Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Delta table upsert - databricks community
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2022 04:35 AM
Hello guys,
I'm trying to use upsert via delta lake following the documentation, but the command doesn't update or insert newlines.
scenario: my source table is separated in bronze layer and updates or inserts are in silver layer.
from delta.tables import *
deltaTableVendas = DeltaTable.forPath(spark, '/user/hive/warehouse/bronze.db/vendas')
deltaTableVendasUpdates = DeltaTable.forPath(spark, '/user/hive/warehouse/silver.db/vendas')
dfUpdates = deltaTableVendasUpdates.toDF()
deltaTableVendas.alias('vendas') \
.merge(
dfUpdates.alias('updates'),
'vendas.numero_transacao = updates.numero_transacao'
) \
.whenMatchedUpdate(set =
{
"numero_transacao": "updates.numero_transacao",
"numped": "updates.numped",
"codcli": "updates.codcli",
"codprod": "updates.codprod",
"data_venda": "updates.data_venda",
"quantidade": "updates.quantidade",
"valor": "updates.valor"
}
) \
.whenNotMatchedInsert(values =
{
"numero_transacao": "updates.numero_transacao",
"numped": "updates.numped",
"codcli": "updates.codcli",
"codprod": "updates.codprod",
"data_venda": "updates.data_venda",
"quantidade": "updates.quantidade",
"valor": "updates.valor"
}
) \
.execute()
Labels:
- Labels:
-
Delta
-
Delta Lake Upsert
-
Source Table
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 05:55 AM
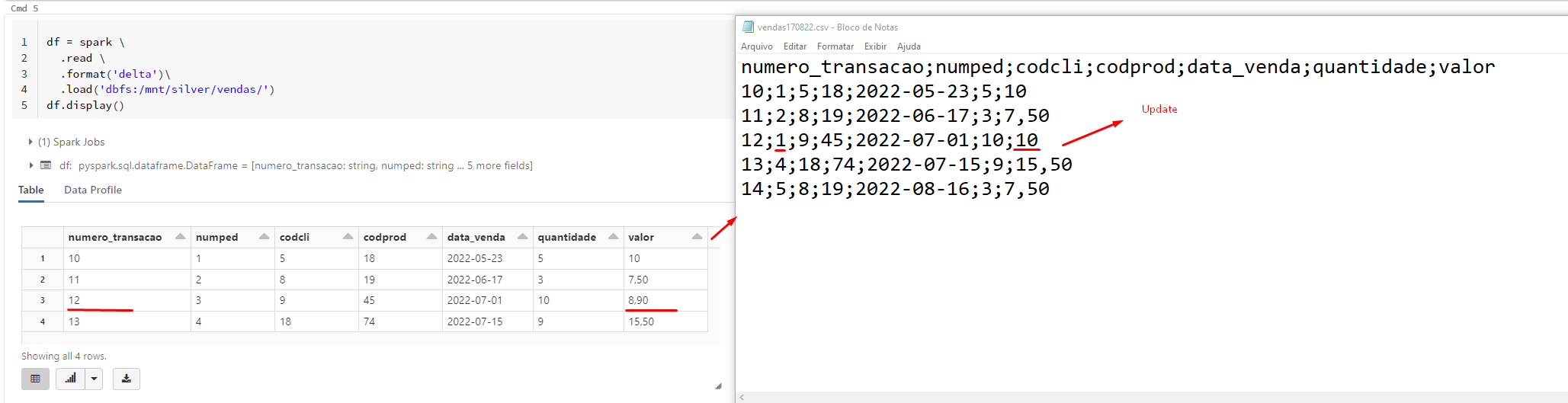
Right now I am kinda confused what you try to do.
In your code, you are merging the bronze table with data from the silver table (so the bronze table is updated), but you post screenshots of the silver table, which does not change.
And that is normal because the data is updated in the bronze table in your code.
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-19-2022 09:35 AM
@Hubert Dudek , @Werner Stinckens
Do you have any idea what's going on in this case?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-21-2022 11:13 PM
is that the actual location of the data in the delta lake table? seems like a weird place.
The forPath parameter expects the storage location where the data is stored. You point to the location where hive stores its metadata.
Normally this is something like "/mnt/datalake/bronze/deltatable" or something.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 05:41 AM



Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 05:55 AM
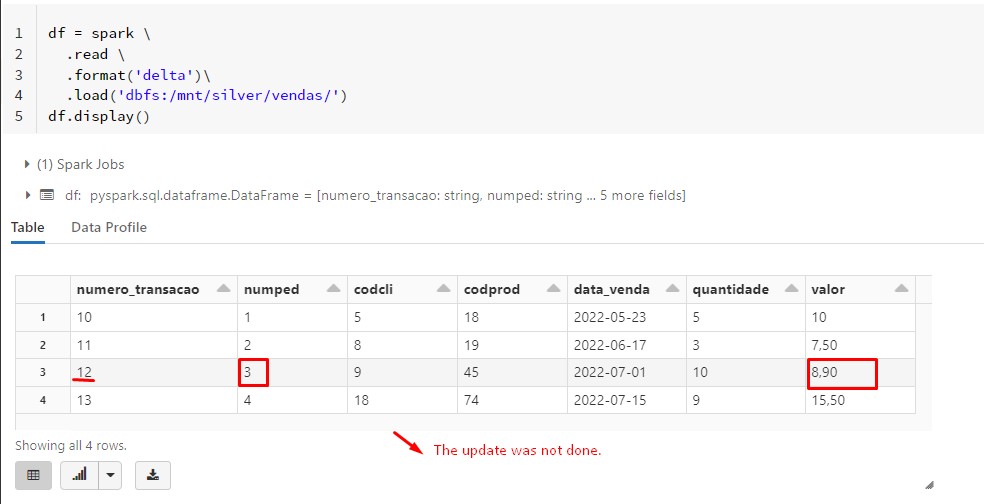
Right now I am kinda confused what you try to do.
In your code, you are merging the bronze table with data from the silver table (so the bronze table is updated), but you post screenshots of the silver table, which does not change.
And that is normal because the data is updated in the bronze table in your code.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 06:56 AM
@Werner Stinckens In fact, the information is inserted in the bronze table, in the silver layer it would receive the update or insertion of the bronze table.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 07:01 AM
ok so if the bronze table contains the new updated data which you want to propagate to the silver table, you should create a df with the updates from the bronze table (you use the silver table for that)
Next do a merge into silver table using updates (bronze).
That should work.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 07:08 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 11:55 AM
I managed to find the solution. In insert and update I was setting the target.
tanks @Werner Stinckens !
delta_df = DeltaTable.forPath(spark, 'dbfs:/mnt/silver/vendas/')
delta_df.alias('target').merge(
source = bronzedf.alias("source"),
condition = 'target.numero_transacao = source.numero_transacao'
) \
.whenMatchedUpdate(set =
{
"numero_transacao": "source.numero_transacao",
"numped": "source.numped",
"codcli": "source.codcli",
"codprod": "source.codprod",
"data_venda": "source.data_venda",
"quantidade": "source.quantidade",
"valor": "source.valor"
}
) \
.whenNotMatchedInsert(values =
{
"numero_transacao": "source.numero_transacao",
"numped": "source.numped",
"codcli": "source.codcli",
"codprod": "source.codprod",
"data_venda": "source.data_venda",
"quantidade": "source.quantidade",
"valor": "source.valor"
}
) \
.execute()Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-23-2022 12:29 AM
That is what I was trying to explain. Nice you got it working!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Optimal Cluster Configuration for Training on Billion-Row Datasets in Machine Learning
- Passing Parameters from Azure Synapse in Data Engineering
- Databricks Model Registry Notification in Data Engineering
- What is the bestway to handle huge gzipped file dropped to S3 ? in Data Engineering
- DBAcademy DLT cluster policy missing, &No permission to run Workspace-Setup in Data Engineering