You’ve gotten familiar with Delta Live Tables (DLT) via the quickstart and getting started guide. Now it’s time to tackle creating a DLT data pipeline for your cloud storage–with one line of code. Here’s how it’ll look when you're starting:
CREATE OR REFRESH STREAMING LIVE TABLE <table_name>
AS SELECT * FROM cloud_files('<cloud storage location>', '<format>')
The cloud storage locations could be AWS S3 (s3://), Azure Data Lake Storage Gen2 (ADLS Gen2, abfss://), GCP Cloud Storage (GCS, gs://), Azure Blob Storage (wasbs://), ADLS Gen1 (adl://). Databricks File System (DBFS, dbfs:/) is also an option, but it’s not recommended for production pipelines.
Check out these 5 tips to get DLT to run that one line of code.
1. Use Auto Loader to ingest files to DLT
2. Let DLT run your pipeline notebook
3. Use JSON cluster configurations to access your storage location
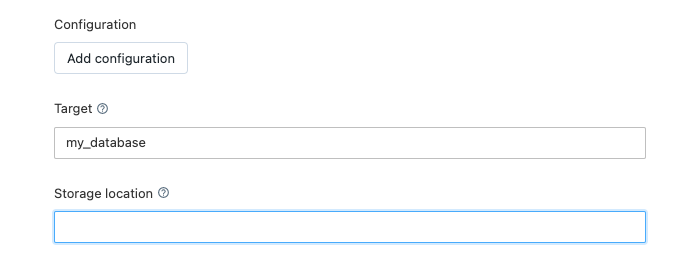
4. Specify a Target database for your table(s)
5. Use the ‘Full refresh all’ to pull DLT pipeline code and settings changes
Tip #1: Use Auto Loader to ingest files to DLT
Knowledge check: What is Auto Loader?
Auto Loader provides a Structured Streaming source called cloud_files. Given an input directory path on the cloud file storage, the cloud_files source automatically processes new files as they arrive, with the option of also processing existing files in that directory. Auto Loader can ingest JSON, CSV, PARQUET, AVRO, ORC, TEXT and BINARYFILE file formats. Auto Loader has support for both Python and SQL in Delta Live Tables.
Example: Auto Loader with S3
CREATE OR REFRESH STREAMING LIVE TABLE my_S3_data
AS SELECT * FROM cloud_files('s3a://your_datbase_name', 'json')
Your next steps
- Go to your Databricks landing page and select Create Blank Notebook.
- In the Create Notebook dialogue, give your notebook a name and select SQL from the Default Language dropdown menu. Pop in your version of that one-line of code. You can leave Cluster set to the default value. The Delta Live Tables runtime creates a cluster before it runs your pipeline.
- Once you’ve written your pipeline code in a notebook, don’t run that notebook. Instead, go create your first DLT pipeline (see Tip #2).
More resources
- Using Auto Loader in Delta Live Tables [AWS] [Azure][GCP]
- Auto Loader [AWS] [Azure][GCP]
- Ingest data into Delta Live Tables [AWS] [Azure][GCP]
- Auto Loader provides a number of options for configuring cloud infrastructure: [AWS][Azure][GCP]
Tip #2: Let DLT run your pipeline notebook
Knowledge check: What is DLT?
Delta Live Tables is a framework for building reliable, maintainable, and testable data processing pipelines. You define the transformations to perform on your data, and Delta Live Tables manages task orchestration, cluster management, monitoring, data quality, and error handling. Read more in the Delta Live Tables introduction [AWS] [Azure][GCP].
Example
- You must start your pipeline from the Delta Live Tables tab of the Workflows user interface. Clicking the triangle run icon in your notebook to run your pipeline will return this error: “This Delta Live Tables query is syntactically valid, but you must create a pipeline in order to define and populate your table.”
Your next step
- Open Workflows from the left navigation menu


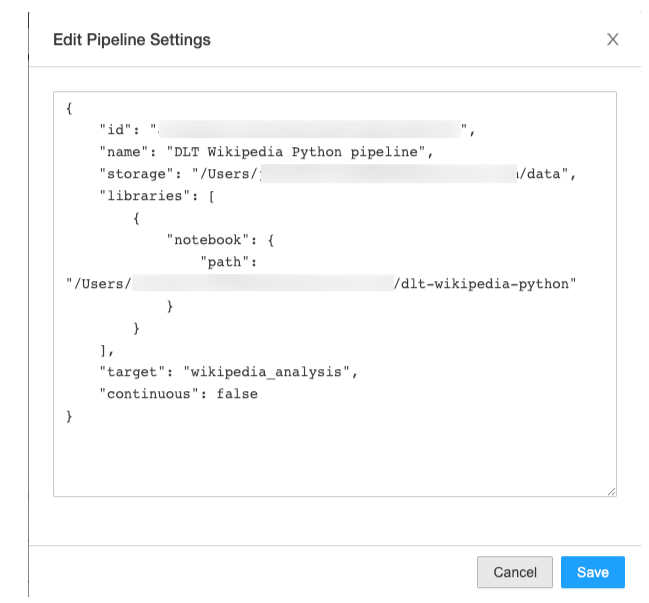
- Create your pipeline and select the notebook you just created with one line of code
- Setup access to your storage location using instance profiles (recommended for production) or keys and secrets (see Tip #3).
- Start your pipeline in DLT. Remember, you won’t need to run the notebook, DLT will.
More resources









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}