Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- java.lang.OutOfMemoryError: GC overhead limit exce...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2021 09:51 PM
solution :-
i don't need to add any executor or driver memory all i had to do in my case was add this : - option("maxRowsInMemory", 1000).
Before i could n't even read a 9mb file now i just read a 50mb file without any error.
{
val df = spark.read
.format("com.crealytics.spark.excel").
option("maxRowsInMemory", 1000).
option("header", "true").
load("data/12file.xlsx")
}
I am trying to read a 8mb excel file,
i am getting this error.
i use intellij with spark 2.4.4
scala 2.12.12
and jdk 1.8
this is my code : -
val conf = new SparkConf()
.set("spark.driver.memory","4g")
.set("spark.executor.memory", "6g")
// .set("spark.executor.cores", "2")
val spark = SparkSession
.builder
.appName("trimTest")
.master("local[*]")
.config(conf)
.getOrCreate()
val df = spark.read
.format("com.crealytics.spark.excel").
option("header", "true").
load("data/12file.xlsx")
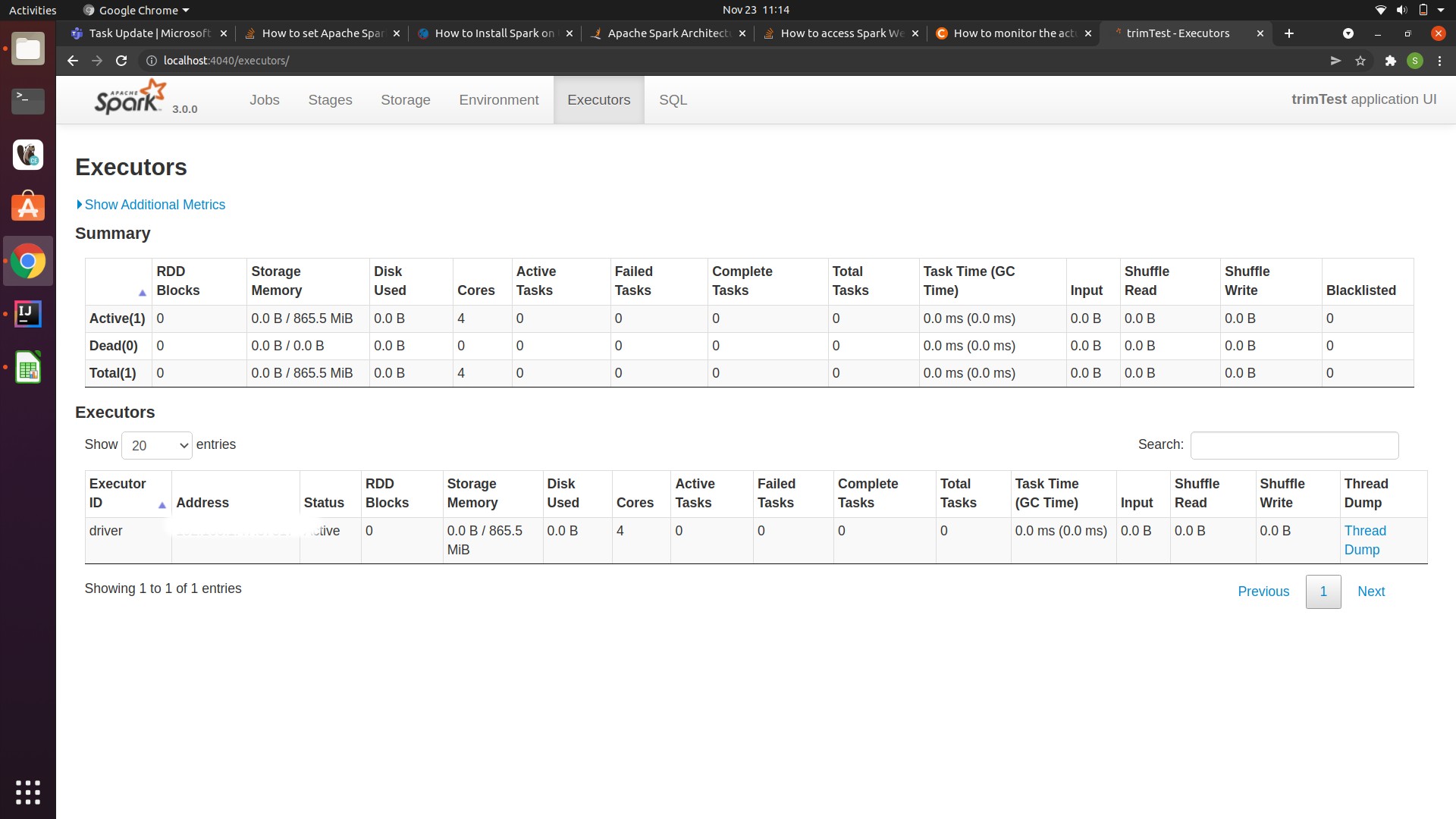
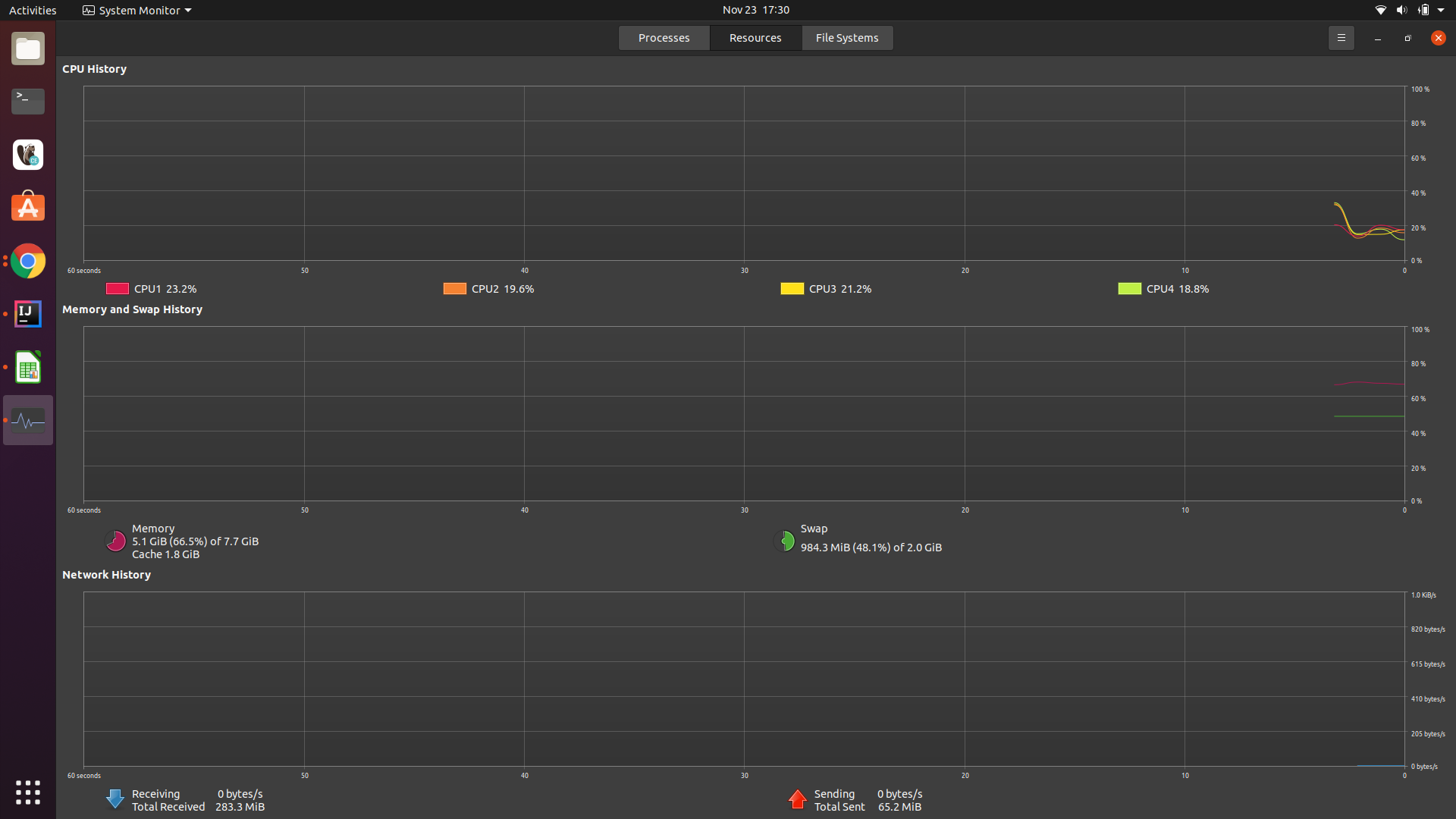
Now, these are my spark ui screenshots,
can you tell me what is the main issue and how can i increase the job executor memory.


stack :-
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Class.newReflectionData(Class.java:2511)
at java.lang.Class.reflectionData(Class.java:2503)
at java.lang.Class.privateGetDeclaredConstructors(Class.java:2660)
at java.lang.Class.getConstructor0(Class.java:3075)
at java.lang.Class.newInstance(Class.java:412)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:403)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:394)
at java.security.AccessController.doPrivileged(Native Method)
at sun.reflect.MethodAccessorGenerator.generate(MethodAccessorGenerator.java:393)
at sun.reflect.MethodAccessorGenerator.generateMethod(MethodAccessorGenerator.java:75)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:53)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.reflect.misc.MethodUtil.invoke(MethodUtil.java:276)
at com.sun.jmx.mbeanserver.ConvertingMethod.invokeWithOpenReturn(ConvertingMethod.java:193)
at com.sun.jmx.mbeanserver.ConvertingMethod.invokeWithOpenReturn(ConvertingMethod.java:175)
at com.sun.jmx.mbeanserver.MXBeanIntrospector.invokeM2(MXBeanIntrospector.java:117)
at com.sun.jmx.mbeanserver.MXBeanIntrospector.invokeM2(MXBeanIntrospector.java:54)
at com.sun.jmx.mbeanserver.MBeanIntrospector.invokeM(MBeanIntrospector.java:237)
at com.sun.jmx.mbeanserver.PerInterface.getAttribute(PerInterface.java:83)
at com.sun.jmx.mbeanserver.MBeanSupport.getAttribute(MBeanSupport.java:206)
at javax.management.StandardMBean.getAttribute(StandardMBean.java:372)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getAttribute(DefaultMBeanServerInterceptor.java:647)
at com.sun.jmx.mbeanserver.JmxMBeanServer.getAttribute(JmxMBeanServer.java:678)
at com.sun.jmx.mbeanserver.MXBeanProxy$GetHandler.invoke(MXBeanProxy.java:122)
at com.sun.jmx.mbeanserver.MXBeanProxy.invoke(MXBeanProxy.java:167)
at javax.management.MBeanServerInvocationHandler.invoke(MBeanServerInvocationHandler.java:258)
at com.sun.proxy.$Proxy8.getMemoryUsed(Unknown Source)
at org.apache.spark.metrics.MBeanExecutorMetricType.getMetricValue(ExecutorMetricType.scala:67)
at org.apache.spark.metrics.SingleValueExecutorMetricType.getMetricValues(ExecutorMetricType.scala:46)
at org.apache.spark.metrics.SingleValueExecutorMetricType.getMetricValues$(ExecutorMetricType.scala:44)
at org.apache.spark.metrics.MBeanExecutorMetricType.getMetricValues(ExecutorMetricType.scala:60)
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2021 03:12 AM
Thank You i just found a solution, and i have mentioned it in my question to, while reading my file all i had to do was add this,
option("maxRowsInMemory", 1000).
18 REPLIES 18
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2021 11:05 PM
I doubt it is the 8 MB file.
What happens if you do not set any memory parameter at all? (use the defaults)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2021 11:40 PM
it is an 8.5 mb xlsx file with 100k rows of data,
i get the same gc overhead limit exceeded error without addin any parameter
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2021 11:56 PM
My guess is indeed a config issue as in your spark script you don't seem to do any action (spark is lazy evaluated).
As you run Spark locally, chances are the JVM cannot allocate enough RAM for it to run succesfully.
Can you check the docs:
https://spark.apache.org/docs/2.4.4/tuning.html#garbage-collection-tuning
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 12:44 AM
yes i just went through it, and from what i understood i need to increase the heap space, but increasing it at run time with intellij is not working.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 01:02 AM
can you try with local[2] instead of local[*]?
And also beef up the driver memory to like 90% of your RAM.
As you run in local mode, the driver and the executor all run in the same process which is controlled by driver memory.
So you can skip the executor params.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 01:38 AM
i did it is still the same, there is something else that i am missing here, and my memory consumed was 7gb out of 8gb available right now.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 01:44 AM
you don't do anything else but the spark.read.excel, right?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 02:15 AM
i am doing df.show(),
nothing else
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 02:18 AM
weird, when I run spark locally, I just install it, do not configure any executor and it just works.
Did you define any executors by any chance?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 02:49 AM
no i did n't i have also just installed it, i think this is my machines issue or something which i have not done right.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 03:07 AM
can you try without:
.set("spark.driver.memory","4g")
.set("spark.executor.memory", "6g")
It is clearly show that there is no 4gb free on driver and 6gb free on executor (you can share hardware cluster details also).
You can not also allocate 100% for spark usually as there is also other processes.
Automatic settings are recommended.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 04:00 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 04:50 AM
It seems that you have only 8GB ram (probably 4-6 GB is needed for system at least) but you allocate 10GB for spark (4 GB driver + 6 GB executor).
You can allocate max in my opinion 2GB all together if your RAM is 8 GB. Maybe even 1GB as there can be also spikes in system processes.
Easier would be with docker as than you allocate your machine permanent number of ram and than spark can consume exact amount.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2021 05:28 AM
Yea that will be it. 8GB can run spark, but I'd go for no more than 3GB, 2GB on the safe side.
It looks like an ubuntu install so that is not as resource hungry than windows but 8GB is not much.
For tinkering around, I always go for Docker (or a VM).



{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- GCP - (DWH) Cluster Start-up Delayed - Failing to start in Administration & Architecture
- Volume Limitations in Data Engineering
- DatabricksThrottledException Error in Data Engineering
- Monitor and Alert Databricks Resource Utilization and Cost Consumption in Administration & Architecture
- Performance Issues with Unity Catalog in Data Engineering