Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- how to flatten non standard Json files in a datafr...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2022 01:11 AM
hello,
I have a non standard Json file with a nested file structure that I have issues with. Here is an example of the json file.
jsonfile= """[ {
"success":true,
"numRows":2,
"data":{
"58251":{
"invoiceno":"58251",
"name":"invoice1",
"companyId":"1000",
"departmentId":"1",
"lines":{
"40000":{
"invoiceline":"40000",
"productid":"1",
"amount":"10000",
"quantity":"7"
},
"40001":{
"invoiceline":"40001",
"productid":"2",
"amount":"9000",
"quantity":"7"
}
}
},
"58252":{
"invoiceno":"58252",
"name":"invoice34",
"companyId":"1001",
"departmentId":"2",
"lines":{
"40002":{
"invoiceline":"40002",
"productid":"3",
"amount":"7000",
"quantity":"6"
},
"40003":{
"invoiceline":"40003",
"productid":"2",
"amount":"9000",
"quantity":"7"
} } } } }]"""
import pandas as pd
df = pd.read_json(jsonfile)
display(df)The problem here is that some of the keys are used as "58252", instead of "id":"58252" or blank value. This is the case for both the "Data" array and the "lines" array. So I have tried using standard functions in spark with json_normalize or explode but it doesnt seem to work with this particular json format.
The endgoal is to get a dataframe looking like this:

Labels:
- Labels:
-
Dataframe
-
Dataframes
-
File
-
JSON
-
Standard Functions
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2022 01:49 PM
Thanks for following up.
I didn'get any answers from this forum which I could use directly, but it did help me to move forward.
But I still figured out a solution to the problem after more study of the subject.
The best solution was to write a schema before importing the json file, It tooks some time to write the schema and get in correct format, Ex
StructField("data",
MapType(StringType(),StructType([
StructField("invoiceId", LongType(),True),
After using a schema, spark was able to understand that the numbering sequence on the node below data, was a struct type, that was handled correctly.
After the schema was correctly defined for the json file, it was possible to use spark to do explode operations on the struct node "data"
Ex:
from pyspark.sql.functions import explode, col
df1 = dfresult.select(explode('data'))
df2 = df1.select("value.*")
In the end I got all data into a normalized table.
thanks for all contributions and efforts to help.
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2022 04:17 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2022 04:19 AM
so in the next step you can do something similar for lines
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2022 11:18 AM
@Hubert Dudek ,
Thanks a lot for your answer. That helped. I still w,
onder how i can keep the connected data between the Data level and the "lines" level.
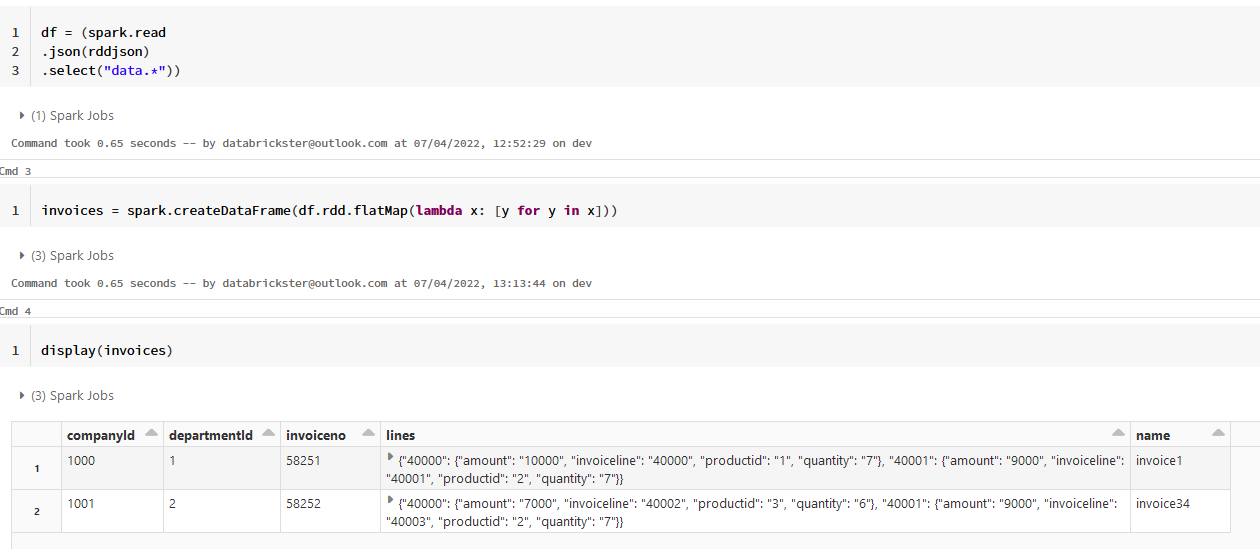
# i would like to keep reference to invoiceno in lines.*
dfl = invoices.select("lines.*","invoiceno")
lines = spark.createDataFrame(dfl.rdd.flatMap(lambda x: [y for y in x]))
# returns error message below
display(lines)I enclose the notebook/DBC file with comments questions as well.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-13-2022 09:37 AM
@stale stokkereit
You can use the below function to flatten the struct field
import pyspark.sql.functions as F
def flatten_df(nested_df):
flat_cols = [c[0] for c in nested_df.dtypes if c[1][:6] != 'struct']
nested_cols = [c[0] for c in nested_df.dtypes if c[1][:6] == 'struct']
flat_df = nested_df.select(flat_cols +
[F.col(nc+'.'+c).alias(nc+'_'+c)
for nc in nested_cols
for c in nested_df.select(nc+'.*').columns])
return flat_dfYour dataframe would look like this:

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2022 11:22 AM
Hi @stale stokkereit,
Just a friendly follow-up. Do you still need help or did any of the responses helped you? please let us know
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2022 01:49 PM
Thanks for following up.
I didn'get any answers from this forum which I could use directly, but it did help me to move forward.
But I still figured out a solution to the problem after more study of the subject.
The best solution was to write a schema before importing the json file, It tooks some time to write the schema and get in correct format, Ex
StructField("data",
MapType(StringType(),StructType([
StructField("invoiceId", LongType(),True),
After using a schema, spark was able to understand that the numbering sequence on the node below data, was a struct type, that was handled correctly.
After the schema was correctly defined for the json file, it was possible to use spark to do explode operations on the struct node "data"
Ex:
from pyspark.sql.functions import explode, col
df1 = dfresult.select(explode('data'))
df2 = df1.select("value.*")
In the end I got all data into a normalized table.
thanks for all contributions and efforts to help.



{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Handling Null Values in Feature Stores in Machine Learning
- Ingesting complex/unstructured data in Data Engineering
- Explode is giving unexpected results. in Data Engineering
- java.lang.ArithmeticException: long overflow Exception while writing to table | pyspark in Data Engineering
- "Photon ran out of memory" while when trying to get the unique Id from sql query in Machine Learning