Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- PySpark: Writing Parquet Files to the Azure Blob S...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-23-2022 02:59 AM
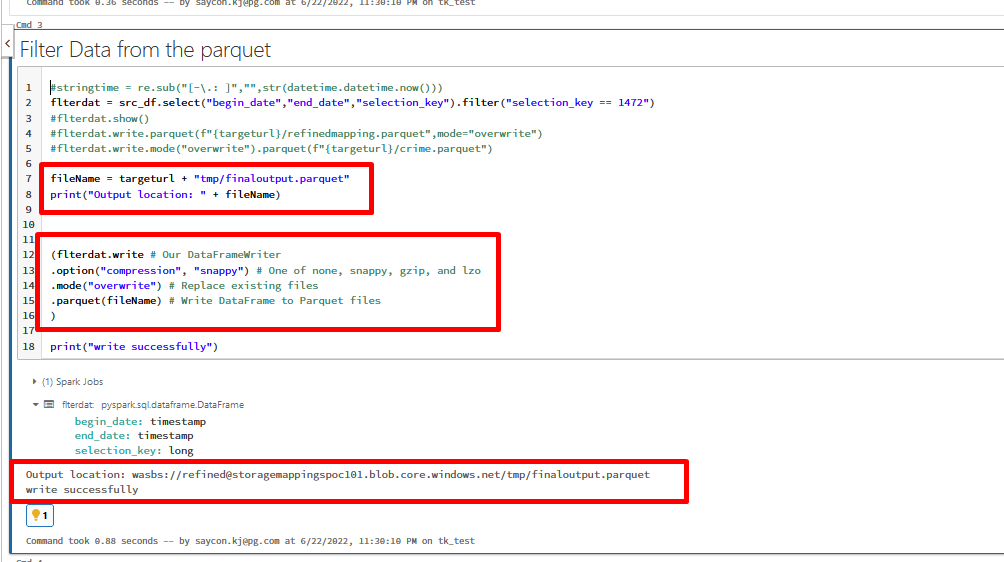
Currently I am having some issues with the writing of the parquet file in the Storage Container. I do have the codes running but whenever the dataframe writer puts the parquet to the blob storage instead of the parquet file type, it is created as a folder type with many files content to it.
One note to it, I tried searching various ways in the internets that it seems this is default creation when using pyspark and I can see in the folder created there was a file parquet with a snappy add into it (refer to the screenshots below)
")

")
Labels:
1 ACCEPTED SOLUTION
Accepted Solutions
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-24-2022 06:16 AM
When you write a file, it uses the default compression if you don't specify it. The default compression is snappy, so that's expected + desired behavior.
Parquet is meant to be splittable. It also needs to create the other files that begin with the underscore to ensure you don't get partial or broken writes.
What exactly are you trying to do?
3 REPLIES 3
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-24-2022 06:16 AM
When you write a file, it uses the default compression if you don't specify it. The default compression is snappy, so that's expected + desired behavior.
Parquet is meant to be splittable. It also needs to create the other files that begin with the underscore to ensure you don't get partial or broken writes.
What exactly are you trying to do?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2022 07:02 AM
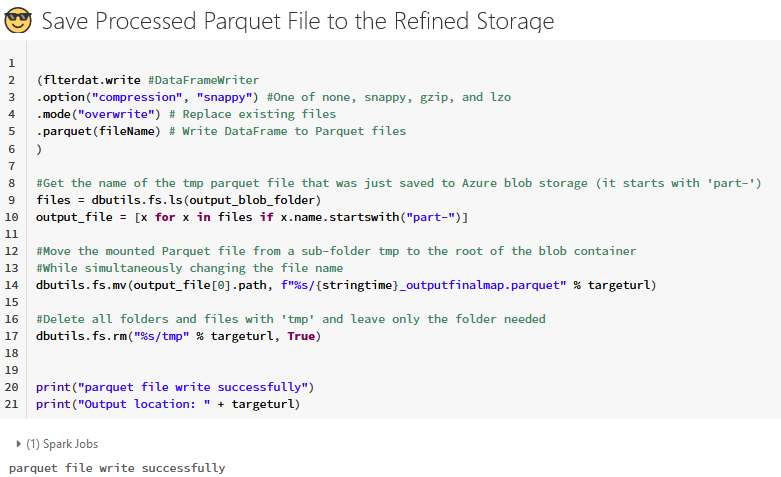
Already found out that this is already the behaviour, so to make it work, currently all the wrangled folders are being deleted and the file parquet contents inside the wrangled folder are already being moved outside the folder while renaming it. That's the solution I see from my goal to dump a single parquet file on the container with no wrangled folders.
Thank you @Joseph Kambourakis

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2022 04:29 AM
Hello @Karl Saycon
Can you try setting this config to prevent additional parquet summary and metadata files from being written? The result from dataframe write to storage should be a single file.
A combination of below three properties will help to disable writing all the transactional files which start with "_".
- We can disable the transaction logs of spark parquet write using "spark.sql.sources.commitProtocolClass = org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol". This will help to disable the "committed<TID>" and "started<TID>" files but still _SUCCESS, _common_metadata and _metadata files will generate.
- We can disable the _common_metadata and _metadata files using "parquet.enable.summary-metadata=false".
- We can also disable the _SUCCESS file using "mapreduce.fileoutputcommitter.marksuccessfuljobs=false".
Announcements




.png){kind=link}
.png){kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Invalid configuration fs.azure.account.key trying to load ML Model with OAuth in Data Engineering
- Unity Catalog Metastore Details in Data Engineering
- Optimizing Delta Live Table Ingestion Performance for Large JSON Datasets in Data Engineering
- Python UDF in Unity Catalog - spark.sql error in Data Engineering
- Cannot create External Location due to HNS on Azure Datarbricks in Data Governance