Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- How to read JSON files embedded in a list of lists...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-16-2022 05:24 AM
Hello
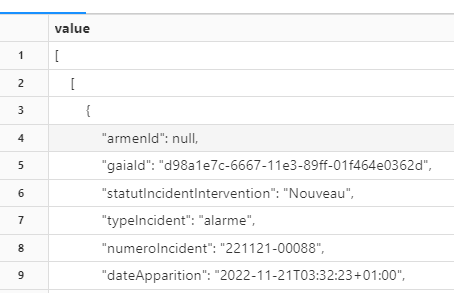
I am trying to read this JSON file but didn't succeed


You can see the head of the file, JSON inside a list of lists. Any idea how to read this file?

Labels:
- Labels:
-
File
-
JSON
-
JSON Files
-
Jsonfile
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:51 AM
Here is my solution, I am sure it can be optimized
import json
data=[]
with open(path_to_json_file, 'r') as f:
data.extend(json.load(f))
df = spark.createDataFrame(data[0], schema=schema)✌️
7 REPLIES 7
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 11:31 PM
Hi @Amine HADJ-YOUCEF , The data sources are limited, please refer: https://spark.apache.org/docs/latest/sql-data-sources-json.html#data-source-option
Also, https://docs.databricks.com/external-data/json.html
Please let us know if this helps.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2022 12:23 AM
Hi @Amine HADJ-YOUCEF, Please see these threads which have a solution to similar queries and LMK if that helps:-
- https://stackoverflow.com/questions/66108297/spark-how-to-parse-json-string-of-nested-lists-to-spark-data-frame
- https://stackoverflow.com/questions/63502556/pyspark-read-nested-json-from-a-string-type-column-and-...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:04 AM
Thank you for sharing,
these links do not address the exact problem I am facing
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-20-2022 11:11 PM
Hi @Amine HADJ-YOUCEF, We haven’t heard from you since the last response from @Debayan Mukherjee and me, and I was checking back to see if our suggestions helped you.
Or else, If you have any solution, please share it with the community, as it can be helpful to others.
Also, Please don't forget to click on the "Select As Best" button whenever the information provided helps resolve your question.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:06 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:51 AM
Here is my solution, I am sure it can be optimized
import json
data=[]
with open(path_to_json_file, 'r') as f:
data.extend(json.load(f))
df = spark.createDataFrame(data[0], schema=schema)✌️
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 11:15 AM
Hi @Amine HADJ-YOUCEF, Thank you for sharing the solution with the community!
Announcements




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Ingesting Files - Same file name, modified content in Data Engineering
- Databricks Autoloader - list only new files in an s3 bucket/directory in Data Engineering
- Is there a way to configure a cluster to have no internet access? in Administration & Architecture
- Error "Invalid configuration value detected for fs.azure.account.key" when listing files stored in an Azure Storage account using "dbutils.fs.ls" in Machine Learning
- When should you use the directory listing vs file notification in Machine Learning