Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- address how to use multiple spark streaming jobs c...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-01-2022 10:37 PM
Hi,
We have a scenario where we need to deploy 15 spark streaming applications on databricks reading from kafka to single Job cluster.
We tried following approach:
1. create job 1 with new job cluster (C1)
2. create job2 pointing to C1
...
3. create job15 pointing to C1
But, the problem here is if the job 1 fails, it is terminating all the other 14 jobs.
One of the options we are thinking is to have a ***** kafka topic with no messages in it and ***** spark streaming job reading from ***** kafka topic (which will never fail 99.99%) which create new job cluster (C1) and rest of the 15 jobs will point to C1. We are assuming Job cluster C1 will never fail 99.99%.
Other solution we have is to create each job cluster for each job (15 Clusters for 15 jobs ) but it is going to kill our operational costs as it is continuous streaming job and some of topics have very less volume.
Could you please advice on how to address this issue.
Thanks
Jin.
Labels:
- Labels:
-
Job
-
Job Cluster
-
Multiple Spark
-
Spark streaming
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 12:14 AM
@Jin Kim ,
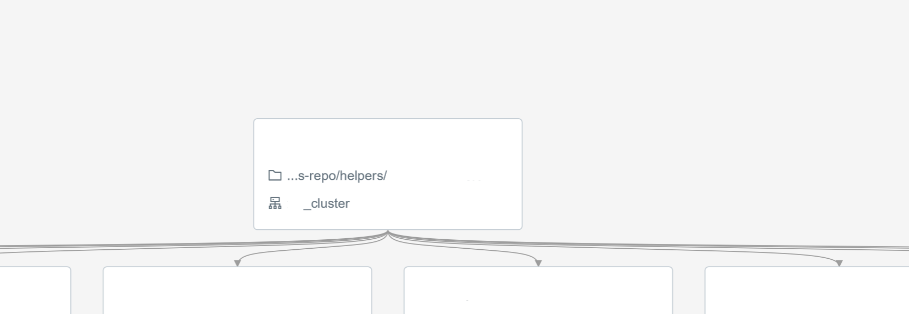
- When you set tasks in a job, first put some ***** task and then every streaming as separated task depended on first (see image below how logic will look like) so there will be only one job,
- Inside every streaming task, use spark.streams.awaitAnyTermination() to monitor it, and when failed to restart - custom logic,
- redirect fail notifications messages to pagerduty or something to know that job is falling,
- set maximum one concurrent job run and frequently run, like every 5 mins, so it will automatically run again when something fails.

4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 12:14 AM
@Jin Kim ,
- When you set tasks in a job, first put some ***** task and then every streaming as separated task depended on first (see image below how logic will look like) so there will be only one job,
- Inside every streaming task, use spark.streams.awaitAnyTermination() to monitor it, and when failed to restart - custom logic,
- redirect fail notifications messages to pagerduty or something to know that job is falling,
- set maximum one concurrent job run and frequently run, like every 5 mins, so it will automatically run again when something fails.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-04-2022 02:53 AM
@Hubert Dudek , thanks a lot for responding.
- When we have setup like this, if one tasks fails, it will not terminate the entire job right?
- Since, the job is continously running as it is streaming app, is it possible to add new task to the job(while it is running)? We have around 100 kafka topics and each streaming app listens to only 1 topic.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-12-2022 02:00 AM
Hi @Jin Kim , Are you aware of the Workflows with jobs ? Please go through the doc.
Databricks manages the task orchestration, cluster management, monitoring, and error reporting for all of your jobs. You can run your jobs immediately or periodically through an easy-to-use scheduling system.
ALSO,
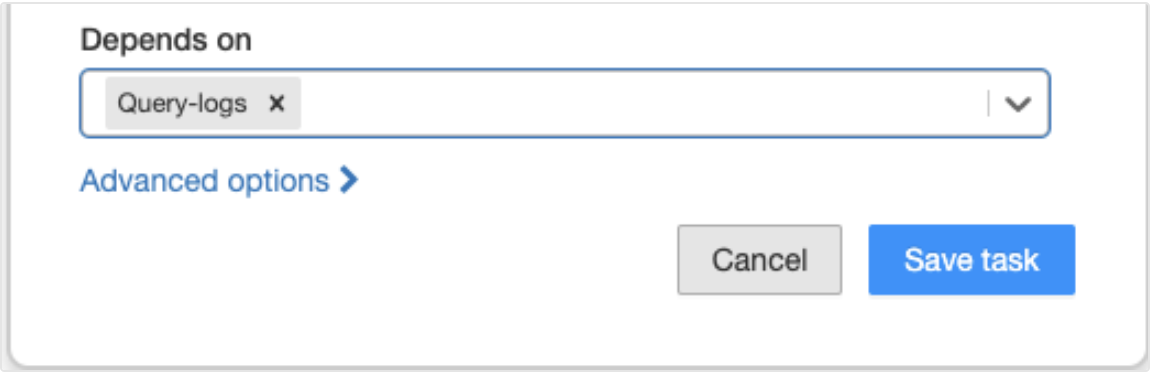
You can define the order of execution of tasks in a job using the Depends on drop-down. You can set this field to one or more tasks in the job.


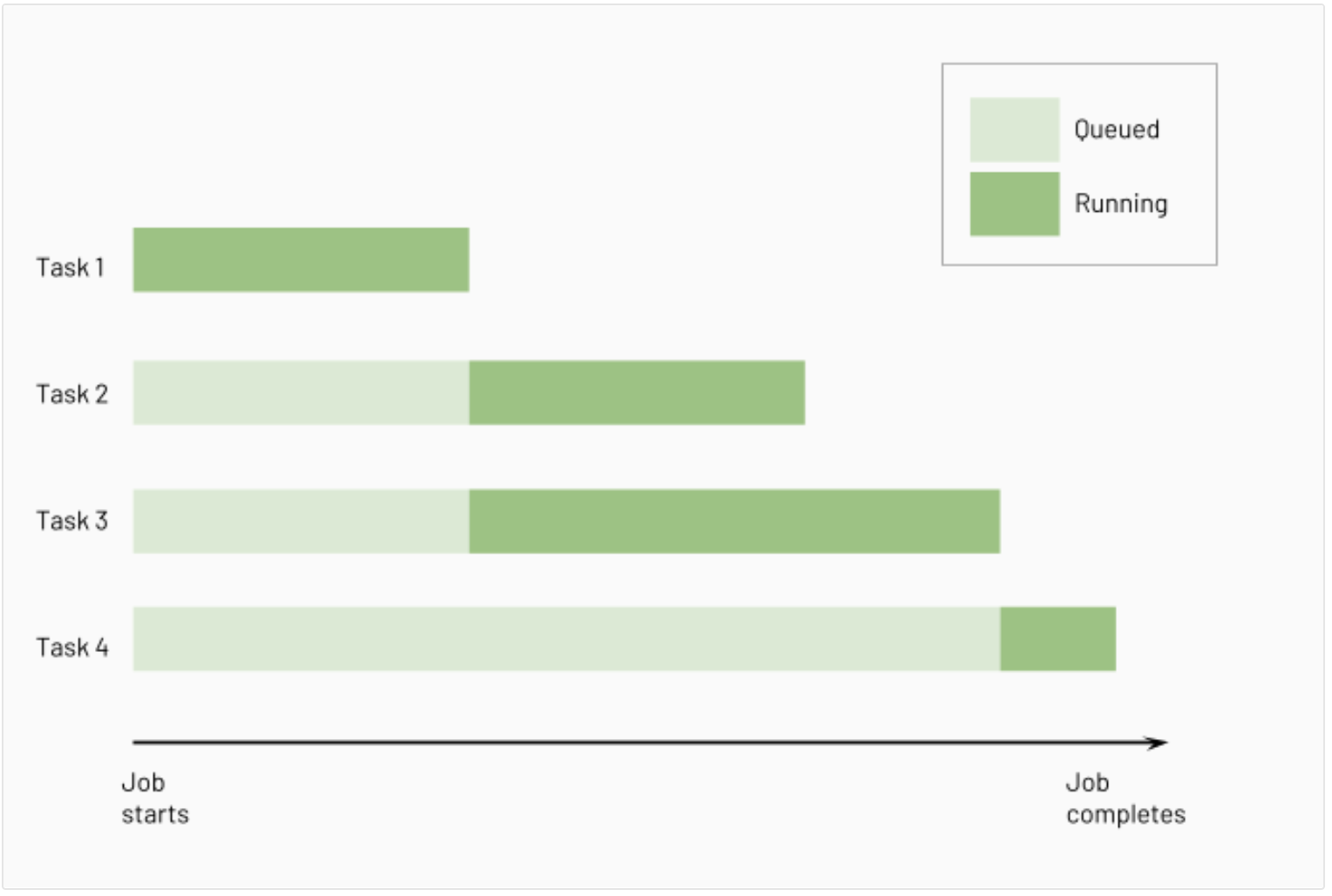
- Task 1 is the root task and does not depend on any other task.
- Task 2 and Task 3 depend on Task 1 completing first.
- Finally, Task 4 depends on Task 2 and Task 3 completing successfully.
Databricks runs upstream tasks before running downstream tasks, running as many of them in parallel as possible. The following diagram illustrates the order of processing for these tasks:

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-18-2022 05:59 AM
Hi @Jin Kim, Just a friendly follow-up. Do you still need help, or the above responses help you to find the solution? Please let us know.
Announcements




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Writing to multiple files/tables from data held within a single file through autoloader in Data Engineering
- Join multiple streams with watermarks in Warehousing & Analytics
- Error running 80 task at same time in Job, how limit this? in Administration & Architecture
- DLT SCD type 2 in bronze, silver and gold? Is it possible? in Data Engineering
- Resource exhaustion when using default apply_changes python functionality in Data Engineering