Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- how to access data objects from different language...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-30-2022 05:25 AM
Hi sorry new to Spark, DataBricks. Please could someone summarise options for moving data between these different languages. Esp. interested in R<=>Python options: can see how to do SQL/Spark. Spent a lot of time googling but no result. Presume can use R's reticulate to access python objects..?
Anyway grateful for any idiot-proof links, quick guides, code.
Labels:
- Labels:
-
DataObjects
-
Python
-
SQL
-
Summarise Options
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-05-2022 10:47 PM
If you’re using R I highly recommend the sparklyr package from RStudio. Many of the pyspark functions have the same name, for example, “spark.read.table()” is “spark_read_table” in sparklyr. More info here: https://spark.rstudio.com/packages/sparklyr/latest/reference/spark_read_table.html
12 REPLIES 12
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-30-2022 07:38 AM
Hi, you can create a temporary table and then retrieve it with every rogramming language:
ex create in sql:
%sql
CREATE OR REPLACE TEMPORARY VIEW Test1 AS
SELECT *
FROM TESTAnd then retrieve in python
%python
spark.read.table('Test1')Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-05-2022 07:50 AM
Thanks. I took that approach to create view and then queried it using SQL from R:
%r
rd=as.data.frame(sql("select * from CNTRY_FLOWS"))
...not sure if there's a more direct route. I was unsure what the equivalent to python spark.read.table() for R was.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-05-2022 10:47 PM
If you’re using R I highly recommend the sparklyr package from RStudio. Many of the pyspark functions have the same name, for example, “spark.read.table()” is “spark_read_table” in sparklyr. More info here: https://spark.rstudio.com/packages/sparklyr/latest/reference/spark_read_table.html
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-05-2022 10:58 PM
One other thing I thought of— with Spark you want to keep your data in Spark as much as possible and not bring it back to R unless you have too. With Sparklyr you can use many tidyverse functions directly in Spark without having to collect your results and put them in a data frame first. For R functions or packages that don’t have a connection to the Spark API directly you can also use sparklyr::spark_apply to distribute your R code over the cluster and leave your Spark data frames in spark.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2022 03:30 AM
Thanks so much for this. Actually most of my code has been python to date. It was really about knowing how to access objects from one language in the others—e.g. I had some R code to produce a graph that I wanted to recycle.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2022 03:32 AM
I think there's a trick which still hasn't (yet) been achieved in spark. Why can't there be standard syntax to access all objects across all languages it supports (with appropriate data structure translation).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-07-2022 09:45 PM
Depending on what you’re doing there is a package called reticulate in R that lets you directly share objects between R and python, Spark not required. https://rstudio.github.io/reticulate/
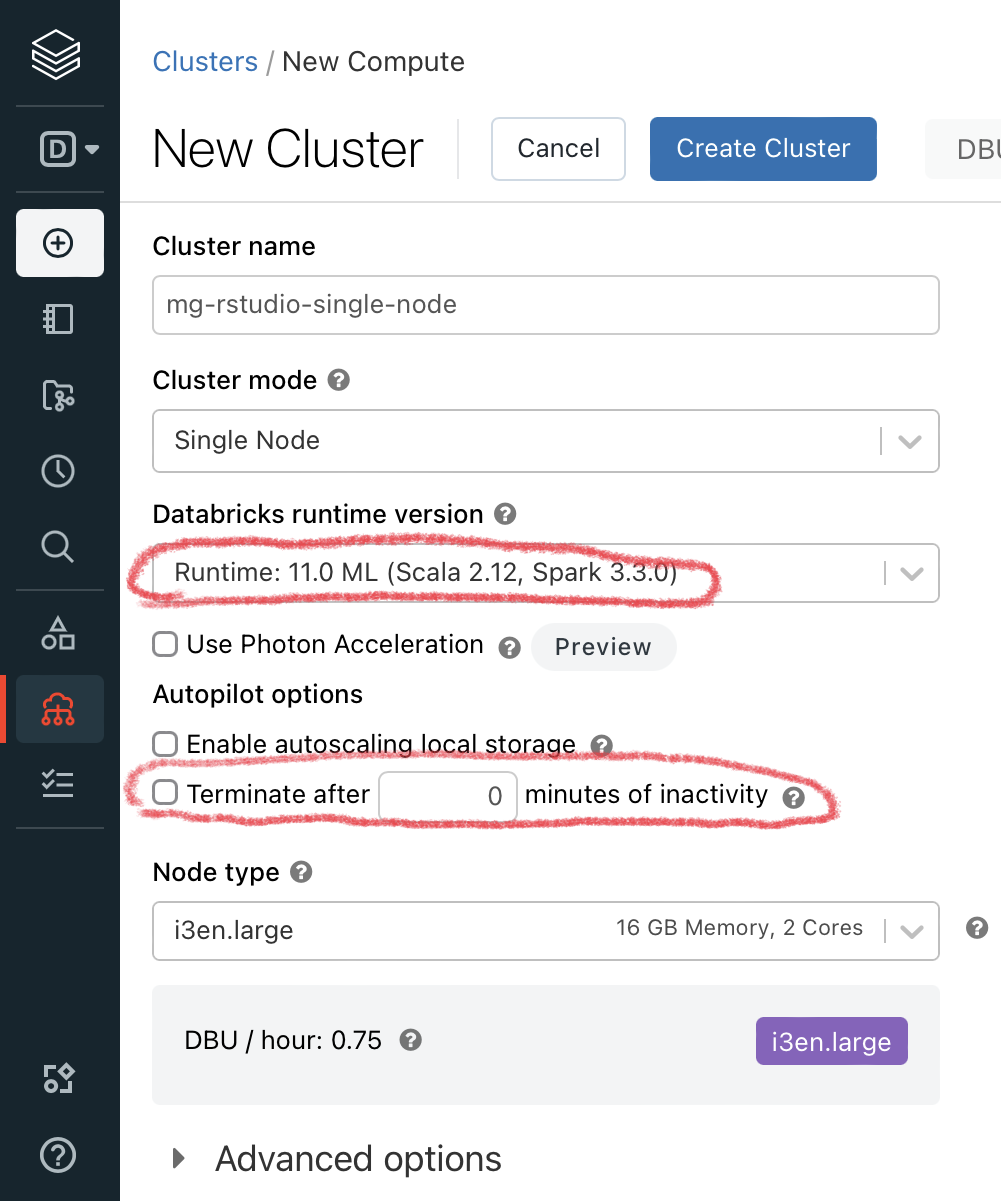
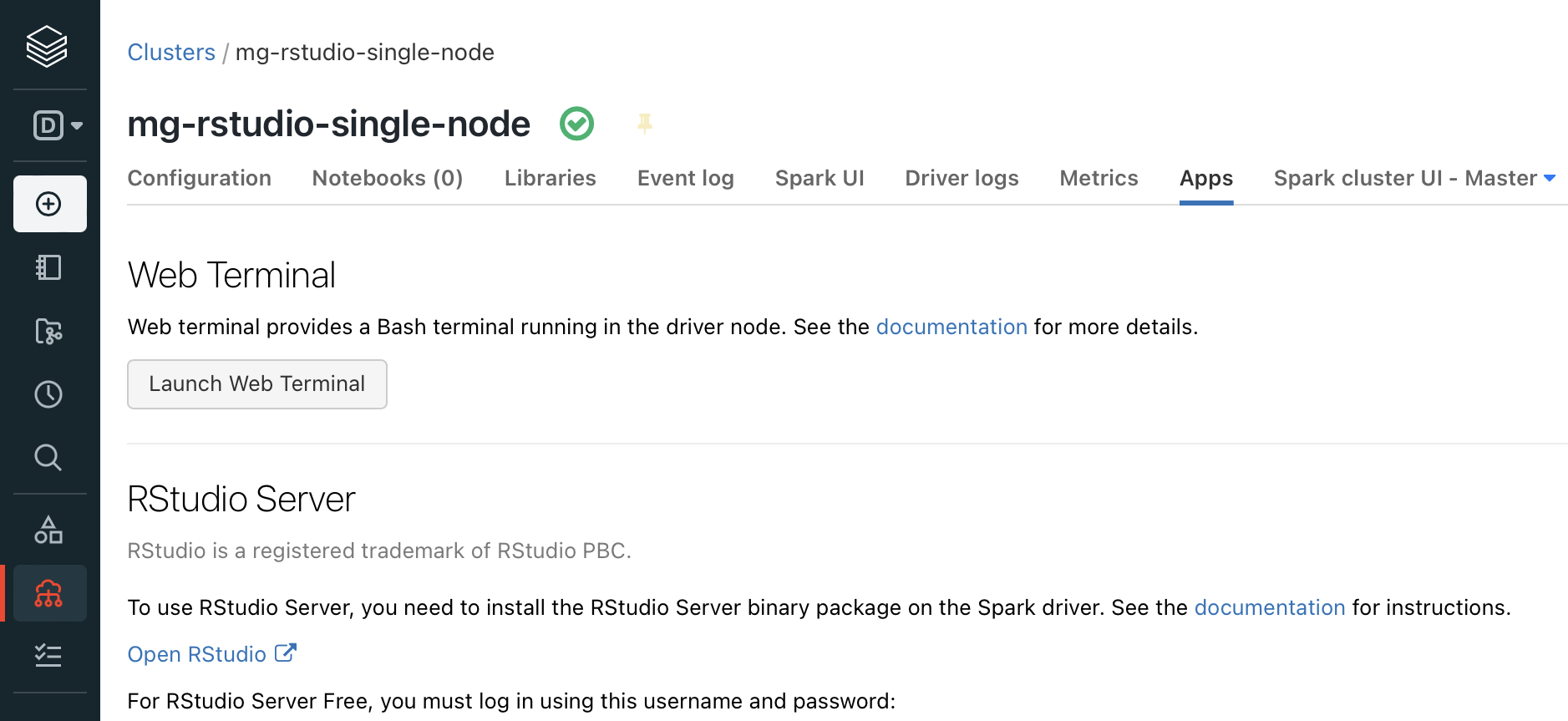
However I’ve found (so far) it really only works in RStudio, which does run awesomely on Databricks when using the DB ML distributions. You can find RStudio preinstalled on the DB cluster under “apps” on the cluster’s page when you deselect the cluster auto termination for inactivity:


There is a bit more set up once in RStudio on DB to make reticulate work flawlessly that I could post if interested.
What I haven’t tested yet is what happens if you make an Rmd using reticulate in RStudio on Databricks and then try to schedule that in a DB Workflow later. If I do I’ll be sure to post about it in the community.
I’d love it if more direct adoption of reticulate was included in Databricks notebooks that extended it to Scala and SQL too, like you’ve suggested. Each language has its advantages in my opinion, and there are some really awesome ML packages in tidymodels for R that get frequently overlooked by the python community in my opinion because the switching between languages is difficult in most places.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2022 04:46 AM
hi thanks for this. Yes I was aware of reticulate, if not its use in databricks. Actually most of my code is python. It's just had an issue getting some libraries to load and had R code for that so wanted to include an R chunk.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-06-2022 04:01 PM
@Simone Folino & @Matthew Giglia Amazing responses, thank you for jumping in and providing your personal expertise in this thread!
@Fernley Symons I think we are all eager to hear if these suggestions got you 100% sorted! If so, feel free to choose one of the replies as "best" so the rest of the community knows this question is answered in the future. If not, feel free to let us know what else you need. Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2022 03:05 AM
Hi @Fernley Symons Gentle reminder on the answer provided above. Please let us know if you have more doubts or queries.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2022 03:08 AM
? I've already voted best answer...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2022 03:10 AM
@Fernley Symons Thank you for your prompt reply. Apologies, we have just noticed that an answer is already marked as best. Thank you once again.
Announcements




{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Github Datasets/Labs for Large Language Models: Application through Production is not working in Machine Learning
- Problems with DLT, Unity catalog and external connection in Data Engineering
- How can I programmatically get my notebook default language? in Data Engineering
- Save default language of notebook into variable dynamically in Data Engineering
- Language Preferences changes all day in Administration & Architecture