I have a DLT pipeline, where all tables are non-streaming (materialized views), except for the last one, which needs to be append-only, and is therefore defined as a streaming table.The pipeline runs successfully on the first run. However on the seco...
Hi,I have a DLT pipeline that applies changes from a source table (cdctest_cdc_enriched) to a target table (cdctest), by the following code:dlt.apply_changes( target = "cdctest", source = "cdctest_cdc_enriched", keys = ["ID"], sequence_by...
Hi,I was trying to open the Workflows but there is an error "An error occurred when loading Jobs and Workflows App." we need help to know why it happened and how we can resolve it please.
Same...and the weirdest is that all of the services looks healthy in https://status.databricks.com/Region: eu-central-1Provider: AWSCould anyone provide some info here?
Hi all,I'm in the progress of migrating from Databricks Azure to Databricks AWS.One part of this is migrating all our workflows which I wanted to via the /api/2.1/jobs/create api with the workflow passed via the json body. I have successfully created...
I need to execute a .py file in Databricks from a notebook (with arguments which for simplicity i exclude here). For this i am using:%sh script.pyscript.py:from pyspark import SparkContext
def main():
sc = SparkContext.getOrCreate()
print(sc...
@madrhr
I think this occurs because one session is initiated within the Python script (.py file), while in the Databricks notebook, we have a pre-configured Spark session. It is important to note that we cannot use more than one Spark session per not...
Hello Community Folks -Did anyone implemented migration of notebooks that is in workspace to production databricks workspace using Databricks Asset Bundle? If so can you please help me with any documentation which I can refer? Thanks!!RegardsNiruban ...
Hi everyone!I want to use in-memory cached views in a merge into operation, but I am not entirely sure if the exactly saved in-memory view is used in this operation or not.So, suppose I have a table named table_1 and a cached view named cached_view_1...
@deng_dev - Are you using external metastore by any chance. From the physical plan, we could see the catalog`.`db`.`table_1` is not cached. If it is glue catalog, then caching can be enabled based on the below configs in the article below
https://do...
Any leads/posts for Databricks CI/CD integration with Bitbucket pipeline. I am facing the below error while I creation my CICD pipeline pipelines:branches:master:- step:name: Deploy Databricks Changesimage: docker:19.03.12services:- dockerscript:# U...
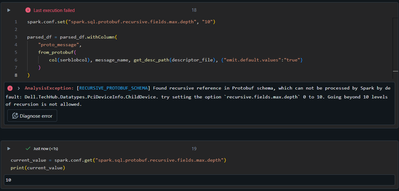
I am receiving protobuf data in a json attribute and along with it I receive a descriptor file.I am using from_protobuf to deserialize the data as below,It works most of the time but giving error when there are some recursive fields within the protob...
I'm trying to run: databricks bundle deploy -t prod --profile PROD_Service_Principal My bundle looks: bundle:
name: myproject
include:
- resources/jobs/bundles/*.yml
targets:
# The 'dev' target, for development purposes. This target is the de...
In my case I replaced alias PROD_Service_Principal with id c250831b-5a2a-4461-a855-83b9102f797e and it works. Not intuitive, probably this is a bug in CLI ot bundles service_principal_name: c250831b-5a2a-4461-a855-83b9102f797e
Hello all,I'm currently working on importing some SQL functions from Informix Database into Databricks using Asset Bundle deploying Delta Live Table to Unity Catalog. I'm struggling importing a recursive one, there is the code :CREATE FUNCTION "info...
Since we enable RocksDB in our spark.conf the stream to stream joins/unions results in empty dataframe, does anyone else have the same experience? it is on AWSspark.conf.set("spark.sql.streaming.stateStore.providerClass","com.databricks.sql.streaming...
Hi,I am trying to read one file which having some blank value in column and we know spark convert blank value to null value during reading, how to read blank/empty value as empty value ?? tried DBR 13.2,14.3I have tried all possible way but its not w...
OK, after some tests:The trick is in surrounding text in your csv with quotes. Like that spark can actually make a difference between a missing value and an empty value. Missing values are null and can only be converted to something else implicitel...
Hi all,I'm just reaching out to see if anyone has information or can point me in a useful direction. I need to connect to Snowflake from Azure Databricks using the connector: https://learn.microsoft.com/en-us/azure/databricks/external-data/snowflakeT...
@ludgervisser We are trying to connect to Snowflake via Azure AD user through the externalbrowser method but the browser window doesn't open. Could you please share an example code of how you managed to achieve this, or to some documentation? @BobGeo...
Hi team,In Databricks I need to query a postgres source likeselect * from postgres_tbl where id in (select id from df)the df is got from a hive table. If I use JDBC driver, and doquery = '(select * from postgres_tbl) as t'
src_df = spark.read.format(...