Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- How to efficiently process a 50Gb JSON file and st...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to efficiently process a 50Gb JSON file and store it in Delta?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-04-2022 02:38 PM
Hi, I'm a fairly new user and I am using Azure Databricks to process a ~50Gb JSON file containing real estate data. I uploaded the JSON file to Azure Data Lake Gen2 storage and read the JSON file into a dataframe.
df = spark.read.option('multiline', 'true').json('dbfs:/mnt/data/delta/bronze/BBR_Actual_Totals.json')The schema for the JSON file is the following, but because there are many attributes in each nested JSON structure, I only added the name of the first attribute and the extra number of attributes in each nested JSON.
root
|-- BBRSagList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- forretningshændelse: string (nullable = true)
| | |-- +34 more attributes
|-- BygningEjendomsrelationList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bygning: string (nullable = true)
| | |-- +14 more attributes
|-- BygningList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- byg007Bygningsnummer: long (nullable = true)
| | |-- +89 more attributes
|-- EjendomsrelationList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bfeNummer: long (nullable = true)
| | |-- +22 more attributes
|-- EnhedEjendomsrelationList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- ejerlejlighed: string (nullable = true)
| | |-- +14 more attributes
|-- EnhedList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- adresseIdentificerer: string (nullable = true)
| | |-- +62 more attributes
|-- EtageList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bygning: string (nullable = true)
| | |-- +22 more attributes
|-- FordelingAfFordelingsarealList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- beboelsesArealFordeltTilEnhed: long (nullable = true)
| | |-- +16 more attributes
|-- FordelingsarealList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bygning: string (nullable = true)
| | |-- +19 more attributes
|-- GrundJordstykkeList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- forretningshændelse: string (nullable = true)
| | |-- +14 more attributes
|-- GrundList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bestemtFastEjendom: string (nullable = true)
| | |-- +27 more attributes
|-- OpgangList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- adgangFraHusnummer: string (nullable = true)
| | |-- +17 more attributes
|-- SagsniveauList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- byggesag: string (nullable = true)
| | |-- +27 more attributes
|-- TekniskAnlægList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- bygning: string (nullable = true)
| | |-- +65 more attributesAfter reading the JSON in a single dataframe, I proceeded to select each top level key of the JSON and run explode() on it to transform the array structure into rows. For example, one of the shorter code snippets is:
df_BEList = (
df.select(explode("BygningEjendomsrelationList"))
.withColumn("monotonically_increasing_id", monotonically_increasing_id())
.select(
'monotonically_increasing_id',
'col.bygning',
'col.bygningPåFremmedGrund',
'col.forretningshændelse',
'col.forretningsområde',
'col.forretningsproces',
'col.id_lokalId',
'col.id_namespace',
'col.kommunekode',
'col.registreringFra',
'col.registreringTil',
'col.registreringsaktør',
'col.status',
'col.virkningFra',
'col.virkningTil',
'col.virkningsaktør'
)
)I then try to save each of these dataframes into a delta table to later query them.
df_BEList.write.format('delta').mode('overwrite').save('/mnt/data/silver/BEList')
df_BEList.write.format('delta').saveAsTable('default.BEList')However, I am facing a problem when trying to generate a dataframe and run explode() on some of the keys+values of the JSON.
Specifically, on the BygningList (which has 90 attributes) and EnhedList (which has 63 attributes).
I have been getting different errors throughout my development. Starting with "java.lang.IllegalArgumentException: Cannot grow BufferHolder by size 768 because the size after growing exceeds size limitation 2147483632", which I seem to have gotten past by increasing the executor memory to 6GiB.
Now, most of my executions encounter a "java.lang.OutOfMemoryError: GC overhead limit exceeded" or "Reason: Executor heartbeat timed out after 126314 ms" after running the save to delta command, after about 1.4h of execution.
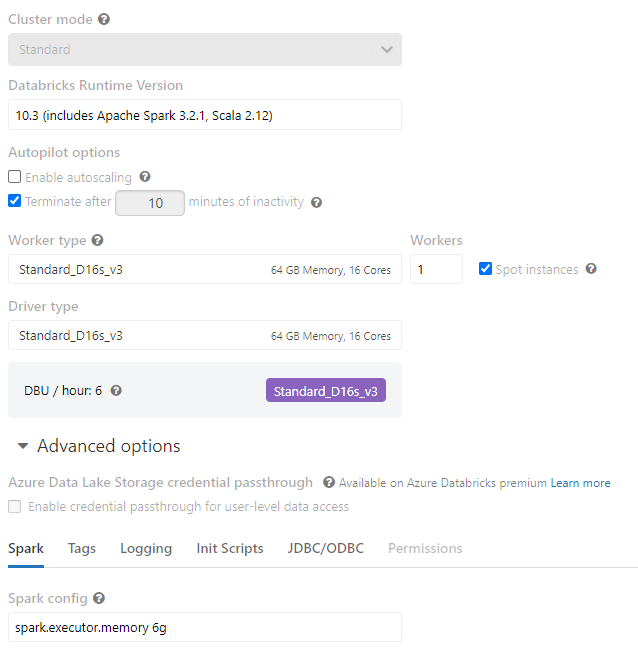
I have tried different strategies, increasing cluster size, increasing worker memory and number of cores. My current cluster configuration is:

The jobs details panel shows that the read operations seems to have worked, but the write fails, for a reason I can't understand at this point.


In the end, this fails and the Failure reason is: "Job aborted due to stage failure: Task 0 in stage 2.0 failed 4 times, most recent failure: Lost task 0.3 in stage 2.0 (TID 5) (10.139.64.5 executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Executor heartbeat timed out after 126314 ms".
I'm a bit stuck at this point and I don't know what to try. Any advice on what I should change to my code or cluster or the way I approach the problem will be very much appreciated!
13 REPLIES 13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2022 02:49 AM
@Radu Gheorghiu , Just save df = spark.read.option('multiline', 'true').json('dbfs:/mnt/data/delta/bronze/BBR_Actual_Totals.json').format("delta").save("/mnt/.../delta/" ) immediattly to delta without any processing (so create bronze delta layer).
All processing is done in the next step/notebook.
- I think you will need to have a lot of small partitions. Remember that exploding makes partition grow two times at least.
- In Spark, UI looks for data skews and spills also. So skews shouldn't be the problem here but better check.
- When you save to bronze delta, you can salt some additional columns with values from 1 to 512. So you will have 512delta partitions (folders/files) with the same part of your JSON (similar size). I would go with a number multiplied by the number of executors cores so, for example, 32 cores so 512 partitions/folders(files).
- The driver could be a bit bigger than the executors
- when you load that bronze delta to silver, also control how many spark partitions you have (it different partitions, but number 512 could be good as well, the partition should be around 100 MB).
I love to process big data sets 🙂 so let me know how it goes. There are some other solutions as well so no worry spark will handle it 🙂
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2022 03:39 AM
@Hubert Dudek , I have also tried your suggested first step, sometime after posting the original question. Unfortunately, that doesn't work either, which confuses me, since I expected it to work. I did think to write it to delta to benefit from the improvements that come with it.
df = spark.read.option('multiline', 'true').json('dbfs:/mnt/data/delta/bronze/BBR_Actual_Totals.json')
df.write.format('delta').mode('overwrite').save('/mnt/data/delta/silver/dev/all_json_data')However, I'm getting some strange errors. I have attached the stacktrace as a .txt file, because it's too large for the body of the message. I'll just post a short starting snippet below.
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<command-467748691415734> in <module>
----> 1 df.write.format('delta').mode('overwrite').save('/mnt/data/delta/silver/dev/all_json_data')
/databricks/spark/python/pyspark/sql/readwriter.py in save(self, path, format, mode, partitionBy, **options)
738 self._jwrite.save()
739 else:
--> 740 self._jwrite.save(path)
741
742 @since(1.4)
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
115 def deco(*a, **kw):
116 try:
--> 117 return f(*a, **kw)
118 except py4j.protocol.Py4JJavaError as e:
119 converted = convert_exception(e.java_exception)
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2022 04:03 AM
@Radu Gheorghiu ,
- You could also try to prepare a sample from your JSON like 1 MB and check is it processed correctly. It will be easier to debug.
- some ideas:
- please add .option("badRecordsPath", "/tmp/badRecordsPath") and/or mode PERMISSIVE
- I know it is pretty complex, but it could be good to define read schema to avoid second reading.
- if you have a single JSON object per line, you could read it as a text file with ( read.textFile), do partitioning, etc., and then use JSON functions to process data
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-08-2022 02:04 PM
Hi @Radu Gheorghiu , Would you like to tell us if @Hubert Dudek 's suggestions helped you?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-08-2022 02:06 PM
Hi Kaniz, I'm actually trying them right now. I have recently found a schema definition for my large JSON and I'm building it in Pyspark right now. I will most likely post an update to his feedback in a few hours.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-08-2022 02:12 PM
@Radu Gheorghiu , Awesome. Please let us know once you have tried it.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-26-2022 08:57 AM
Hi @Radu Gheorghiu , Just a friendly follow-up. Do you still need help, or @Hubert Dudek (Customer) 's response help you to find the solution? Please let us know.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-17-2022 10:43 AM
@Radu Gheorghiu I am in same boat as you. Mine is multiline json file and reading as text and partitioning is not an option. @Hubert Dudek what should be the solution in this case?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2022 02:31 PM
@Ravi Dobariya / @Radu Gheorghiu : Did you guys get the solution, I am also getting the same issue.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2022 11:43 PM
Hi @Radu Gheorghiu,
I have come across the same issue. What was your approach to this to be succeeded?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-28-2023 01:03 PM
HI Everyone,
I wanted to check back and see if people had a recommended approach to get past the described performance issues when working with very large JSON data and loading into Delta.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-28-2023 02:29 PM
The spark connector is super slow. I found loading json into Azure cosmos dB then writing queries to get sections of data out was 25x times faster because cosmos dB indexes the json. You can stream read data from cosmosdb. You can find python code snippets in cosmosdb documentation from Microsoft
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-30-2023 07:19 AM
Hi Renzer,
Thanks for the suggestion. We're actually in AWS and ingesting data from DocumentDB. Thanks to you and the community for any other suggestions.
Jeff



{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Optimal Cluster Configuration for Training on Billion-Row Datasets in Machine Learning
- Pulsar Streaming (Read) - Benchmarking Information in Data Engineering
- Liquid Clustering With Merge in Data Engineering
- Optimizing Delta Live Table Ingestion Performance for Large JSON Datasets in Data Engineering
- Delta Live Tables use case in Data Engineering