Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
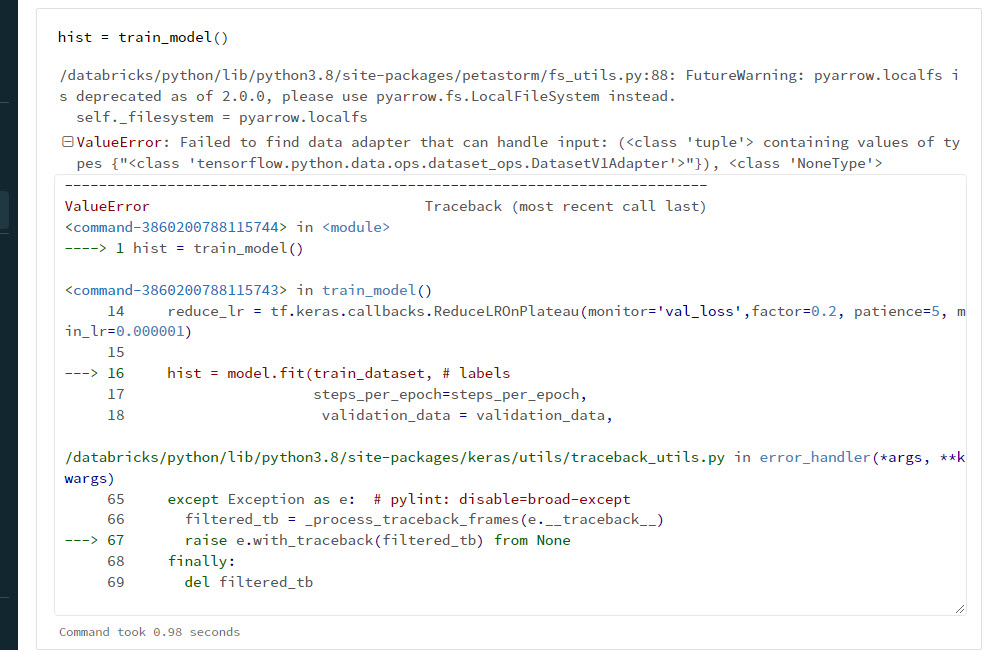
- Model Training Data Adapter Error.
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Model Training Data Adapter Error.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2022 10:52 AM
We are converting Pyspark dataframe to Tensorflow using PetaStorm and have encountered a “data adapter” error. What do you recommend for diagnosing and fixing this error?
https://docs.microsoft.com/en-us/azure/databricks/applications/machine-learning/load-data/petastorm


Thanks for help
Labels:
- Labels:
-
Petastorm
-
Pyspark Dataframe
-
Tensor flow
8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 01:52 AM
Hi @Nathan Law , Did you already check these requirements?
Requirements
- Databricks Runtime 7.3 LTS ML or above. On Databricks Runtime 6.x ML, you need to install petastorm==0.9.0 and pyarrow==0.15.0 on the cluster.
- Node type: one driver and two workers. Databricks recommends using GPU instances.
This notebook demonstrates the following workflow on Databricks:
- Load data using Spark.
- Convert the Spark DataFrame to a TensorFlow Dataset using petastorm spark_dataset_converter
- Feed the data into a single-node TensorFlow model for training.
- Feed the data into a distributed hyperparameter tuning function.
- Feed the data into a distributed TensorFlow model for training.
The example in this notebook is based on the transfer learning tutorial from TensorFlow. It applies the pretrained MobileNetV2 model to the flo/were data set.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:00 AM
Hi @Nathan Law following up did you get a chance to check @Kaniz Fatma 's previous comments ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:08 AM
Hi @Nathan Law, We haven’t heard from you on the last response from me, and I was checking back to see if you have a resolution yet. If you have any solution, please do share that with the community as it can be helpful to others. Otherwise, we will respond with more details and try to help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:30 AM
Hi,
From the Petastorm example:
# Make sure the number of partitions is at least the number of workers which is required for distributed training.
I am testing an recommendation to not use Autoscaling. I'll report back with findings.
- Nathan
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-06-2022 06:47 AM
@Nathan Law , Please don't forget to click on the "Select as Best" option whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:05 AM
Hey there @Nathan Law
Hope all is well!
Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? It would be really helpful for the other members too.
We'd love to hear from you.
Cheers!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:24 AM
Making progress but still working through issues. I'll post findings when completed.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-19-2022 08:35 AM
Hey @Nathan Law
Thank you so much for getting back to us. We will await your response.
We really appreciate your time.
Announcements



{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Help - org.apache.spark.SparkException: Job aborted due to stage failure: Task 47 in stage 2842.0 in Machine Learning
- Serving a custom transformer class via a pyfunc wrapper for a pyspark recommendation model in Machine Learning
- Error in Tensorflow training job in Machine Learning
- create_feature_table returns error saying database does not exist while it does in Data Engineering
- Hello unable to start using the notebook in Data Engineering