Hi all,
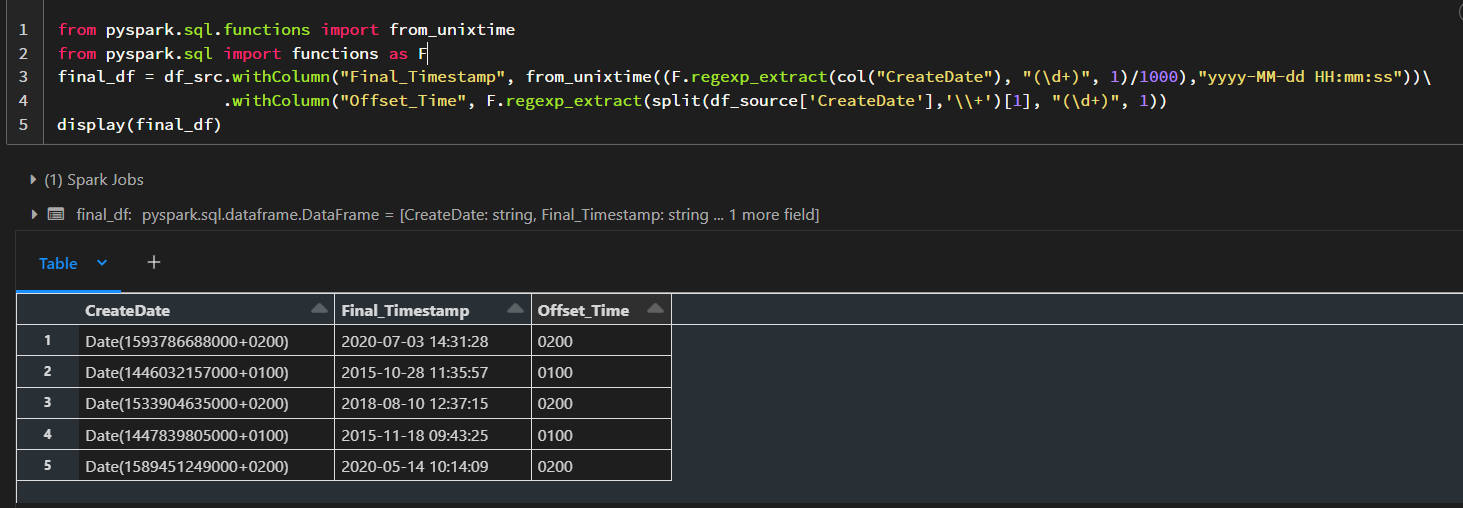
I've a dataframe with CreateDate column with this format:
CreateDate
/Date(1593786688000+0200)/
/Date(1446032157000+0100)/
/Date(1533904635000+0200)/
/Date(1447839805000+0100)/
/Date(1589451249000+0200)/
and I want to convert that format to date/timestamp, so the excepted output will be:
CreateDate
2020-07-03 14:31:28 +02:00
2015-10-28 11:35:57 +01:00
2018-08-10 12:37:15 +02:00
2015-11-18 09:43:25 +01:00
2020-05-14 10:14:09 +02:00
I have this query in SQL that gives the desired output and that can help to develop:
cast(convert(VARCHAR(30), DATEADD(Second, convert(BIGINT, left(replace(replace(CreateDate, '/date(', ''), ')/', ''), 13)) / 1000, '1970-01-01 00:00:00'), 20) + ' ' + '+' + left(right(replace(replace(CreateDate, '/date(', ''), ')/', ''), 4), 2) + ':' + right(replace(replace(CreateDate, '/date(', ''), ')/', ''), 2) AS DATETIMEOFFSET(0)) AS CreateDate
Can anyone please help me in achieving this?
Thank you!







{kind=link}
{kind=link}