Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- spark sql update really slow
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-07-2022 08:11 PM
I tried to use Spark as much as possible but experience some regression. Hopefully to get some direction how to use it correctly.
I've created a Databricks table using spark.sql
spark.sql('select * from example_view ') \
.write \
.mode('overwrite') \
.saveAsTable('example_table')and then I need to patch some value
%sql
update example_table set create_date = '2022-02-16' where id = '123';
update example_table set create_date = '2022-02-17' where id = '124';
update example_table set create_date = '2022-02-18' where id = '125';
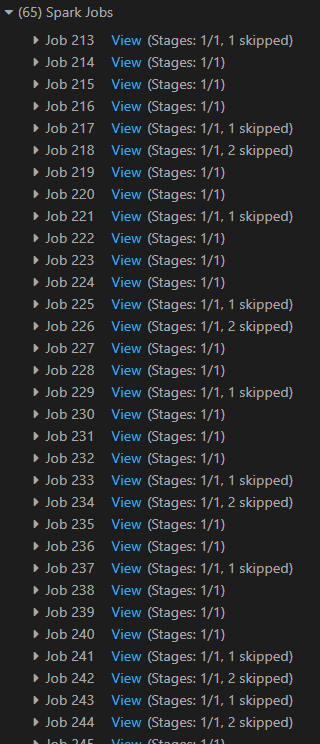
update example_table set create_date = '2022-02-19' where id = '126';However, I found this awlfully slow since it created hundreds of spark jobs:

Labels:
- Labels:
-
Databricks table
-
Slow
-
Spark
-
Sparkdataframe
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2022 12:00 AM
Hi, @Vincent Doe ,
Updates are available in Delta tables, but under the hood you are updating parquet files, it means that each update needs to find the file where records are stored, then re-write the file to new version, and make new file current version.
In your case maybe you should try something like this:
spark.sql("""
select
col1,
col2,
col3,
case
when id = '123' then '2022-02-16'
when id = '124' then '2022-02-17'
end as create_date
...
from example_view
""") \
.write \
.mode('overwrite') \
.saveAsTable('example_table')
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2022 12:00 AM
Hi, @Vincent Doe ,
Updates are available in Delta tables, but under the hood you are updating parquet files, it means that each update needs to find the file where records are stored, then re-write the file to new version, and make new file current version.
In your case maybe you should try something like this:
spark.sql("""
select
col1,
col2,
col3,
case
when id = '123' then '2022-02-16'
when id = '124' then '2022-02-17'
end as create_date
...
from example_view
""") \
.write \
.mode('overwrite') \
.saveAsTable('example_table')Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2022 06:26 PM
@Pat Sienkiewicz . That's good tips. Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-09-2022 07:02 AM
Hi @Vincent Doe , It would mean a lot if you could select the "Best Answer" to help others find the correct answer faster.
This makes that answer appear right after the question, so it's easier to find within a thread.
It also helps us mark the question as answered so we can have more eyes helping others with unanswered questions.
Can I count on you?



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Fitspresso (May Update 2024) in Administration & Architecture
- DLT run filas with "com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider not found" in Data Engineering
- Performance Issue with XML Processing in Spark Databricks in Data Engineering
- DLT Pipeline Error Handling in Data Engineering
- Optimal Cluster Configuration for Training on Billion-Row Datasets in Machine Learning