Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Lost memory when using dbutils
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 07:34 AM

1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 08:38 PM
@James Smith You can reach out to Michael.Dibble@guycarp.com or please follow this doc;
17 REPLIES 17
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 07:40 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 07:56 AM
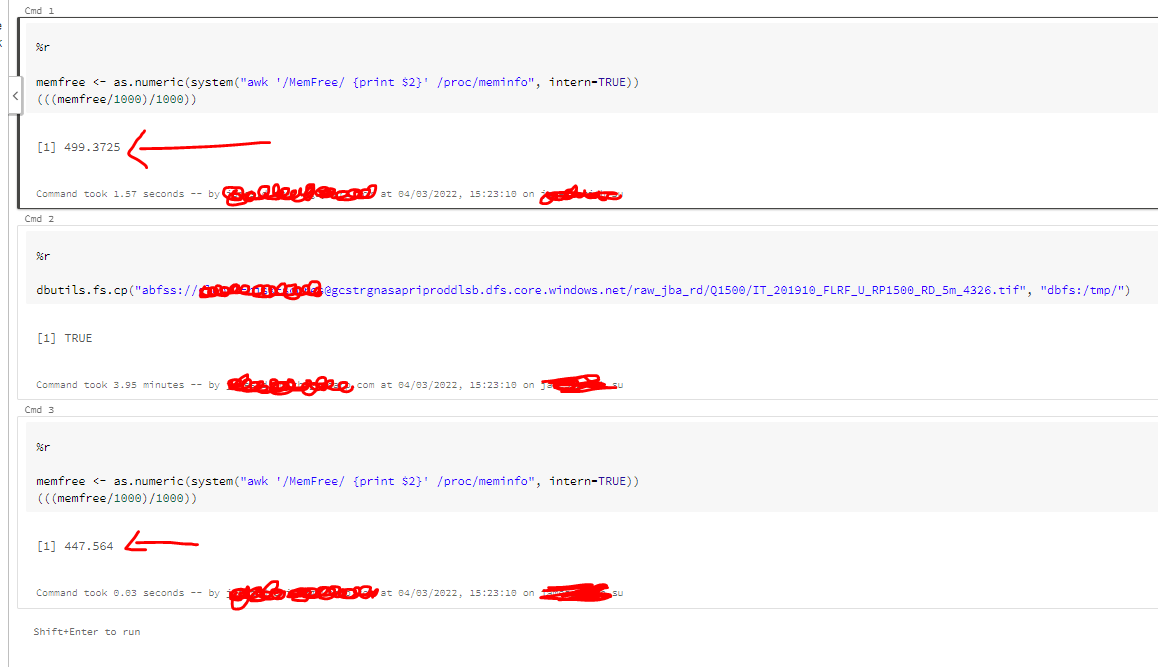
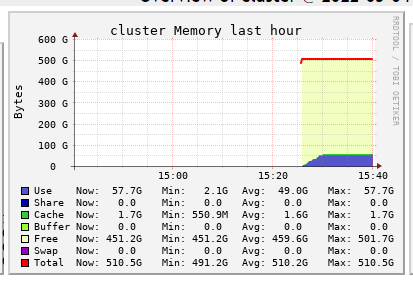
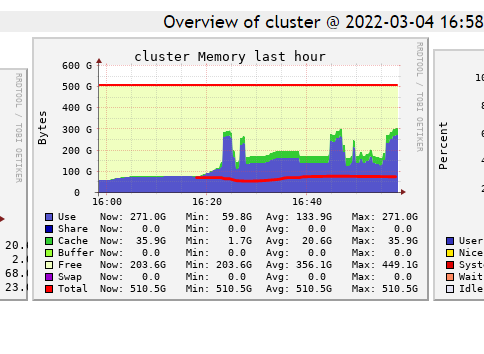
I guess when is read from one directory is copied to RAM and than from there save it in another place (there are also concurrent reads, writes etc. so probably because of that it consume more space). As cluster still have many free memory it wasn't cleaned automatically. You can try to force clean it by using spark.catalog.clearCache()
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 08:12 AM
Thanks for the ideas/suggestion. Unfortunately doing spark.cataglog.clearCache() does not return the memory / clean it.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 09:01 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-11-2022 08:57 AM
Hi @James Smith , This link perhaps might help you in this issue.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-11-2022 09:16 AM
Hi Fatma. The article says:
"The Delta cache works for all Parquet files and is not limited to Delta Lake format files. The Delta cache supports reading Parquet files in .... ...... It does not support other storage formats such as CSV, JSON, and ORC.
I am copying tif files from a Azure Data Lake Storage Gen2 to the /dbfs/ usin dbutils.fs.cp command. So I don't think that the article is relevant is it?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 03:10 AM
Acknowledged.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 08:57 AM
@James Smith
The current implementation of dbutils.fs is single-threaded, meaning that regardless of whether it’s executed on the driver or inside a Spark job, it will perform recursive operations in a single-threaded loop.
The current implementation performs the initial listing on the driver and subsequently launches a Spark job to perform the per-file operations.
So the memory will definitely be in use, but the thing is the unreferenced objects should be cleaned up. Else this would cause the heap to pile up (memory leak).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 09:06 AM
Hi @Rajeev Kumar . I understand why memory is used during the transfer of the file. But should the memory not be returned after the file has been moved? I do not understand why this does not happen?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 09:13 AM
Did the GC cycle happen after the cp command? The memory will be reclaimed based on the requirement for the new coming objects. We do not explicitly clean any memory.. it is taken care by the JVM.
and yes ideally it should, the unreferenced objects are to be cleared during GC.
If this is not happening then there might me some memory leak issue.
We can run an inti script to collect heap dump of driver and executor then we can show the objects occupying most of the memory and then can act accordingly.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 09:52 AM
"Did the GC cycle happen after the cp command?"
How would I know if this happened or not?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 09:16 AM
@James Smith please file a case if you can.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 09:53 AM
Can you tell me how to do that please? I have not done it before.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2022 10:25 AM
You can file it to Azure. And they will reach out to us.
Announcements





{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Cached Views in MERGE INTO operation in Data Engineering
- how to stop dataframe with federated table source to be reevaluated when referenced (cache?) in Data Engineering
- I have to run the notebook in concurrently using process pool executor in python in Data Engineering
- Performance Issue with XML Processing in Spark Databricks in Data Engineering
- Optimal Cluster Configuration for Training on Billion-Row Datasets in Machine Learning