Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Date field getting changed when reading from excel...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Date field getting changed when reading from excel file to dataframe in pyspark
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 10:40 PM
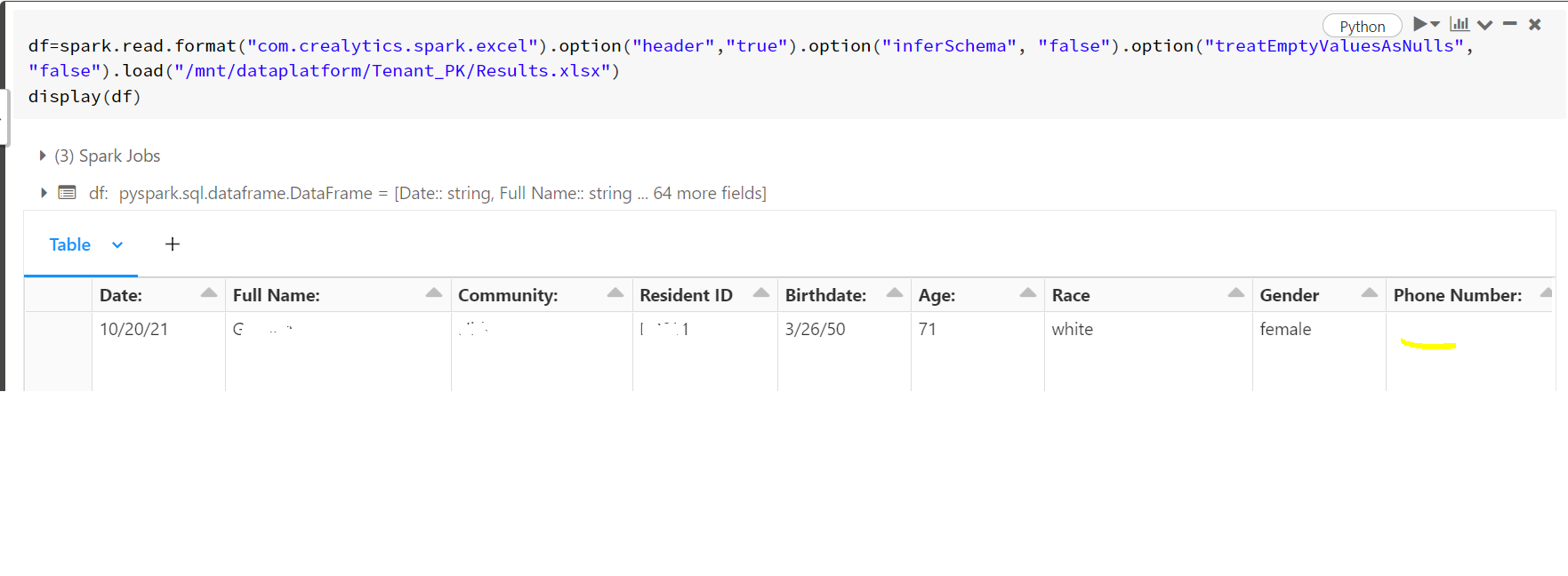
The date field is getting changed while reading data from source .xls file to the dataframe. In the source xl file all columns are strings but i am not sure why date column alone behaves differently
In Source file date is 1/24/1947.
In pyspark dataframe it is 1/24/47
Code used:
df=spark.read.format("com.crealytics.spark.excel").option("header","true").load("/mnt/dataplatform/Tenant_PK/Results.xlsx")
If I use option("inforscheme","true") the data coming properly , but I dont want use inforschema, Can any one suggest me any solution.
Thanks in advance
Labels:
- Labels:
-
Date
-
Date Field
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 10:52 PM
hi @Pradeep Namani ,
could you plz try to run below one. I hope so it will work without inferschema
df=spark.read.format("csv").option("header","true").load("/mnt/dataplatform/Tenant_PK/Results.xlsx")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 11:12 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 11:13 PM
also u can refer below one
https://mayur-saparia7.medium.com/reading-excel-file-in-pyspark-databricks-notebook-c75a63181548
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2022 03:08 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-24-2022 02:37 AM
how about using inferschema one single time to create a correct DF, then create a schema from the df-schema.
something like this f.e.
from pyspark.sql.types import StructType
# Save schema from the original DataFrame into json:
schema_json = df.schema.json()
# Restore schema from json:
import json
new_schema = StructType.fromJson(json.loads(schema_json))
Announcements





{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Infer schema eliminating leading zeros. in Data Engineering
- Help with Identifying and Parsing Varying Date Formats in Spark DataFrame in Data Engineering
- Databricks-connect OpenSSL Handshake failed on WSL2 in Data Engineering
- When reading a csv file with Spark.read, the data is not loading in the appropriate column while pas in Data Engineering
- Write to csv file in S3 bucket in Data Engineering