Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Why does @dlt.table from a table give different re...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-29-2022 08:49 AM
I have some data in silver that I read in as a view using the __apply_changes function on. I create a table based on this, and I then want to create my gold-table, after doing a .groupBy() and .pivot(). The transformations I do in the gold-table aren't giving my any error messages, they simply aren't being done. If I create my gold-table based on a view instead of a table, the transformations are done. See bottom for fabricated example.
Here's my code:
import dlt
from pyspark.sql.functions import col, concat_ws, explode, split, explode_outer, posexplode, concat, lit, expr, first, create_map
@dlt.view
def silver_messages():
"""Silver messages table"""
return spark.readStream.table("eqs_cloud.__apply_changes_storage_silver_messages")
@dlt.view
def groups_hierarchy_vw():
"""Get all groups' hierarchy"""
assigned = dlt.read_stream("silver_messages").select("assignedToUnit.*")
from_unit = dlt.read_stream("silver_messages").select("fromUnit.*")
to_unit = dlt.read_stream("silver_messages").select("toUnit.*")
groups_hierarchy_vw = assigned.unionByName(from_unit).unionByName(to_unit)
return groups_hierarchy_vw
@dlt.table
def groups_hierarchy_tbl():
return dlt.read_stream("groups_hierarchy_vw")
@dlt.table
def groups_hierarchy_tbl_pivoted():
return(dlt.read("groups_hierarchy_tbl")
.select(
"id",
"name",
split("path","/").alias("groups_in_path"),
posexplode(split("path","/")).alias("pos","value"))
.select(
"id",
"name",
concat(lit("group"),"pos").alias("group_name"),
expr("groups_in_path[pos]").alias("val"))
.groupBy("id", "name")
.pivot("group_name")
.agg(first("val"))
)Is there a way I can use the groups_hierarchy_vw view directly in the gold-table at the bottom? If I enter it with dlt.read_stream("groups_hierarchy_vw") I get an error "pyspark.sql.utils.AnalysisException: Queries with streaming sources must be executed with writeStream.start();"
Here's a fabricated example you can try out.
import pandas as pd
from pyspark.sql.functions import col, concat_ws, explode, split, explode_outer, posexplode, concat, lit, expr, first, create_map
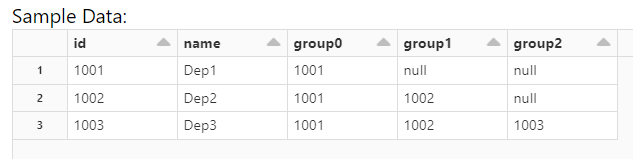
pdf = pd.DataFrame({"id": ["1001", "1002", "1003"],
"name": ["Dep1", "Dep2", "Dep3"],
"path": ["1001", "1001/1002", "1001/1002/1003"]
})
df = spark.createDataFrame(pdf)
df.write.mode('overwrite').saveAsTable('fabricated_testtable')
@dlt.view
def fabricated_hierarchy_vw():
return spark.read.table('fabricated_testtable')
@dlt.table
def fabricated_tbl_pivoted():
return (dlt.read('fabricated_hierarchy_vw')
.select(
"id",
"name",
split("path","/").alias("groups_in_path"),
posexplode(split("path","/")).alias("pos","value"))
.select(
"id",
"name",
concat(lit("group"),"pos").alias("group_name"),
expr("groups_in_path[pos]").alias("val"))
.groupBy("id", "name")
.pivot("group_name")
.agg(first("val"))
)This gives the expected outcome:

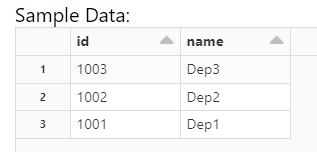
But if you change line 12 to @dlt.table, the transformations are not performed and the outcome is this:

Labels:
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2022 03:44 AM
I have found a temporary solution to solve this.
The .pivot("columnName") should automatically grab all the values it can find, but for some reason it does not. I need to specify the values, using
.pivot("group_name", "group0", "group1", "group2"...)
or
.pivot("group_name", ["group{}".format(i) for i in range(8)])
1 REPLY 1
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2022 03:44 AM
I have found a temporary solution to solve this.
The .pivot("columnName") should automatically grab all the values it can find, but for some reason it does not. I need to specify the values, using
.pivot("group_name", "group0", "group1", "group2"...)
or
.pivot("group_name", ["group{}".format(i) for i in range(8)])



{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- I am getting NoneType error when running a query from API on cluster in Data Engineering
- Help with Identifying and Parsing Varying Date Formats in Spark DataFrame in Data Engineering
- Use OF API from package enerbitdso 0.1.8 PYPI in Machine Learning
- Move a delta table from a non UC metastore to a UC metastore preserving history in Data Engineering
- VIEW JSON result value in view which based on volume in Data Engineering