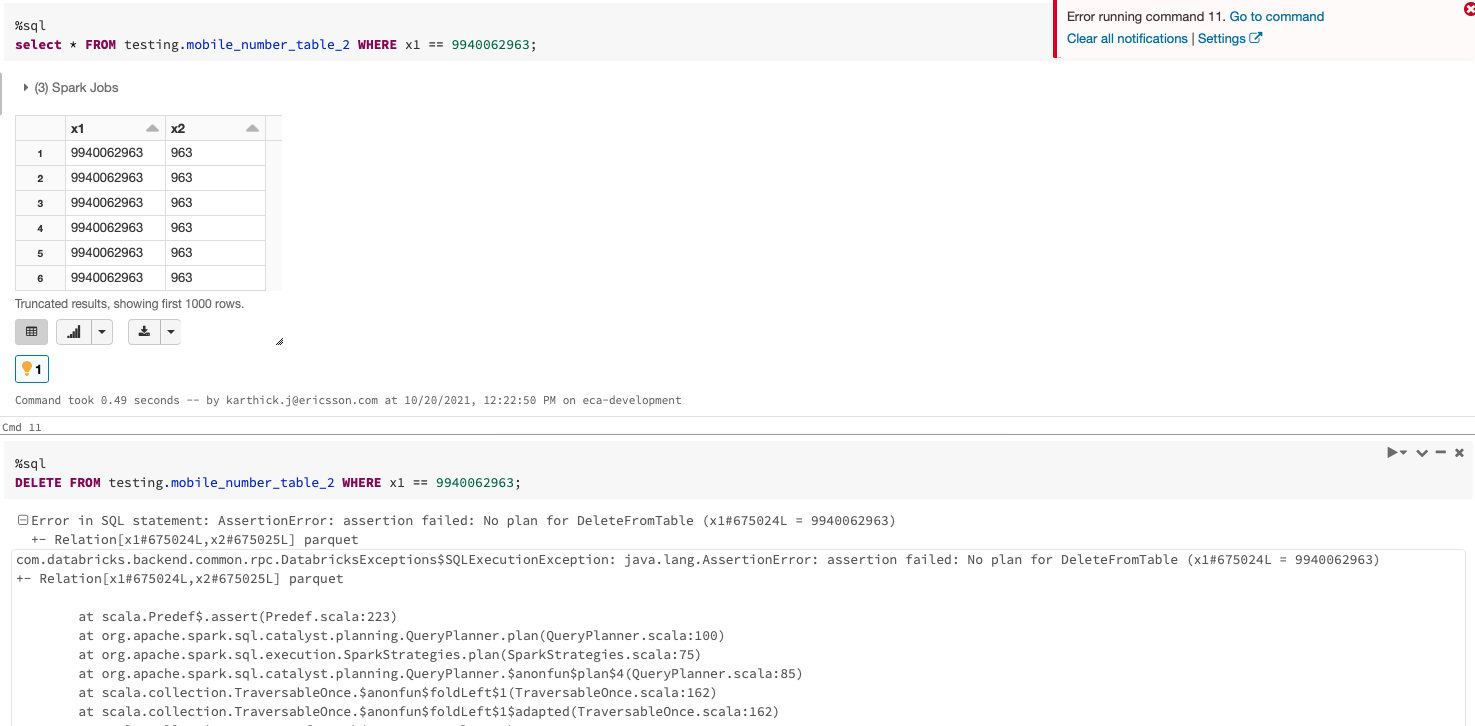
Have created a table via spark using non high concurrency cluster - not writing as delta format. And created the table via spark. Where I have tried to delete the row but getting the error 1. Via Spark Notebook SQL & 2. SQL query
df.write.mode("overwrite").format("parquet").saveAsTable(name=f'{db_name}.{table_name}', path="dbfs:/reports/testing")




{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Unity Catalog table management with multiple teams members in Machine Learning
- Liquid Clustering With Merge in Data Engineering
- Delta Live table expectations in Data Engineering
- Delta Live Table : [TABLE_OR_VIEW_ALREADY_EXISTS] Cannot create table or view in Data Engineering
- Seeing history even after vacuuming the Delta table in Data Engineering