Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Flatten a complex JSON file and load into a delta ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Flatten a complex JSON file and load into a delta table
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-12-2022 10:27 AM
Hi,
I am loading a JSON file into Databricks by simply doing the following:
from pyspark.sql.functions import *
from pyspark.sql.types import *
bronze_path="wasbs://....../140477.json"
df_incremental = spark.read.option("multiline","true").json(bronze_path)
display(df_incremental)
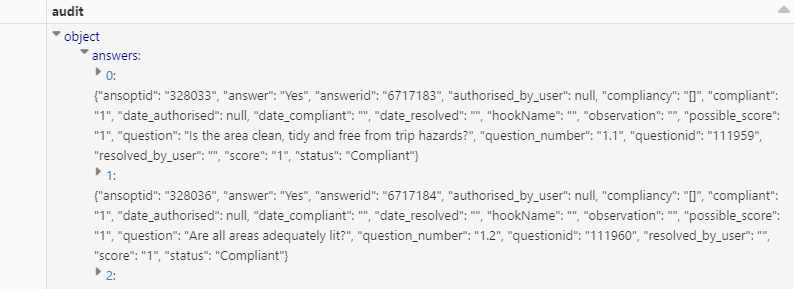
My JSON file is complicated and is displayed:

I want to be able to load this data into a delta table.
My schema is:
type AutoGenerated struct {
Audit struct {
Refno string `json:"refno"`
Formid string `json:"formid"`
AuditName string `json:"audit_name"`
AuditorName string `json:"auditor_name"`
Location string `json:"location"`
Fulllocation string `json:"fulllocation"`
Published string `json:"published"`
Date string `json:"date"`
Compliant string `json:"compliant"`
Archived string `json:"archived"`
Score string `json:"score"`
PossibleScore string `json:"possible_score"`
Percentage string `json:"percentage"`
Answers []struct {
QuestionNumber string `json:"question_number"`
Question string `json:"question"`
Status string `json:"status"`
Answerid string `json:"answerid"`
Questionid string `json:"questionid"`
Answer string `json:"answer"`
Ansoptid string `json:"ansoptid,omitempty"`
Observation string `json:"observation"`
Compliant string `json:"compliant"`
Score string `json:"score"`
PossibleScore string `json:"possible_score"`
DateResolved string `json:"date_resolved"`
ResolvedByUser string `json:"resolved_by_user"`
DateCompliant string `json:"date_compliant"`
Compliancy []interface{} `json:"compliancy"`
HookName string `json:"hookName"`
DateAuthorised string `json:"date_authorised,omitempty"`
AuthorisedByUser string `json:"authorised_by_user,omitempty"`
} `json:"answers"`
} `json:"audit"`
}Any idea how to do this?
Labels:
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 06:45 AM
delta can handle nested columns so you can just write it to delta lake.
Have you tried it already? It will probably just work.
If you talke about new incoming data that you want to merge in an existing table, that will be a tad more complex. You need to define a merge key which will decide what operation you will do (insert, delete update).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 06:55 AM
How would I write this to a delta table to see if it works?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2022 06:59 AM
ok so you already have a df with your json data (with inferred schema).
Next step is:
df.write \
.format("delta") \
.mode("overwrite") \
.save("<whereveryouwanttostoreyourdata>")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2022 10:26 PM
Hi @Lloyd Vickery
Does @Werner Stinckens response answer your question? If yes, would you be happy to mark it as best so that other members can find the solution more quickly?
We'd love to hear from you.
Thanks!



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Optimizing Delta Live Table Ingestion Performance for Large JSON Datasets in Data Engineering
- Concurrency issue with append only writed in Data Engineering
- Ingesting complex/unstructured data in Data Engineering
- How to improve Spark UI Job Description for pyspark? in Data Engineering
- java.lang.ArithmeticException: long overflow Exception while writing to table | pyspark in Data Engineering