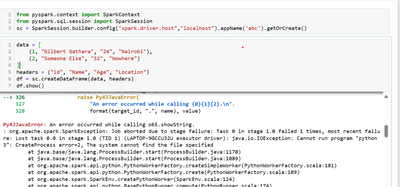
I have a situation where source files in .json.gz sometimes arrive with invalid syntax containing multiple roots separated by empty braces []. How can I detect this and thrown an exception? Currently the code runs and picks up only record set 1, and ...
Hi all!Recently we've been getting lots of these errors when running Databricks notebooks:At that time we observed DRIVER_NOT_RESPONDING (Driver is up but is not responsive, likely due to GC.) log on the single-user cluster we use.Previously when thi...
I am reaching out to bring attention to a performance issue we are encountering while processing XML files using Spark-XML, particularly with the configuration spark.read().format("com.databricks.spark.xml").Currently, we are experiencing significant...
Hi,I try to use java sql. i can see that the query on databricks is executed properly.However, on my client i get exception (see below).versions:jdk: jdk-20.0.1 (tryed also with version 16, same results)https://www.oracle.com/il-en/java/technologies/...
Hi all,I have recently enabled Unity catalog in my DBX workspace. I have created a new catalog with an external location on Azure data storage.I can create new schemas(databases) in the new catalog but I can't create a table. I get the below error wh...
@Snoonan First of all, check the networking tab on the storage account to see if it's behind firewall. If it is, make sure that Databricks/Storage networking is properly configured (https://learn.microsoft.com/en-us/azure/databricks/security/network/...
I'm facing an issue while trying to run my job in db and my notebooks located in Git Lab. When I run job under my personal user_Id it works fine, because I added Git Lab token to my user_Id profile and job able to pull branch from repository. But whe...
Hi @drag7ter, There might be a missing piece in the setup.
Ensure that you’ve correctly entered the Git provider credentials (username and personal access token) for your Service Principle.Confirm that you’ve selected the correct Git provider (GitLab...
Hi,I'm looking for information how to create/mount ephemeral storage to Databricks driver node in Azure Cloud. Does anyone have any experience working with ephemeral storage?Thanks,
Hi @cszczotka,
Azure Databricks allows you to mount cloud object storage to the Databricks File System (DBFS) to simplify data access patterns for users who are unfamiliar with cloud concepts.
Mounted data does not work with Unity Catalog, and Dat...
Hello all.We are a new team implementing DLT and have setup a number of tables in a pipeline loading from s3 with UC as the target. I'm noticing that if any of the 20 or so tables fail to load, the entire pipeline fails even when there are no depende...
Hi @dashawn,
When data processing fails, manual investigation of logs to understand the failures, data cleanup, and determining the restart point can be time-consuming and costly. DLT provides features to handle errors more intelligently.By default,...
I am exploring the use of the "file arrival" trigger for a workflow for a use case I am working on. I understand from the documentation that it checks every minute for new files in an external location, then initiates the workflow when it detects a ...
Hi @mvmiller The "file arrival" trigger for a workflow considers the name of the file,when the same name file was overwritten the workflow didnt triggerred.hope I answered your question!
Hello,I'm using a local Docker Spark 3.5 runtime to test my Databricks Connect code. However I've come across a couple of cases where my code would work in one environment, but not the other.Concrete example, I'm reading data from BigQuery via spark....
@dollyb That's because when you've added another dependency on Databricks, it doesn't really know which one it should use. By default it's using built-in com.google.cloud.spark.bigquery.BigQueryRelationProvider.What you can do is provide whole packag...
Hi all!I need to migrate multiple notebooks from one workspace to another. Is there any way to do it without using Git?Since Manual Import and Export is difficult to do for multiple notebooks and folders, need an alternate solution.Please reply as so...
@HaripriyaP You can use databricks CLI to export and import notebooks from one workspace to another.CLI Documentation here:https://github.com/databricks/cli/blob/main/docs/commands.md#databricks-workspace-export---export-a-workspace-object
Hi all!I need to copy multiple tables from one workspace to another with metadata information. Is there any way to do it?Please reply as soon as possible.
@HaripriyaP - Depends on your use case, Either of the below approach can be chosen.
1) DELTA CLONE(DEEP CLONE) to clone them to the new workspace.
2) Have the same cluster policy/Instance profile of the old workspace to access them in the new worksp...
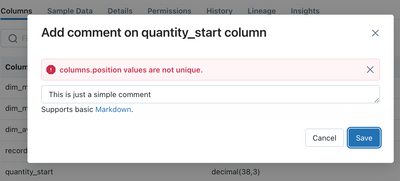
While materialised view doc says MVs support columns comments, this does not seem like the case for MVs created by DLT. For example, when trying to add a comment to a MV created by DLT, it errors:Any ideas on when this will be fixed/supported?
Hi Team, Im trying to get DLT Advanced Configuration value from the python dlt notebook. For example, I set "something": "some path" in Advanced configuration in DLT and I want to get the value from my dlt notebook. I tried "dbutils.widgets.get("some...