Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Scope creation in Databricks or Confluent?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:51 AM
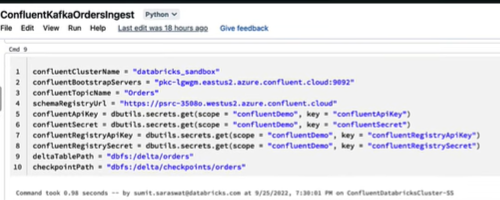
Hello I am a newbie in this field and trying to access confluent kafka stream in Databricks Azure based on a beginner's video by Databricks. I have a free trial of Databricks cluster right now. When I run the below notebook, it errors out on line 5 on scope.
My question is, should I create the scope in confluent or in Databricks. Has anybody seen this before?

Thanks so much!!
Julie
Labels:
- Labels:
-
Azure
-
Datadog
-
Kafka
-
Kafka Stream
-
Scope
-
Scope Creation
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:53 AM
For testing, create without secret scope. It will be unsafe, but you can post secrets as strings in the notebook for testing. Here is the code which I used for loading data from confluent:
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", host)
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(userid, password))
.option("subscribe", topic)
.option("kafka.client.id", "Databricks")
.option("kafka.group.id", "new_group2")
.option("spark.streaming.kafka.maxRatePerPartition", "5")
.option("startingOffsets", "earliest")
.option("kafka.session.timeout.ms", "10000")
.option("minPartitions", sc.DefaultParallelism)
.load() )
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 10:53 AM
For testing, create without secret scope. It will be unsafe, but you can post secrets as strings in the notebook for testing. Here is the code which I used for loading data from confluent:
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", host)
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(userid, password))
.option("subscribe", topic)
.option("kafka.client.id", "Databricks")
.option("kafka.group.id", "new_group2")
.option("spark.streaming.kafka.maxRatePerPartition", "5")
.option("startingOffsets", "earliest")
.option("kafka.session.timeout.ms", "10000")
.option("minPartitions", sc.DefaultParallelism)
.load() )Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 07:49 AM
Hey Hubert,
Firstly thanks for your response. Sure, I'll try this instead.
For line 11, kafka.group.id , that'll have to be from confluent cloud right?
Thanks,
Julie
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 07:53 AM
It is the name defined by you to control offset. I think that once you put in databricks code it will create it in kafka/confluent automatically.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 09:19 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-06-2023 09:24 AM
or does this even mean its able to access my topic?
Thanks for your time Hubert. I really appreciate it.
Julie



{kind=link}
{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- One-time backfill for DLT streaming table before apply_changes in Data Engineering
- Not able to create mount point in Databricks in Data Engineering
- User not authorised to copy files to dbfs in Administration & Architecture
- Ingesting geospatial data into a table in Data Engineering
- Databricks workspace creation using Terraform and storage configuration IAM Role Arn in Administration & Architecture