Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- How do you use cloud fetch?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2021 08:22 AM
We're trying to pull a big amount of data using databricks sql and seem to have a bottleneck on network throughput when fetching the data.
I see there's a new feature called cloud fetch and this seems to be the perfect solution for our issue. But I don't see any documentation on how to use this feature.
Labels:
- Labels:
-
Azure databricks
-
Cloud
-
Cloud Fetch
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2021 08:37 AM
Clud fetch is architecture inside ODBC driver. To use it you need just latest ODBC driver https://databricks.com/blog/2021/08/11/how-we-achieved-high-bandwidth-connectivity-with-bi-tools.htm...
Big amount in sql what exactly is big? Maybe some partitioning, multi cluster and some load in chunks could help.
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2021 08:37 AM
Clud fetch is architecture inside ODBC driver. To use it you need just latest ODBC driver https://databricks.com/blog/2021/08/11/how-we-achieved-high-bandwidth-connectivity-with-bi-tools.htm...
Big amount in sql what exactly is big? Maybe some partitioning, multi cluster and some load in chunks could help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2021 09:12 AM
Is there any way we confirm it's using cloud fetch?
I'm not sure what's the exact size, but it's up to 100s of GB of data across multiple queries.
Looking at the metrics from the VM that's executing the query, the max throughput is 60MBps
It doesn't seem to match the throughput seen in the document. It's closer to the Baseline with single threaded. I'm using 2.6.19 ODBC driver
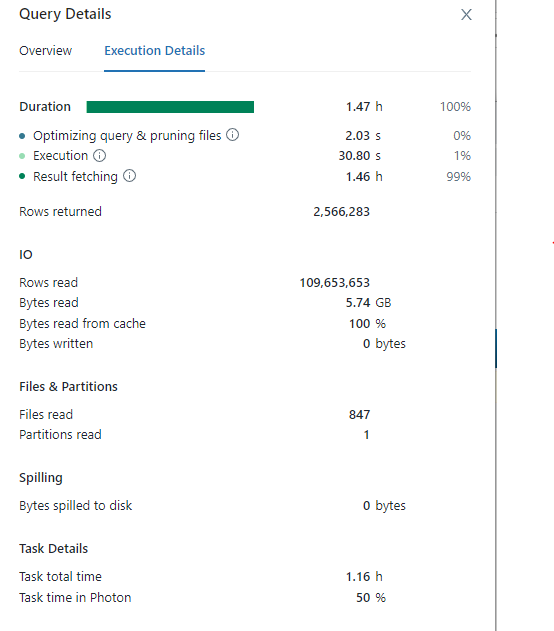
Here's sample execution details for one query

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-24-2022 04:09 AM
Hi @Aldrich Ang , The ODBC driver version 2.6.17 and above supports Cloud Fetch, a capability that fetches query results through the cloud storage set up in your Azure Databricks deployment.
To extract query results using this format, you need Databricks Runtime 8.3 or above.
Query results are uploaded to an internal DBFS storage location as arrow-serialized files of up to 20 MB. Azure Databricks generates and returns shared access signatures to the uploaded files when the driver sends fetch requests after query completion. The ODBC driver then uses the URLs to download the results directly from DBFS.
Cloud Fetch is only used for query results more significant than 1 MB. More minor effects are retrieved directly from Azure Databricks.
Azure Databricks automatically collects the accumulated files marked for deletion after 24 hours. These marked files are wholly deleted after an additional 24 hours.
To learn more about the Cloud Fetch architecture, see How We Achieved High-bandwidth Connectivity With BI Tools.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2021 12:13 AM
Trying to get an idea of what you are trying:
so you query directly on a database of +100GB or is it parquet/delta source?
Also, where is the result fetched to? File download, BI tool, ...?



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Ephemeral storage how to create/mount. in Data Engineering
- Job stuck while utilizing all workers in Data Engineering
- Use OF API from package enerbitdso 0.1.8 PYPI in Machine Learning
- Differences between Spark SQL and Databricks in Data Engineering
- Understand why your jobs' performances are changing over time in Data Engineering