Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- To read data from Azure Storage
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 12:45 AM
Hi Team,
May i know how to read Azure storage data in Databricks through Python.
Labels:
- Labels:
-
Azure
-
Azure Storage
-
AzureStorage
-
Read
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2022 04:00 AM
Hi @Bhagwan Chaubey , Once you've uploaded your files to your blob container,
Step 1: Get credentials necessary for databricks to connect to your blob container
From your Azure portal, you need to navigate to all resources then select your blob storage account and from under the settings select account keys. Once there, copy the key under Key1 to a local notepad.
Step 2: Configure DataBricks to read the file
To start reading the data, first, you need to configure your spark session to use credentials for your blob container. This can simply be done through the spark.conf.set command.
storage_account_name = 'nameofyourstorageaccount'
storage_account_access_key = 'thekeyfortheblobcontainer'
spark.conf.set('fs.azure.account.key.' + storage_account_name + '.blob.core.windows.net', storage_account_access_key)Once done, we need to build the file path in the blob container and read the file as a Spark data frame.
blob_container = 'yourblobcontainername'
filePath = "wasbs://" + blob_container + "@" + storage_account_name + ".blob.core.windows.net/Sales/SalesFile.csv"
salesDf = spark.read.format("csv").load(filePath, inferSchema = True, header = True)And congrats, we are done.
You can use the display command to have a sneak peek at our data.
Below is a snapshot of my code.

18 REPLIES 18
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 01:21 AM
Hi @ bchaubey! My name is Kaniz, and I'm the technical moderator here. Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else I will get back to you soon. Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 04:44 AM
Hi @Bhagwan Chaubey , You can access your files using python through the below-mentioned code.
#Once you've mounted a Blob storage container or a folder inside a container through the code:-
dbutils.fs.mount(
source = "wasbs://<container-name>@<storage-account-name>.blob.core.windows.net",
mount_point = "/mnt/<mount-name>",
extra_configs = {"<conf-key>":dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>")})
#read the csv data
df = spark.read.csv("dbfs:/mnt/%s/...." % <name-of-your-mount>)
display(df)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 05:15 AM
@Kaniz Fatma how can find value of mountPoint = "/mnt/<mount-name>"
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 05:32 AM
Hi @Bhagwan Chaubey ,
<mount-name> is a DBFS path representing where the Blob storage container or a folder inside the container (specified in the source) will be mounted in DBFS.
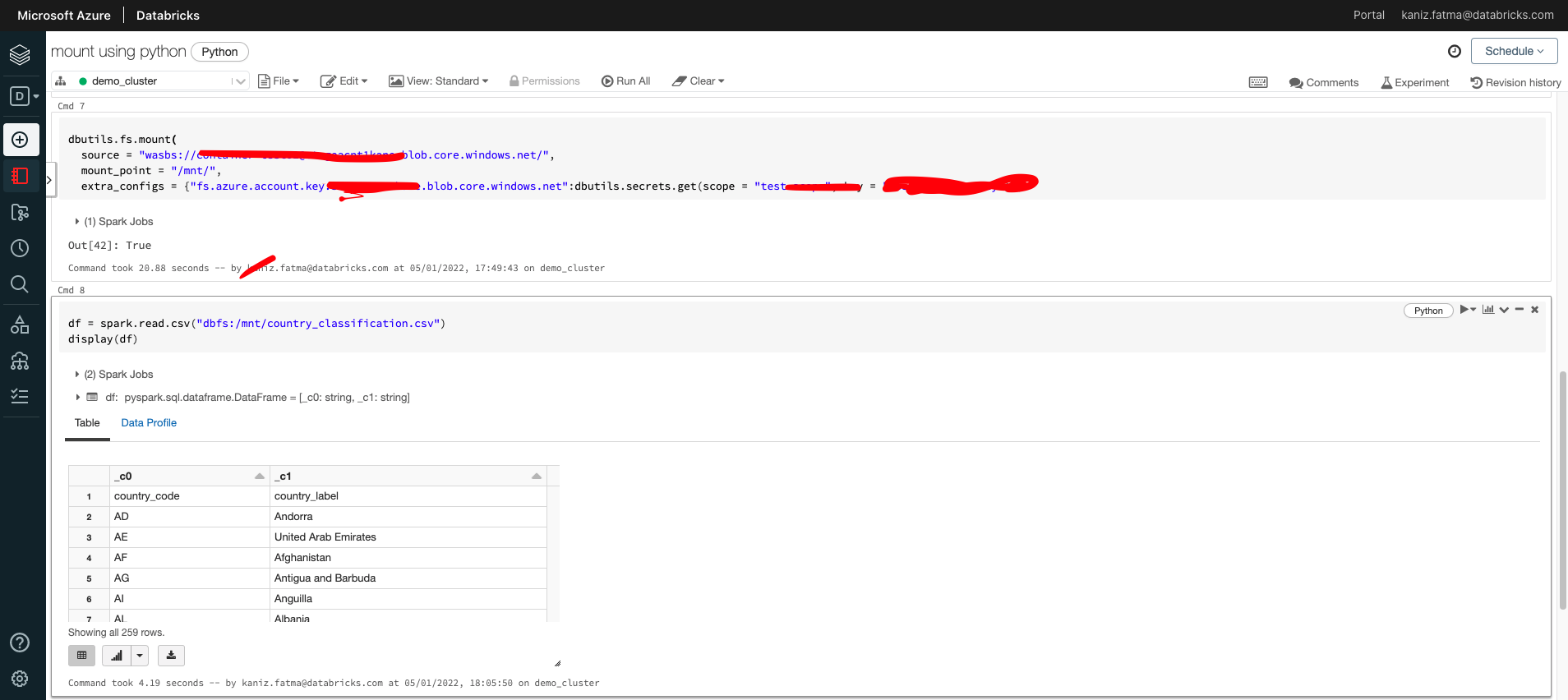
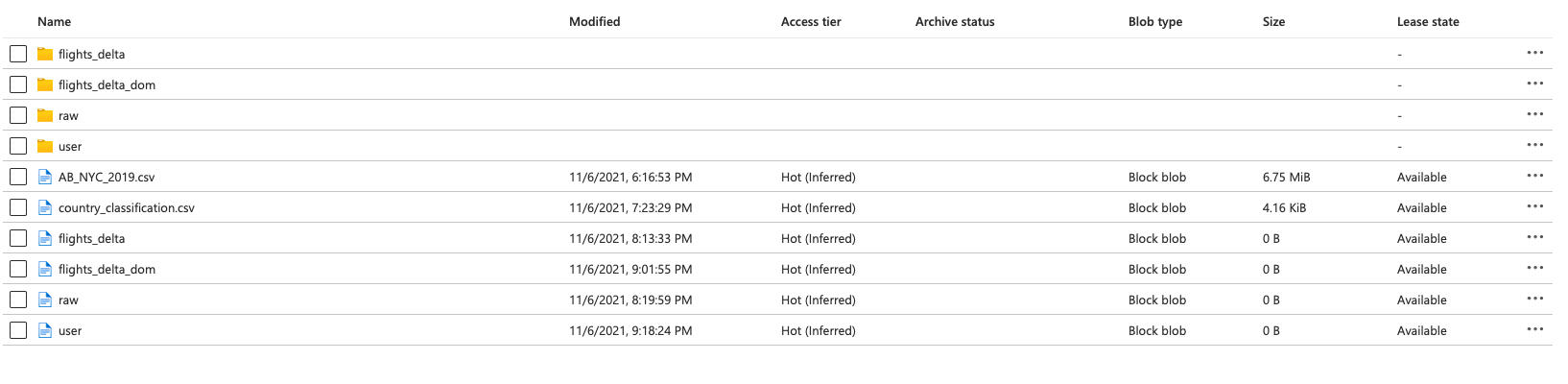
Have you created any folders inside your blob containers? If not, your mount point will be simply - "dbfs:/mnt/dataset.csv"
As you can see in the screenshot below:-
If I want to read my country_classification.csv file, in my case the mount point will be "dbfs:/mnt/country_classification.csv" as I've not created any folder or directory inside my blob.


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 05:56 AM
%scala
df = spark.read.csv("dbfs:/mnt/country_classification.csv")
display(df)
may i know how can find dbfs:/mnt
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 06:03 AM
Hi @Bhagwan Chaubey , Can you please browse this path in your Microsoft azure:- "storage_account/containers/directory_in_which_you've_uploaded_your_dataset"? That itself will be your mount point.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 06:41 AM
Hi @Kaniz Fatma I am facing issue during read the data. Please see the attachment
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 07:06 AM
Hi @Bhagwan Chaubey , Can you please enter the correct scope and key names in the above code?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2022 07:20 AM
@Kaniz Fatma i have added correct key
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2022 04:02 AM
Hi @Bhagwan Chaubey , There might be a different scope name or any wrong credentials. You need to recheck all the values again. However, I've provided another way to solve your query. Please try and let me know if it works.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2022 04:00 AM
Hi @Bhagwan Chaubey , Once you've uploaded your files to your blob container,
Step 1: Get credentials necessary for databricks to connect to your blob container
From your Azure portal, you need to navigate to all resources then select your blob storage account and from under the settings select account keys. Once there, copy the key under Key1 to a local notepad.
Step 2: Configure DataBricks to read the file
To start reading the data, first, you need to configure your spark session to use credentials for your blob container. This can simply be done through the spark.conf.set command.
storage_account_name = 'nameofyourstorageaccount'
storage_account_access_key = 'thekeyfortheblobcontainer'
spark.conf.set('fs.azure.account.key.' + storage_account_name + '.blob.core.windows.net', storage_account_access_key)Once done, we need to build the file path in the blob container and read the file as a Spark data frame.
blob_container = 'yourblobcontainername'
filePath = "wasbs://" + blob_container + "@" + storage_account_name + ".blob.core.windows.net/Sales/SalesFile.csv"
salesDf = spark.read.format("csv").load(filePath, inferSchema = True, header = True)And congrats, we are done.
You can use the display command to have a sneak peek at our data.
Below is a snapshot of my code.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-07-2022 06:58 AM
Hi @Bhagwan Chaubey , Does this work for you? Do you have any further doubts? Were you able to execute the above commands and get the desired results? Please do let us know If you need help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-07-2022 07:33 AM
@Kaniz Fatma I am using your code. no any error. But data is still not showing
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
a month ago
Kaniz,
I kept getting "org.apache.spark.SparkSecurityException: [INSUFFICIENT_PERMISSIONS] Insufficient privileges:" with the same codes. Do you know why?
Thanks!



{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Unity catalog issues in Data Engineering
- Ephemeral storage how to create/mount. in Data Engineering
- Passing Parameters from Azure Synapse in Data Engineering
- Databricks connecting SQL Azure DW - Confused between Polybase and Copy Into in Data Engineering
- Why does use of Azure SSO require Databricks PAT enabled ? in Administration & Architecture