I need to execute a DLT pipeline from a Job, and I would like to know if there is any way of passing a parameter. I know you can have settings in the pipeline that you use in the DLT notebook, but it seems you can only assign values to them when crea...
I've created a streaming live table from a foreign catalog. When I run the DLT pipeline it fils with "com.databricks.cdc.spark.DebeziumJDBCMicroBatchProvider not found".I haven't seen any documentation that suggests I need to install Debezium manuall...
Hi friends -
To confirm, with new lakeview dashboards you can share dashboards to users and groups in your organization without having to provide any workspace and/or compute access.
https://docs.databricks.com/en/dashboards/index.html#what-is-shar...
I am reaching out to bring attention to a performance issue we are encountering while processing XML files using Spark-XML, particularly with the configuration spark.read().format("com.databricks.spark.xml").Currently, we are experiencing significant...
@amar1995 - Can you try this streaming approach and see if it works for your use case (using autoloader) - https://kb.databricks.com/streaming/stream-xml-auto-loader
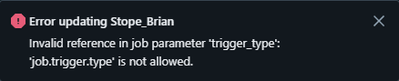
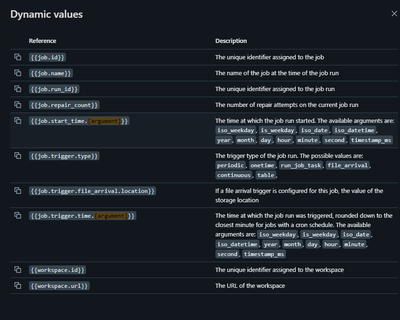
Following the instruction on the Job Parameter Dynamic values, I am able to use {{job.id}}{{job.name}}{{job.run_id}}{{job.repair_count}}{{job.start_time.[argument]}}However, when I set trigger_type as trigger_type: {{job.trigger.type}} and hit SAVE, ...
Good morning, I have a DLT process with CDC incremental load and I need to ingest the history as CDC transactions are only recent. To do this I need to ingest data in the __databricks_internal catalog. In my case, as I am full admin, I can do it, how...
Hi all,I have recently enabled Unity catalog in my DBX workspace. I have created a new catalog with an external location on Azure data storage.I can create new schemas(databases) in the new catalog but I can't create a table. I get the below error wh...
@Snoonan First of all, check the networking tab on the storage account to see if it's behind firewall. If it is, make sure that Databricks/Storage networking is properly configured (https://learn.microsoft.com/en-us/azure/databricks/security/network/...
I have a situation where source files in .json.gz sometimes arrive with invalid syntax containing multiple roots separated by empty braces []. How can I detect this and thrown an exception? Currently the code runs and picks up only record set 1, and ...
Hi all!Recently we've been getting lots of these errors when running Databricks notebooks:At that time we observed DRIVER_NOT_RESPONDING (Driver is up but is not responsive, likely due to GC.) log on the single-user cluster we use.Previously when thi...
Hi,I try to use java sql. i can see that the query on databricks is executed properly.However, on my client i get exception (see below).versions:jdk: jdk-20.0.1 (tryed also with version 16, same results)https://www.oracle.com/il-en/java/technologies/...
I'm facing an issue while trying to run my job in db and my notebooks located in Git Lab. When I run job under my personal user_Id it works fine, because I added Git Lab token to my user_Id profile and job able to pull branch from repository. But whe...
Hi @drag7ter, There might be a missing piece in the setup.
Ensure that you’ve correctly entered the Git provider credentials (username and personal access token) for your Service Principle.Confirm that you’ve selected the correct Git provider (GitLab...
Hi,I'm looking for information how to create/mount ephemeral storage to Databricks driver node in Azure Cloud. Does anyone have any experience working with ephemeral storage?Thanks,
Hi @cszczotka,
Azure Databricks allows you to mount cloud object storage to the Databricks File System (DBFS) to simplify data access patterns for users who are unfamiliar with cloud concepts.
Mounted data does not work with Unity Catalog, and Dat...
Hello all.We are a new team implementing DLT and have setup a number of tables in a pipeline loading from s3 with UC as the target. I'm noticing that if any of the 20 or so tables fail to load, the entire pipeline fails even when there are no depende...
Hi @dashawn,
When data processing fails, manual investigation of logs to understand the failures, data cleanup, and determining the restart point can be time-consuming and costly. DLT provides features to handle errors more intelligently.By default,...