Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Use JDBC connect to databrick default cluster and ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Use JDBC connect to databrick default cluster and read table into pyspark dataframe. All the column turned into same as column name
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-22-2023 11:45 AM
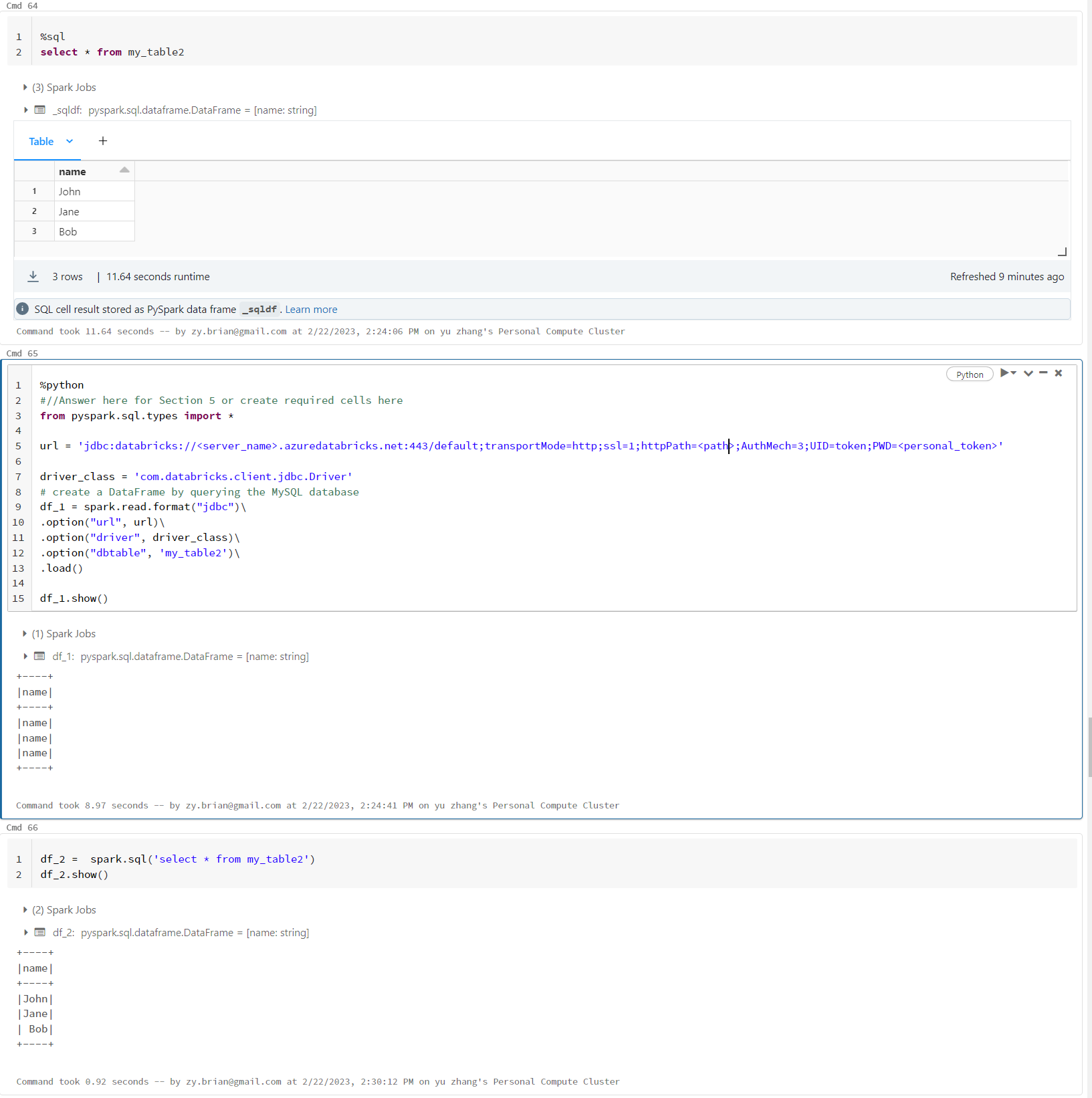
I used code like below to Use JDBC connect to databrick default cluster and read table into pyspark dataframe
url = 'jdbc:databricks://[workspace domain]:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=[path];AuthMech=3;UID=token;PWD=[your_access_token]'
driver_class = 'com.databricks.client.jdbc.Driver'
# create a DataFrame by querying the MySQL database
df_1 = spark.read.format("jdbc")\
.option("url", url)\
.option("driver", driver_class)\
.option("dbtable", 'my_table2')\
.load()
df_1.show()The final df_1 dataframe become
+----+
|name|
+----+
|name|
|name|
|name|
+----+the final result should be
+----+
|name|
+----+
|John|
|Jane|
|Bob |
+----+I also tested with code like
df_2 = spark.sql('select * from my_table2')
df_2.show()the result dataframe is correct. please advise. thank you!

Labels:
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-22-2023 08:24 PM
Hi @yu zhang
Just try to give your database name also into the code.
I am using same code with database name and it's working fine for me
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2023 07:57 AM
does pyspark.read.jdbc function has database name option? could you tell me how to give database name in this function. I think database name included in jdbc url option.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-24-2023 09:02 PM
@yu zhang :
It looks like the issue with the first code snippet you provided is that it is not specifying the correct query to retrieve the data from your database.
When using the load() method with the jdbc data source, you need to provide a SQL query in the
dbtable option that retrieves the data you want to load into the DataFrame.
Assuming that your my_table2 table contains a column named name with the values you listed, you can modify your code as follows to retrieve the correct data:
url = 'jdbc:databricks://[workspace domain]:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=[path];AuthMech=3;UID=token;PWD=[your_access_token]'
driver_class = 'com.databricks.client.jdbc.Driver'
# create a DataFrame by querying the MySQL database
df_1 = spark.read.format("jdbc")\
.option("url", url)\
.option("driver", driver_class)\
.option("dbtable", '(select name from my_table2) as tmp')\
.load()
df_1.show()This code passes a SQL query to the dbtable option that selects only the name column from your
my_table2 table. The resulting DataFrame should contain the data you expect.
Alternatively, you can use the spark.sql method to directly execute a SQL query against your database and load the results into a DataFrame, as you showed in your second code snippet:
df_2 = spark.sql('select * from my_table2')
df_2.show()This code should also retrieve the correct data from your database.



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- Help with Identifying and Parsing Varying Date Formats in Spark DataFrame in Data Engineering
- calculate the number of parallel tasks that can be executed in a Databricks PySpark cluster in Data Engineering
- Databricks-connect OpenSSL Handshake failed on WSL2 in Data Engineering
- When reading a csv file with Spark.read, the data is not loading in the appropriate column while pas in Data Engineering
- Write to csv file in S3 bucket in Data Engineering