Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Fatal error: Python kernel is unresponsive
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Fatal error: Python kernel is unresponsive
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-07-2022 01:03 AM
Hey guys,
I'm using petastorm to train DNN, First i convert spark df with make_spark_convertor and then open a reader on the materialized dataset.
While i start training session only on subset of the data every thing works fine but when I'm using all dataset after about 500 batches my notebook crash with Python kernel is unresponsive, any of you know what this happening?
I saw kinda similar question already and i looked on thread dumps but didn't understood it to much.
Besides i get alot of future warning from petastorm about pyarrow, have any idea how to avoid all this warnings?
Labels:
- Labels:
-
Python
-
Python Kernel
25 REPLIES 25
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2022 12:14 AM
Same error. This started a few days ago on notebooks that used to run fine in the past. Now, I cannot finish a notebook.
I have already disabled almost all output being streamed to the result buffer, but the problem persists. I am left with <50 lines being logged/printed. If Databricks cannot handle such a minimal amount of output, it's not a usable solution.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-08-2022 07:13 AM
In my case, this turned out to be a memory issue. For whatever reason, Databricks doesn't properly raise a MemoryError. So you're kind of left hanging and have to figure it out yourself.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2022 08:19 AM
Thanks for sharing your findings. How did you determine this was a `MemoryError`?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2022 08:39 AM
I opened the terminal to the cluster and just monitored htop. I could see memory usage going up, hitting the limit, going into swap, and then dropping to a base level at the same time as the FatalError was raised.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-13-2022 06:20 AM
I also noticed the same behavior. How can we handle such a problem in your opinion? It would take something to manage the RAM...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 02:46 AM
Hey Guys,
While i was training i noticed two things that might cause the error.
The first one is after a training session was crashed, the GPU memory was almost full ( checked with nvidia smi command).
The second one is that i saw in gangila metrics a Swap above the total memory of the cluster.
In my use case i use make_reader from petastorm to read petastorm dataset and its default workers_count is 10, While i changed workers_count to 4 I didn't got any error.
I didn't figure out if I'm truly right and what the right way to overcome this,
Would like to hear you opnion,
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2022 02:52 AM
In my case I use a simple notebook with an OpenCV processing. The code is not yet optimized to run on a cluster (I use a Single Node for testing coupled with Synapse) however it seems absurd to me that the kernel crashes due to RAM filling up (I verified this via the cluster monitoring panel).
Do you think it is possible to define a "max RAM usage" per notebook somewhere?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2022 10:17 AM
Hey @Alessio Vaccaro , Sorry for the really delayed response 😅
I didn't find any documentation or any good resource of this.
I would hope that if only 1 notebook is attached to a cluster, this notebook can use all the RAM - memory allocated for spark driver, when more notebooks are attached then some mechanism to handle it start to work.
Actually i saw a databricks blog that say "Fatal error: The Python kernel is unresponsive." is an error cause because out of RAM
you can see the blog here:
Accelerating Your Deep Learning with PyTorch Lightning on Databricks - The Databricks Blog
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-23-2022 11:04 PM
Hi @orian hindi
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-25-2022 10:39 AM
Hey @Vidula Khanna
I found a workaround, I created a job that run the notebook. ( with cluster spec and not with existing cluster - which cost cheaper)
I think when a notebook is attached to existing cluster a lot of state of it saved which fill the RAM or there is some mechanism that starts to work on allocating memory to this and any other notebook that might come ,
When i run the notebook from a job, the memory being used was cut down by half and the run finished without any errors.
But for sure, this error is caused by out of RAM: link here
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2022 07:53 PM
@Vidula Khanna
@orian hindi
Today, I tried to transpose a big data set (Row: 252x17 Columns:1000). 999 columns are structured numerical float data and 1 column is a DateTime data type.
I deployed Standard_E4ds_v4 in Azure Databricks. That should be enough for transposing the big data.
Here is the code:
df_sp500_elements.pandas_api().set_index('stock_dateTime').T.reset_index().rename(columns={"index":"stock_dateTime"}).to_spark().show()However, after running for 14.45 hours, there is still a `Fatal error: The Python kernel is unresponsive`.
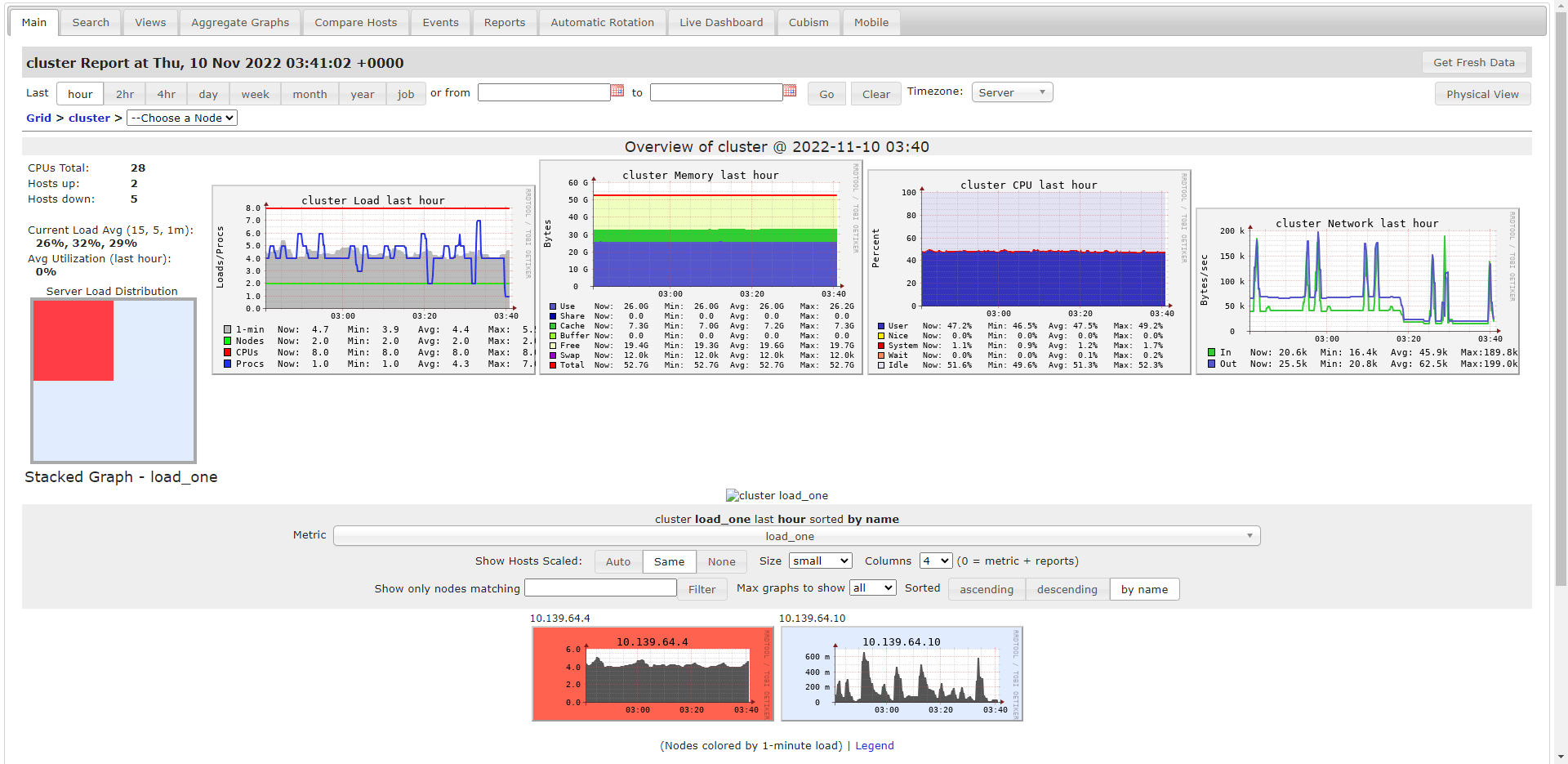
This is the Ganglia:: cluster Report during transposition ::

This is the Event log`:

I think the `Fatal error: The Python kernel is unresponsive` is not caused by insufficient RAM.
This is my full `Fatal error: The Python kernel is unresponsive.` error message:
---------------------------------------------------------------------------
The Python process exited with an unknown exit code.
The last 10 KB of the process's stderr and stdout can be found below. See driver logs for full logs.
---------------------------------------------------------------------------
Last messages on stderr:
Wed Nov 9 12:46:54 2022 Connection to spark from PID 933
Wed Nov 9 12:46:54 2022 Initialized gateway on port 34615
Wed Nov 9 12:46:55 2022 Connected to spark.
/databricks/spark/python/pyspark/sql/dataframe.py:3605: FutureWarning: DataFrame.to_pandas_on_spark is deprecated. Use DataFrame.pandas_api instead.
warnings.warn(
ERROR:root:KeyboardInterrupt while sending command.
Traceback (most recent call last):
File "/databricks/spark/python/pyspark/sql/pandas/conversion.py", line 364, in _collect_as_arrow
results = list(batch_stream)
File "/databricks/spark/python/pyspark/sql/pandas/serializers.py", line 56, in load_stream
for batch in self.serializer.load_stream(stream):
File "/databricks/spark/python/pyspark/sql/pandas/serializers.py", line 112, in load_stream
reader = pa.ipc.open_stream(stream)
File "/databricks/python/lib/python3.9/site-packages/pyarrow/ipc.py", line 154, in open_stream
- return RecordBatchStreamReader(source)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2022 10:24 AM
I think deploying a larger VM with more memory may work. In the ML case, deploying one big VM is better. But Spark workers will also spill the data on disk if the dataset is larger than the memory size. So why is there a memory problem? Is there any specific operation that the spark workers don't split data on disk?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2022 01:27 AM
Hey @Cheuk Hin Christophe Poon
You shared a screenshot of the whole cluster RAM usage, can you please look only on the driver metrics and check only his RAM usage ?
In my case the cluster metrics looked fine but when check only the driver i saw that my RAM got explode.
Besides this, I'm not sure if .pandas_api() collect all the data into driver, so you may want to check this.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2022 02:26 AM
@orian hindi
Not only using pandas_api(), using spark also causes high used memory.
Announcements




{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- "Fatal error: The Python kernel is unresponsive." DBR 14.3 in Data Engineering
- Fatal error when writing a big pandas dF in Data Engineering
- Received Fatal error: The Python kernel is unresponsive. in Machine Learning
- How to restart the kernel on my notebook in databricks? in Data Engineering
- Integration options for Databricks Jobs and DataDog? in Data Engineering