Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Pyspark Pandas column or index name appears to per...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Pyspark Pandas column or index name appears to persist after being dropped or removed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 07:05 AM
So, I have this code for merging dataframes with pyspark pandas. And I want the index of the left dataframe to persist throughout the joins. So following suggestions from others wanting to keep the index after merging, I set the index to a column before the merge, and then bring it back to index after the merge and remove the index name.
import pyspark.pandas as ps
def merge_dataframes(left=None, right=None, how='inner', on=None, left_on=None,
right_on=None, left_index=False, right_index=False):
merging_left = left.copy()
merging_left['weird_index_name'] = merging_left.index
new_df = merging_left.merge(right, on=on, how=how, left_on=left_on, right_on=right_on, suffixes=('', '_dupe_right'),
left_index=left_index, right_index=right_index)
returning_df = new_df.set_index('weird_index_name')
returning_df.index.name = None
return returning_df
df_1 = ps.DataFrame({
'join_column': [1, 2, 3, 4],
'value1': ['A', 'B', 'C', 'D']
}, index=['Index1', 'Index2', 'Index3', 'Index4'])
df_2 = ps.DataFrame({
'join_column': [1, 2, 3, 4, 5],
'value2': ['a', 'b', 'c', 'd', 'e']
})
df_3 = ps.DataFrame({
'join_column': [1, 2, 3, 4, 6, 7],
'value3': [1.1, 2.2, 3.3, 4.4, 6.6, 7.7]
})
input_list = [df_1, df_2, df_3]
expected_result = ps.DataFrame({
'join_column': [1, 2, 3, 4],
'value1': ['A', 'B', 'C', 'D'],
'value2': ['a', 'b', 'c', 'd'],
'value3': [1.1, 2.2, 3.3, 4.4]
}, index=['Index1', 'Index2', 'Index3', 'Index4'])
final_df = input_list[0]
for next_df in input_list[1:]:
final_df = merge_dataframes(left=final_df, right=next_df, how='left', on='join_column')
print(final_df)This works perfectly fine for merging two dataframes but as soon as I have a list of dataframes to be merged together using a for loop. I get this error:
AnalysisException Traceback (most recent call last)
<command-1950358519842329> in <module>
42 final_df = input_list[0]
43 for next_df in input_list[1:]:
---> 44 final_df = merge_dataframes(left=final_df, right=next_df, how='left', on='join_column')
45
46 print(final_df)
<command-1950358519842329> in merge_dataframes(left, right, how, on, left_on, right_on, left_index, right_index)
7 merging_left['weird_index_name'] = merging_left.index
8
----> 9 new_df = merging_left.merge(right, on=on, how=how, left_on=left_on, right_on=right_on, suffixes=('', '_dupe_right'),
10 left_index=left_index, right_index=right_index)
11
/databricks/spark/python/pyspark/pandas/usage_logging/__init__.py in wrapper(*args, **kwargs)
192 start = time.perf_counter()
193 try:
--> 194 res = func(*args, **kwargs)
195 logger.log_success(
196 class_name, function_name, time.perf_counter() - start, signature
/databricks/spark/python/pyspark/pandas/frame.py in merge(self, right, how, on, left_on, right_on, left_index, right_index, suffixes)
7655 )
7656
-> 7657 left_internal = self._internal.resolved_copy
7658 right_internal = resolve(right._internal, "right")
7659
/databricks/spark/python/pyspark/pandas/utils.py in wrapped_lazy_property(self)
578 def wrapped_lazy_property(self):
579 if not hasattr(self, attr_name):
--> 580 setattr(self, attr_name, fn(self))
581 return getattr(self, attr_name)
582
/databricks/spark/python/pyspark/pandas/internal.py in resolved_copy(self)
1169 return self.copy(
1170 spark_frame=sdf,
-> 1171 index_spark_columns=[scol_for(sdf, col) for col in self.index_spark_column_names],
1172 data_spark_columns=[scol_for(sdf, col) for col in self.data_spark_column_names],
1173 )
/databricks/spark/python/pyspark/pandas/internal.py in <listcomp>(.0)
1169 return self.copy(
1170 spark_frame=sdf,
-> 1171 index_spark_columns=[scol_for(sdf, col) for col in self.index_spark_column_names],
1172 data_spark_columns=[scol_for(sdf, col) for col in self.data_spark_column_names],
1173 )
/databricks/spark/python/pyspark/pandas/utils.py in scol_for(sdf, column_name)
590 def scol_for(sdf: SparkDataFrame, column_name: str) -> Column:
591 """Return Spark Column for the given column name."""
--> 592 return sdf["`{}`".format(column_name)]
593
594
/databricks/spark/python/pyspark/sql/dataframe.py in __getitem__(self, item)
1775 """
1776 if isinstance(item, str):
-> 1777 jc = self._jdf.apply(item)
1778 return Column(jc)
1779 elif isinstance(item, Column):
/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
121 # Hide where the exception came from that shows a non-Pythonic
122 # JVM exception message.
--> 123 raise converted from None
124 else:
125 raise
AnalysisException: Reference 'weird_index_name' is ambiguous, could be: weird_index_name, weird_index_name.From my understanding this suggests there is another column called "weird_index_name". However, displaying the dataframe before going into the merge I get a dataframe where there is only one column "weird_index_name" on both calls of the function.
This led me to think that "weird_index_name" persists as the index name after:
returning_df = new_df.set_index('weird_index_name')
returning_df.index.name = NoneHowever, printing out the returning_df.index.name returns None after the merge of the first two dataframes, before the second call of the function. This is also true when printing the merging_left.index.name before the second call of the function.
If I introduce this line before the merge:
print(merging_left.index.to_list())The merge of the first two dataframes works and then I get this error when trying to join on the third (second call of the function) at that line:
Length mismatch: Expected axis has 5 elements, new values have 4 elementsThis leads me to believe there is an issue with the index and "weird_index_name" somehow persists.
Any help would be appreciated!!
Labels:
- Labels:
-
Index
-
Pandas
-
Pandas API
-
Print
-
Pyspark
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:41 AM
This worked for me:
import pandas as ps
def merge_dataframes(left=None, right=None, how='inner', on=None, left_on=None,
right_on=None, left_index=False, right_index=False):
merging_left = left.copy()
merging_left['weird_index_name'] = merging_left.index
new_df = merging_left.merge(right, on=on, how=how, left_on=left_on, right_on=right_on, suffixes=('', '_dupe_right'),
left_index=left_index, right_index=right_index)
returning_df = new_df.set_index('weird_index_name')
returning_df.index.name = None
return returning_df
df_1 = ps.DataFrame({
'join_column': [1, 2, 3, 4],
'value1': ['A', 'B', 'C', 'D']
}, index=['Index1', 'Index2', 'Index3', 'Index4'])
df_2 = ps.DataFrame({
'join_column': [1, 2, 3, 4, 5],
'value2': ['a', 'b', 'c', 'd', 'e']
})
df_3 = ps.DataFrame({
'join_column': [1, 2, 3, 4, 5, 6],
'value3': [1.1, 2.2, 3.3, 4.4, 6.6, 7.7]
})
input_list = [df_1, df_2, df_3]
#print(type(input_list[0]))
final_df = input_list[0]
#print(final_df)
for next_df in input_list[1:]:
final_df = merge_dataframes(left=final_df, right=next_df, how='left', on='join_column')
print(final_df)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:55 AM
Yeah, I found it works perfectly fine in normal pandas but not in pyspark.pandas, ultimately, I want to use pyspark.pandas. Apologies, I should have included that in the original post. It appears to be a pyspark problem.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-31-2023 03:01 AM
Hi!
I tried debugging your code and I think that the error you get is simply because the column exists in two instances of your dataframe within your loop.
I tried adding some extra debug lines in your merge_dataframes function:

Instead of running the loop, i broke the code down and try to run it piece by piece.
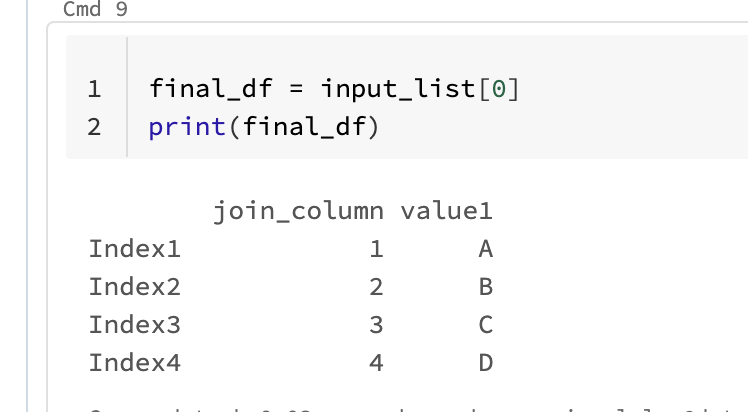
First lets load the first df:

Then lets use the merge trying to use the first element (1).

We can see that the "weird_index_name" gets created on this df.
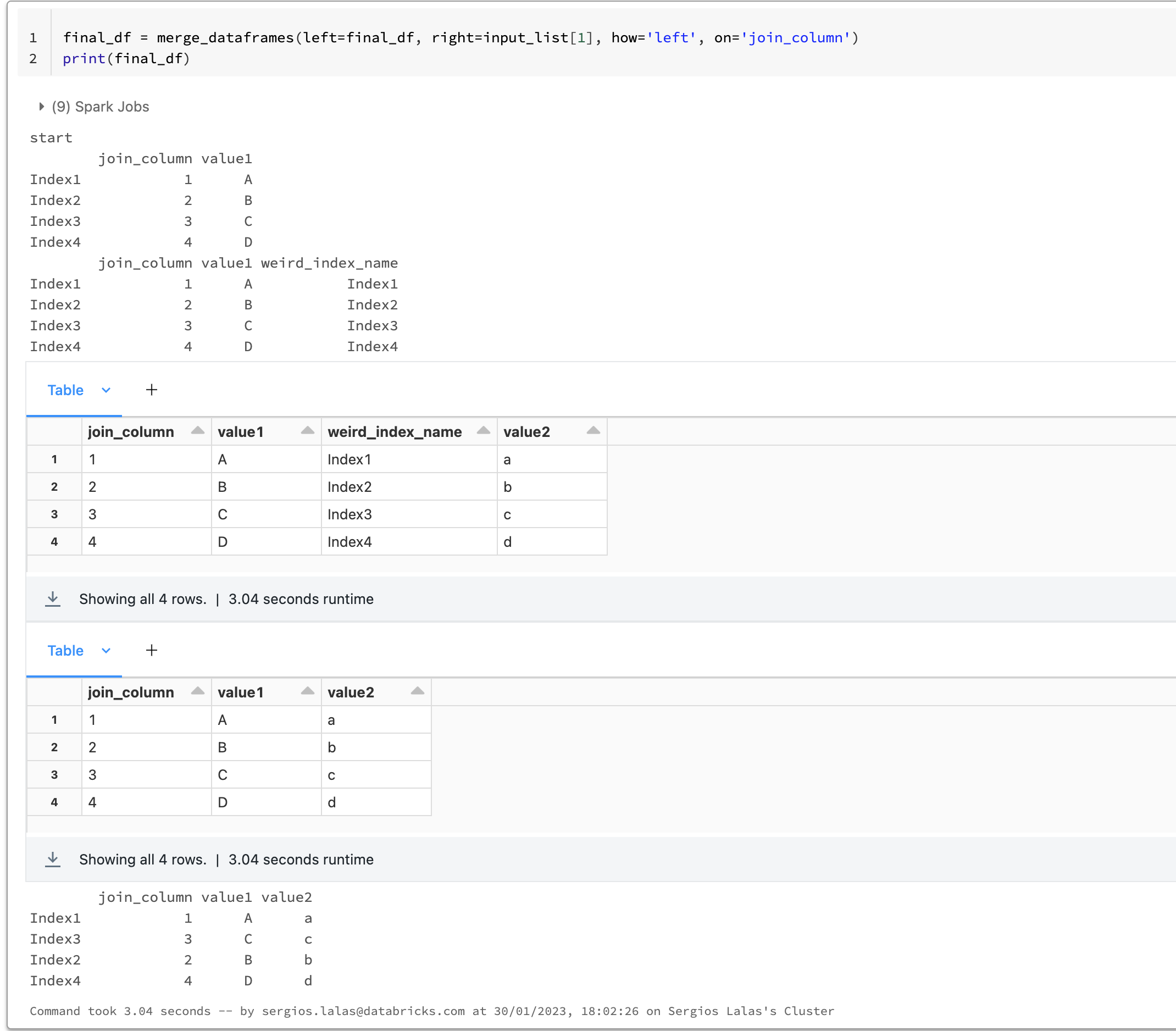
To show why it would fail, i will execute final_df = input_list[0] again to reinitialize the df and then run the merge on the second element instead:fi

You can see that in both cases the intermediate dataframe is created with the same column "weird_index_name" .
So if you try to run your original code, in the third iteration there is already a dataframe with this column which explains why you get the error: Reference 'weird_index_name' is ambiguous



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.