Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- ApprodxQuantile does not seem to be working with d...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 08:41 AM
HI,
I am tying to use the approxQuantile() function and populate a list that I made, yet somehow, whenever I try to run the code it's as if the list is empty and there are no values in it.
Code is written as below:
@dlt.table(name = "customer_order_silver_v2")
def capping_unitPrice_Qt():
df = dlt.read("customer_order_silver")
boundary_unit = [0,0]
boundary_qty = [0,0]
boundary_unit = df.select(col("UnitPrice")).approxQuantile('UnitPrice',[0.05,0.95], 0.25)
boundary_qty = df.select(col("Quantity")).approxQuantile('Quantity',[0.05,0.95], 0.25)
df = df.withColumn('UnitPrice', F.when(col('UnitPrice') > boundary_unit[1], boundary_unit[1])
.when(col('UnitPrice') < boundary_unit[0], boundary_unit[0])
.otherwise(col('UnitPrice')))
df = df.withColumn('Quantity', F.when(col('Quantity') > boundary_qty[1], boundary_qty[1])
.when(col('Quantity') < boundary_qty[0], boundary_qty[0])
.otherwise(col('Quantity')))
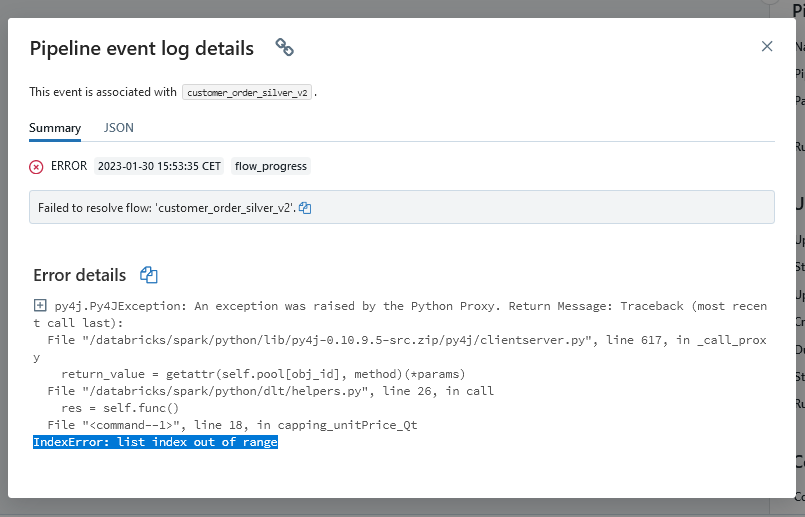
return dfThe output that I get when running is below:

Am I missing something somewhere? any advice or ideas are welcomed.
Labels:
- Labels:
-
Delta Live Tables
-
DLT
-
Hi
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:15 AM
Maybe try to use (and the first test in the separate notebook) standard df = spark.read.table("customer_order_silver") to calculate approxQuantile.
Of course, you need to set that customer_order_silver has a target location in the catalog, so read using regular spark.read will work.
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:15 AM
Maybe try to use (and the first test in the separate notebook) standard df = spark.read.table("customer_order_silver") to calculate approxQuantile.
Of course, you need to set that customer_order_silver has a target location in the catalog, so read using regular spark.read will work.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:18 AM
I see what you are suggesting, if I were to run it in the same notebook but in a different cell that is not a @dlt.table, will it work? I need to determine the quantiles and then use that to make changes to the table so that is why.
To read a delta live table do I just use spark.read.table("customer_order_silver")?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:22 AM
It will work inside def capping_unitPrice_Qt() I am using precisely the same approach.
To read a delta live table do I just use spark.read.table("customer_order_silver")?
Yes, if the table is registered in metastore. Usually, you prefix it with a database/schema name (so database.customer_order_silver). It is specified in DLT setting what is the name of the database.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:25 AM
what if this is not a database but another delta live table? do correct me if its the same thing. I really just started learning this tool and spark
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2023 10:34 AM
So I tried running the code inside the dlt function, it tells me that I cannot find the table now. Do I need to do anything to make it kknow where the table is? like add the path to it?
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Workflow file arrival trigger - does it apply to overwritten files? in Data Engineering
- Spark CSV file read option to read blank/empty value from file as empty value only instead Null in Data Engineering
- Databricks Connection to Redash in Data Engineering
- what config do we use to set row groups fro delta tables on data bricks. in Data Engineering
- Unity Catalog table management with multiple teams members in Machine Learning