Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Is there a way to capture the notebook logs from A...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 12:37 AM
Hi,
I would like to capture notebook custom log exceptions(python) from ADF pipeline based on the exceptions pipeline should got succeed or failed.
Is there any mechanism to implement it. In my testing ADF pipeline is successful irrespective of the log errors.
Notebook always returns SUCCESS do adf's activity, even exception is raised in notebook.If a notebook contains any exceptions then adf pipeline which contains that particular notebook activity should fail
Thank you
Labels:
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 01:45 AM
Thank you for your response.
My question is not to store/get the log info.
My scenario is like:
Notebook always returns SUCCESS do adf's activity, even exception is raised in notebook.If a notebook contains any exceptions then adf pipeline which contains that particular notebook activity should fail.
10 REPLIES 10
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 01:20 AM
Hi @Sailaja B the notebook errors will be tracked in the driver log4j output. You can check the cluster's driver logs to get this information. Or you can set logging to your cluster so that all the messages will be logged in the dbfs or storage path that you provide.
Please refer to the document.
https://docs.databricks.com/clusters/configure.html#cluster-log-delivery-1
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 01:45 AM
Thank you for your response.
My question is not to store/get the log info.
My scenario is like:
Notebook always returns SUCCESS do adf's activity, even exception is raised in notebook.If a notebook contains any exceptions then adf pipeline which contains that particular notebook activity should fail.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 02:08 AM
Hi @Sailaja B notebook/job fails to happen when there is really a failure. Some exceptions are information that might not hurt the running notebook. To understand better, please share the exception that you see in the notebook output.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 02:18 AM
Here is the sample code
if not any(mount.mountPoint == "/test/" for mount in dbutils.fs.mounts()):
dbutils.fs.mount(source = "***",
mount_point = "/test/",
extra_configs = configs)
else:
logger.error("Directory is already mounted")
Note : Mount path is already existed.. If I run this notebook through ADF pipeline, I am expecting that pipeline should fails but it is not getting failed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 10:42 AM
Hi @Sailaja B ,
You will beed to raise/throw the error exception to stop your Spark execution. Try to use a try..catch statement block handle your custom exceptions.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2021 11:40 PM
Hi @Jose Gonzalez ,
Thank you for your reply..
It is working as expected with try .. exception..assert False..
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-07-2022 01:36 AM
Hi @Sailaja B Is it working now?I mean, Is pipeline showing failure when notebook failed.If yes please share a sample snippet?(I am also trying the same case .I am able capture logs from pipeline side using output Json but couldn't modify pipeline status)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 01:23 AM
Next to the mentioned option, there is also the possibility to analyze logs using Azure Log Analytics:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 02:32 AM
Also when you catch exception you can just save it anywhere even to Databricks Table something like:
try:
(...)
except Exception as error:
spark.sql(f"""INSERT INTO (...) """", repr(error))
dbutils.notebook.exit(str(jobId) + ' - ERROR!!! - ' + repr(error))In my opinion as @werners said is good choice to send to Azure Log Analytics for detailed analysis but I like also to use also above method and just have nice table in databricks with jobs which failed 😉
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-21-2021 10:50 PM
Hi SailajaB,
Try this out.
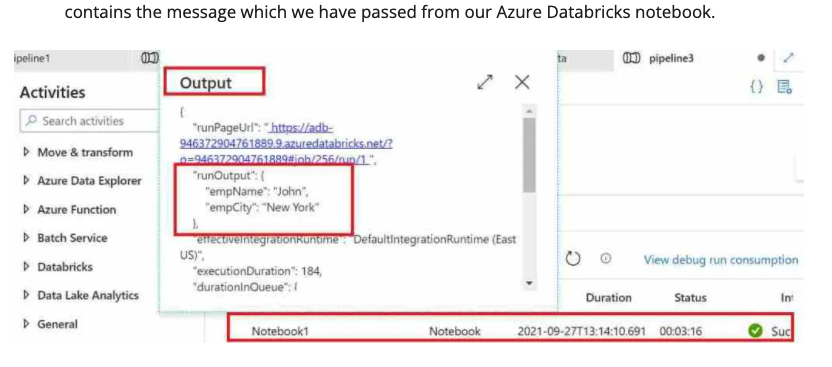
Notebook, once executed successfully return a long JSON formatted output. We need to specify appropriate nodes to fetch the output.
In below screenshot we can see that when notebook ran it returns empName & empCity as output.

- In respective pipeline, add a VARIABLE (to capture output of NOTEBOOK Task)
- Add a SET VARIABLE activity and use VARIABLE defined in above step and add below expression:
@activity(''YOUR NOTEBOOK ACTIVITY NAME').output.runOutput.an_object.name.value
- Add link between NOTEBOOK ACTIVITY and SET VARIABLE ACTIVITY
- Run your pipeline and you should see the output captured in this variable
Note: If you want to specify custom return value then you need to use :
dbutils.notebook.exit('VALUE YOU WANT TO RETURN')
Let me know how it goes.
Cheers
GS
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- DLT Pipeline Error Handling in Data Engineering
- Variables passed from ADF to Databricks Notebook Try-Catch are not accessible in Data Engineering
- One-time backfill for DLT streaming table before apply_changes in Data Engineering
- Addressing Pipeline Error Handling in Databricks bundle run with CI/CD when SUCCESS WITH FAILURES in Data Engineering
- Move files in Data Engineering