Hi all!
Before we used Databricks Repos we used the run magic to run various utility python functions from one notebook inside other notebooks, fex like reading from a jdbc connections. We now plan to switch to repos to utilize the fantastic CI/CD possibilities that gives us. But we meet some challenges with this.
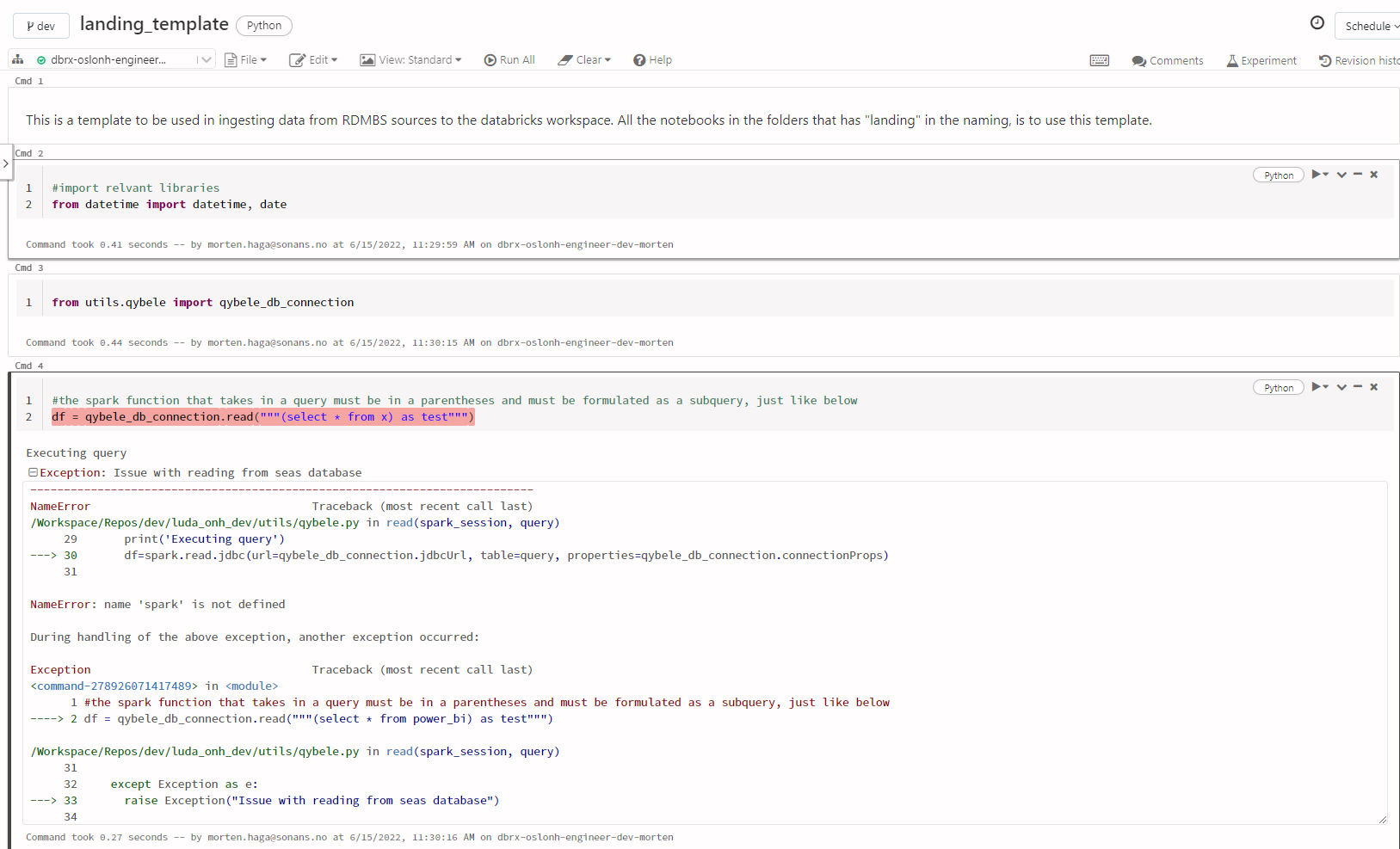
First, as I have understood, you cant use the run magic to run notebooks. Only arbritary files are allowed to be used. Then we re-wrote from notebook to .py files and sucessfully imported the functions but a spark related error occured.
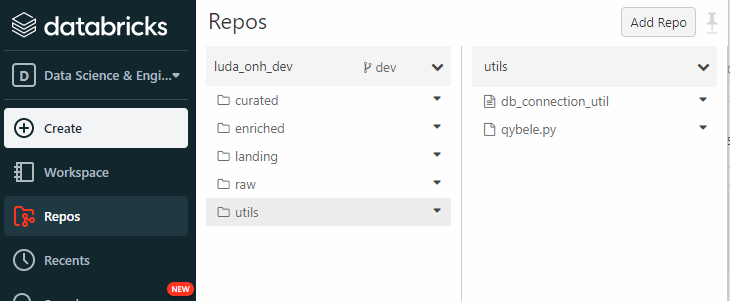
This is the overview of my setup:
The python file with the function resides in the folder "utils" and the notebook I want to make use of it is inside the folder "landing".
 The function looks like this:
The function looks like this:
class qybele_db_connection:
#this class creates a secure connection to the seas database
jdbcHostname = "x"
jdbcPort = 3306
jdbcDatabase = "x"
jdbcUrl = "jdbc:mysql://{0}:{1}/{2}".format(jdbcHostname, jdbcPort, jdbcDatabase)
#always use the databricks secrets manager to store password
jdbcpassword = 'x'
connectionProps = { "user": 'x', "password": jdbcpassword }
@staticmethod
def read(spark_session,query=str):
"""
this static method uses the above variables in a spark.read.jdbc function to create the connection.
Note that the function takes in a string, which is a query and passes it to the "table" method in the spark function.
"""
try:
print('Executing query')
df=spark.read.jdbc(url=qybele_db_connection.jdbcUrl, table=query, properties=qybele_db_connection.connectionProps)
except Exception as e:
raise Exception("Issue with reading from seas database")
return df
This is how I import it to the notebook:

- Do I really have to start with the whole sparksession thing when including "spark.read.jdbc" in python files for this kind of workflow?
- How can I stick to the run magic like before; ie running the notebook, instead of importing the python function?
- How does this effect the results when you use this notebook from repos in jobs/workflows?
- How does databricks secrets act when using repos like this?





{kind=link}
{kind=link}