Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Simply writing a dataframe to a CSV file (non-part...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 10:37 PM
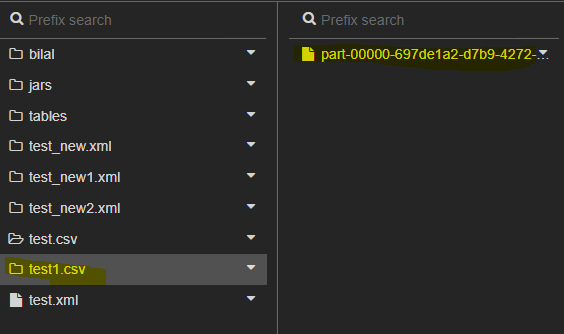
When writing a dataframe in Pyspark to a CSV file, a folder is created and a partitioned CSV file is created. I have then rename this file in order to distribute it my end user.
Is there any way I can simply write my data to a CSV file, with the name I specified, and have that single file in the folder I specified ?
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 11:26 PM
it will always write to a folder due to the parallel nature of spark.
If that is an issue, you can use magic command %sh to move the .csv file a level up and also rename it.
So use the 'mv' command.
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 11:13 PM
yes, but you have to do a coalesce(1). This will generate a single csv file, however you will also lose some parallelism as this coalesce(1) is propagated upstream.
Also do not forget to disable the writing of _SUCCESS etc files (see this topic)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 11:20 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 11:26 PM
it will always write to a folder due to the parallel nature of spark.
If that is an issue, you can use magic command %sh to move the .csv file a level up and also rename it.
So use the 'mv' command.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2022 01:56 AM
The csv file will have random name, can you show me how you will rename it without going into hassel of copying its name?
For example lets say name of root folder is Main, inside main i wrote csv using coalsce(1) and the structure is Main/data.csv/RandomBigName-part-00000xyz.csv
Now i want to move csv file inside Main folder and lets say name it as dummyData.csv... So final structure which i want is Main/dummyData.csv
Please help
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2024 09:41 AM
Could you please provide an example of using %sh or mv to move and rename the csv?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 11:28 PM
Thanks for confirming that that's the only way 🙂
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- RocksDB results in empty stream/stream joins dataframe in Data Engineering
- how to stop dataframe with federated table source to be reevaluated when referenced (cache?) in Data Engineering
- Using managed identities to access SQL server - how? in Data Engineering
- Custom ENUM input as parameter for SQL UDF? in Data Engineering
- Performance Issue with XML Processing in Spark Databricks in Data Engineering