Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
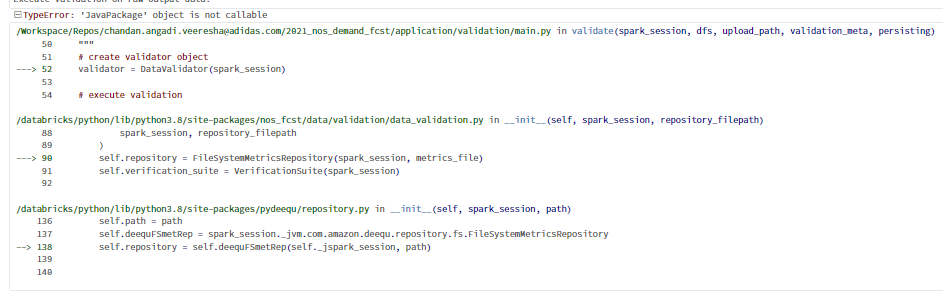
- TypeError: 'JavaPackage' object is not callable
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 01:49 AM

1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2022 04:13 AM
Hi @Kaniz Fatma ,
Sorry for the late response, Installing deequ-2.0.1-spark-3.2 on cluster solves the issue.
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 03:07 AM
@Chandan Angadi, which library are you using? Are you installing using the libraries tab or are you using an init script to install the library. Is this happening always or intermittent?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 04:24 AM
Hi @Prabakar Ammeappin ,
I am using set of libraries, which I am installing under a notebook. Not in the cluster config.
python>=3.7,<3.8
findspark=1.3.0
openpyxl=3.0.7
pyarrow=0.14.0
smart_open=5.2.1
xlrd=2.0.1
conda-pack=0.6.0
tqdm=4.62.2
tsfresh=0.17.0
scikit-learn=0.24.2
pip=21.2.4
git=2.33.0
pandas=1.2.5
fsspec=2021.7.0
mlflow==1.20.1
pydeequ==0.1.5
s3fs==2021.8.0
botocore==1.20.106
boto3==1.17.106
pyspark==2.4.7
torch-tb-profiler==0.4.0
pytorch-forecasting==0.9.2
pytorch-lightning==1.4.5
tensorboard==2.8.0
ipyaggrid==0.2.1
jupyter-contrib-nbextensions==0.5.1
fastparquet==0.7.1
plotnine==0.8.0
tslearn==0.5.2
fastdtw==0.3.4
dtaidistance==2.3.2
catboost==1.0.3
shap==0.40.0
k-means-constrained==0.6.0
pdf2image==1.16.0
kaleido==0.2.1
pickle5==0.0.12
Thanks,
Chandan
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 08:24 AM
By any chance, was the cluster restarted after installing the libraries or was it detached and reattached from/to the notebook? Notebook-scoped libraries do not persist across sessions. You must reinstall notebook-scoped libraries at the beginning of each session, or whenever the notebook is detached from a cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-02-2022 09:52 PM
HI @Prabakar Ammeappin ,
Yes, I agree notebook scoped lib do not persist across sessions. I am installing the required lib in the first cell of the notebook and afterward rest of the code will be executed. The notebook is not detached from the cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-03-2022 01:44 AM
We need to debug the logs to understand this further. Is it possible for you to export and share a notebook with minimal repro steps? It will help us to reproduce this in-house and check the logs. Or If you have a support contract, it would be better to raise a support ticket.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2022 12:39 AM
Hi @Chandan Angadi , We haven’t heard from you on the last response from @Prabakar Ammeappin , and I was checking back to see if you have a resolution yet. If you have any solution, please do share that with the community as it can be helpful to others. Otherwise, we will respond with more details and try to help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2022 04:13 AM
Hi @Kaniz Fatma ,
Sorry for the late response, Installing deequ-2.0.1-spark-3.2 on cluster solves the issue.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2022 04:16 AM
Hi @Chandan Angadi, I'm glad the issue is resolved. Thank you for selecting the best answer for the community.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-09-2022 04:22 AM
The spark version of Jar file must match with Cluster Spark version
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- 0: 'error: TypeError("\'NoneType\' object is not callable") in api_request_parallel_processor.py in Machine Learning
- TypeError: 'JavaPackage' object is not callable in Machine Learning
- Synapse ML - TypeError: 'JavaPackage' object is not callable in Machine Learning
- Problems with extending DataFrame-object with custom method in DBR 14.0 in Data Engineering
- TypeError: 'JavaPackage' object is not callable - DocumentAssembler() - Spark NLP in Data Engineering