Hello,I have non-incremental data landing in a storage account. This data contains old data from before as well as new data. I would like to avoid doing a complete table deletion and table creation just to upload the data from storage and have an upd...
Well, if you know the conditions to separate new data from old data, then while reading the data in to your dataframe, use filter or where clause to select new data and ingest it in to your delta table.This is how you can do in general. But if you ha...
Hi Everyone,I have DLTP pipeline which I need to execute for difference source systems. Need advise on how to parametrize this.I have gone through many articles on the web, but it seems there is no accurate information available.Can anyone please hel...
You can provide parameters in the configuration section of DLT pipeline and access it in your code using spark.conf.get(<parameter_name>).Parameterize DLT pipelines
Hello Team,I am new to Databrciks. Generally where all the logs will be stored in Databricks. I see if any job fails below the command i could see some error messages.Otherwise in real time how to check the log files/error messages in Databricks UI.T...
Hiii, Does anyone have an idea about the typical duration for Databricks to create logs in an S3 bucket using the databricks_mws_log_delivery Terraform resource? I've implemented the code provided in the Databricks official documentation, but I've be...
The issue has been resolved. There was no problem with the code or the API. However, it took over 12 hours for logs to start appearing in my bucket, despite Databricks documentation indicating that logs should appear within 1 hour..Thank you!
When inserting rows through the Sql Api (/api/2.0/sql/statements/), when more than a certain number of records (about 25 records with 8 small columns) are included in the statement, the call fails with the error:"The request could not be processed by...
@TheIceBrick did you find out anything else about this?I am experiencing exactly the same, I can insert up to 35 rows but break at about 50 rows.The payload size is 42KB, I am passing parameters for each row.@Debayan This is no where near the 16MiB /...
I see, is there a possibility in SF to define an external location/datasource?Just guessing here, as these type of packages are really good in isolating data, not integrating it.
Hello,I tried to schedule a long running job and surprisingly it does seem to neither terminate (and thus does not let the cluster shut down), nor continue running, even though the state is still "Running":But the truth is that the job has miserably ...
Hello Community,I have some csv files saved in databricks workspace and want to read them with spark. I make use of the commanddf = spark.read.format('csv').load(r'filepath') However, it throws the error.org.apache.spark.SparkSecurityException: [INSU...
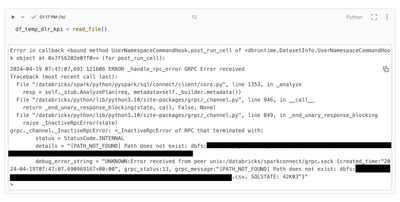
We were using this method and this was working as expected in Databricks 13.3. def read_file():
try:
df_temp_dlr_kpi = spark.read.load(raw_path,format="csv", schema=kpi_schema)
return df_temp_dlr_kpi
except Exce...
Hello:)as part of deploying an app that previously ran directly on emr to databricks, we are running experiments using LTS 9.1, and getting the following error: PythonException: An exception was thrown from a UDF: 'pyspark.serializers.SerializationEr...
Hi Team,Is there any update on the Community Reward Store, as it's been discontinued from the old portal, and we still can't see the new portal for that.Is there any expected date when this will be available for community members?
Hello:)we are trying to run an existing working flow that works currently on EMR, on databricks.we use LTS 10.4, and when loading the data we get the following error:at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:...
Hello,Everyday a new file of the same name gets sent to my storage account with old and new data appended at the end. Columns may also be added during one of these file updates. This file does a complete overwrite of the previous file. Is it possibl...
Can anyone point me towards some resources for achieving this? I already have the token.Trying with: dbsql.WithAccessToken(settings.Token)But I'm getting the following error:Unable to load OAuth Config: request error after 1 attempt(s): unexpected HT...
Hi,I'm trying to set up a local development environment using python / vscode / poetry. Also, linting is enabled (Microsoft pylance extension) and the python.analysis.typeCheckingMode is set to strict.We are using python files for our code (.py) whit...