Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- ignoreDeletes in DLT pipeline
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
ignoreDeletes in DLT pipeline
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-24-2023 05:10 AM
Hi all,
I have a DLT pipeline as so:
raw -> cleansed (SCD2) -> curated.
'Raw' is utilizing autoloader, to continously read file from a datalake. These files can contain tons of duplicate, which causes our raw table to become quite large. Therefore, we would like to truncate raw periodically to save storage size.
I have added 'pipelines.reset.allowed': 'false' to our cleansed table to ensure we dont lose our historical changes, i have also tried adding the ignoreDeletes parameter to both raw and cleansed without any success.
How should i organize my pipeline if I want to be able to periodically truncating the raw table?
Labels:
- Labels:
-
DLT
-
DLT Pipeline
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-24-2023 11:45 AM
Hi @Simon Kragh, If you need to truncate the raw table to save storage space periodically, you could consider modifying your DLT pipeline as follows:
- Create a new table to store the raw data.
- Use the autoloader to load data into the new raw table continuously.
- Set up a process to periodically move the data from the raw table to the cleansed table.
- Use a tool or script to periodically truncate the raw table after the data has been successfully loaded into the cleansed table.
By creating a new raw table and periodically truncating it, you can avoid losing historical data in the cleansed table. Additionally, this approach can help to manage storage space by removing duplicate data in the raw table.
Alternatively, you could consider implementing a data retention policy that removes old data from the raw table based on a specified time period. This approach would allow you to keep a certain amount of historical data in the raw table while still managing storage space.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-24-2023 11:57 AM
Hi Kaniz,
This is what I have today. We utilize the "apply_changes_into" to continuously move data into cleansed. The approach you are suggesting will not work, as it will trigger a warning that deletes have been detected in the source table, and DLT are append only. This will enforce a full refresh which will truncate the cleansed table where by we loose all historical data?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-24-2023 12:27 PM
Hi @Simon Kragh, If you need to maintain the historical data in the "cleansed" table, the DLT is append-only. You must find an alternative approach to update the data in the "cleansed" table without triggering a complete refresh. One potential strategy is to create a new table, "cleansed_temp", that mirrors the schema of "cleansed" but with a different name. Then, use "apply_changes_into" to continuously move data into "cleansed_temp". Once the data is successfully loaded into "cleansed_temp", you can then use a merge statement to update the data in the "cleansed" table with the new data from "cleansed_temp".
The merge statement will match records based on a unique key, allowing you to update existing records, add new forms, and preserve historical data. Once the merge is complete, you can drop the "cleansed_temp" table. This approach will avoid triggering a complete refresh of the "cleansed" table and allow you to maintain the historical data.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2023 12:04 PM
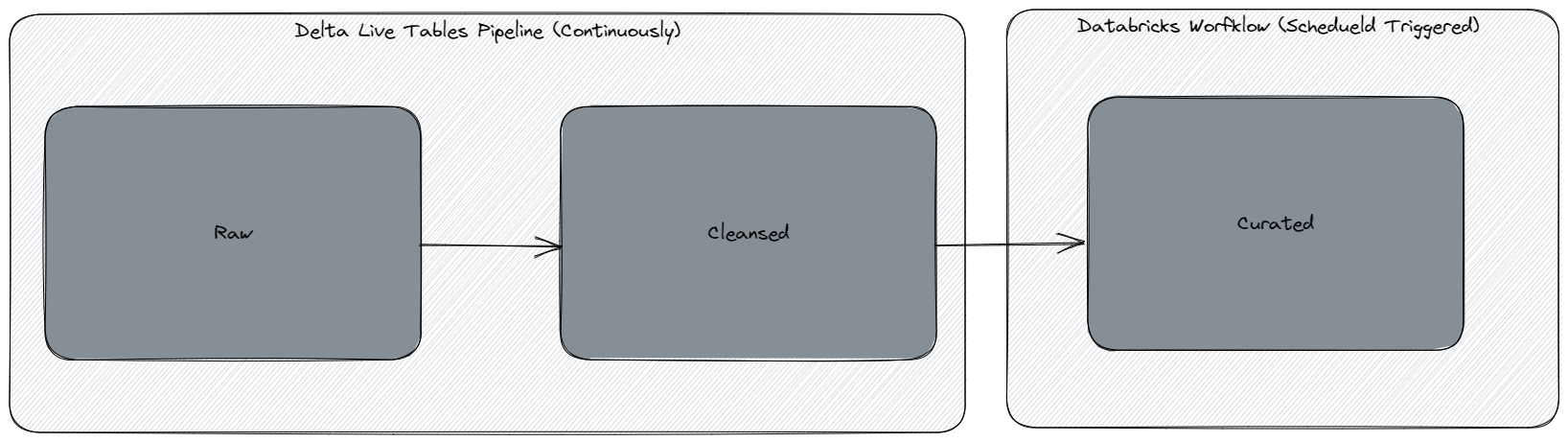
Ok, i'll try an add additional details. Firstly: The diagram below shows our current dataflow:

Our raw table is defined as such:
TABLES = ['table1','table2']
def generate_tables(table_name):
@dlt.table(
name=f'raw_{table_name}',
table_properties = {
'quality': 'bronze',
}
)
def create_table():
return (
spark.readStream.format('cloudfiles')
.option('cloudFiles.format', 'parquet')
.option('pathGlobfilter', '*.parquet')
.option("cloudFiles.useNotifications", "true")
.option('cloudFiles.clientId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-client-id'))
.option('cloudFiles.clientSecret', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-client-secret'))
.option('cloudFiles.connectionString', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-connection-string'))
.option('cloudFiles.resourceGroup', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-resource-group'))
.option('cloudFiles.subscriptionId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-subscription-id'))
.option('cloudFiles.tenantId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-tenant-id'))
.option('mergeSchema', 'true')
.load(f'dbfs:/mnt/raw/{table_name}/*.parquet')
.withColumn('Meta_SourceFile', input_file_name())
.withColumn('Meta_IngestionTS', current_timestamp())
)
for t in tables:
generate_tables(t)And our cleansed (SCD2) is created as such:
def generate_scd_tables(table_name, keys, seq_col, exc_cols, scd_type):
dlt.create_streaming_live_table(f'cleansed_{table_name}_scd{scd_type}',
table_properties = {
'delta.enableChangeDataFeed': 'true',
'pipelines.reset.allowed': 'false',
'quality': 'silver'
})
dlt.apply_changes(
target = f'cleansed_{table_name}_scd{scd_type}',
source = f'raw_{table_name}',
keys = keys,
sequence_by = col(seq_col),
track_history_except_column_list = exc_cols, #Input must be given as a list, .e.g ["Id"]
stored_as_scd_type = scd_type
)
generate_scd_tables(table_name='tabel1', keys=['Id'], seq_col='Meta_IngestionTS', exc_cols=['id', 'Meta_IngestionTS', 'Meta_SourceFile'], scd_type=2)Due to the volume of data we receive, we would like to truncate the raw table periodically. However, if we either delete or truncate the raw table as of now, the whole delta live pipeline will fail giving the following eror message: .from streaming source at version 191. This is currently not supported. If you'd like to ignore deletes, set the option 'ignoreDeletes' to 'true'
But how do we set that option? We have tried both on raw and SCD2 without any success. I would rather not introduce a temporary table as you suggest, as that table will not be realtime.



{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- DLT run filas with "com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider not found" in Data Engineering
- DLT Pipeline Error Handling in Data Engineering
- Variables passed from ADF to Databricks Notebook Try-Catch are not accessible in Data Engineering
- Why is Dlt pipeline processing streaming data so slow? in Data Engineering
- Help - org.apache.spark.SparkException: Job aborted due to stage failure: Task 47 in stage 2842.0 in Machine Learning