Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Spark SQL Group by duplicates, collect_list in arr...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Spark SQL Group by duplicates, collect_list in array of structs and evaluate rows in each group.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-01-2022 08:39 AM
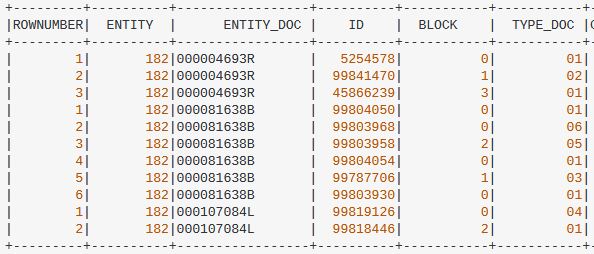
I'm begginner working with Spark SQL in Java API. I have a dataset with duplicate clients grouped by ENTITY and DOCUMENT_ID like this:
.withColumn( "ROWNUMBER", row_number().over(Window.partitionBy("ENTITY", "ENTITY_DOC").orderBy("ID")))
//criteria 1 (the best is the ID with BLOCK 0)
BLOCK = 0 or ' ' VS BLOCK 1, 2 or 3
//criteria 2 (the best is the ID with BLOCK 2)
BLOCK = 2 VS BLOCK 1 or 3
//criteria3 (the best is the ID with BLOCK 3)
BLOCK = 3 VS BLOCK 1
//criteria4 (the best is the one with the most recent timestamp)
BLOCKS 1-1 or BLOCKS 3-3
** if BLOCKS 2-2 OR BLOCKS 0-0 evaluate the following criteria
//criteria5 (the best is ID with typedoc 01, 02, 03, 04 or 07
TYPE DOC 01, 02, 03, 04, 07 VS ANY OTHER
//criteria6 (the best is the one with the most recent timestamp)
TYPE DOC 01, 02, 03, 04, 07 VS TYPE DOC 01, 02, 03, 04, 07Now I have to compare in each group, pairs of rows in order to decide which is the best. This is the big problem, I dont know if its better create an array struct, a map... I dont know how iterate each row inside the same group. An example:
if entity "182" with entity_doc "000004693R" have 3 matches, we have to compare:
First, ROW(1) -> ID 5254578 against ROW(2) ID -> 99841470.
** ROW(1) would be the best because criteria 1.
Following the order, we have to compare the before best ROW(1) -> ID 5254578 VS ROW(3) ID -> 45866239.
** ROW(1) would be the best because criteria 1.
I tried to group each row of the group in a collect_list but I don't know how to access each element to compare it with the next:
root
|-- ENTITY: string (nullable = true)
|-- ENTITY_DOC: string (nullable = true)
|-- COMBINED_LIST: array (nullable = true)
| |-- element: struct (containsNull = false)
| | |-- ID: string (nullable = true)
| | |-- BLOCK: string (nullable = true)
| | |-- TYPE_DOC: string (nullable = true)
| | |-- AUD_TIMESTAM: timestamp (nullable = true)
Example of first group:
+------+-------------------------+--------------------------------------------------------------------------------------
|ENTITY|ENTITY_DOC |COMBINED_LIST
+------+-------------------------+--------------------------------------------------------------------------------------
|182 | 000004693R | [[5254578,0,01, 2005-07-07 01:03:25.613802], [99841470, 1,02, 2005-07-07 01:03:25.613802], [45866239, 3,01, 2000-01-16 09:07:00]] |The output would be a TUPLE with the best ID and the others ID's LIKE:
+----------+-----------------+----------+----------+------------+
| ENTITY | ENTITY_DOC | ID1 | ID2 |COD_CRITERIA|
+----------+-----------------+----------+----------+------------+
| 182|000004693R | 5254578| 99841470| 1|
| 182|000004693R | 5254578| 45866239| 1|Can you help me with Spark? Thanks a lot!
Labels:
5 REPLIES 5
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-01-2022 09:36 AM
Hello, @tusWorten TW! My name is Piper, and I'm a moderator here for Databricks. Welcome to the community and thank you for bringing your question to us. Let's give the community a chance to respond and then we will come back if we need to.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-01-2022 10:36 AM
In my opinion you took good direction as grouping collect_list (generally array or map) is way to go.
You need to write function to compare that elements and register as user defined function. You can even use multiple columns with arrays and pass them to function and return what you need. Function can handle any logic just with if and else.
Here is example code from internet used to compare two arrays. You can find many examples by searching for "spark udfs":
import scala.collection.mutable.WrappedArray
import org.apache.spark.sql.functions.col
val same_elements = udf { (a: WrappedArray[String],
b: WrappedArray[String]) =>
if (a.intersect(b).length == b.length){ 1 }else{ 0 }
}
df.withColumn("test",same_elements(col("array1"),col("array2")))Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2022 07:23 AM
Hi @tusWorten TW , Did @Hubert Dudek 's answer help you?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2022 07:31 AM
Hi @Kaniz Fatma
Her answer didn't solve my problem but it was useful to learn more about UDFS, which I did not know.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2022 07:35 AM
Thank you @tusWorten TW for your response. I'll try to bring a helpful answer to you soon.



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.