In my notebook, i am performing few join operations which are taking more than 30s in cluster 14.3 LTS where same operation is taking less than 4s in 13.3 LTS cluster. Can someone help me how can i optimize pyspark operations like joins and withColum...
Hi guys, i am running my Databricks jobs on a cluster job from azure datafactory using a databricks Python activity When I monitor my jobs in workflow-> job runs . I see that the run name is a concatenation of adf pipeline name , Databricks python ac...
Hi everyone!I'm setting up a workflow using Databricks Assets Bundles (DABs). And I want to configure my workflow to be trigger on file arrival. However all the examples I've found in the documentation use schedule triggers. Does anyone know if it is...
I have an idea of sharing & trading IoT data streamlined from many data sources on the incentive platform.I would be appreciate it if you guys discuss with me about the idea.Thank you
Hello @Rene,Building an IoT data trading platform using Databricks is indeed a feasible and innovative idea. Databricks provides a unified analytics platform that can handle massive amounts of data processing and advanced analytics, which is essentia...
I'm using Databricks asset bundles and I have pipelines that contain "if all done rules". When running on CI/CD, if a task fails, the pipeline returns a message like "the job xxxx SUCCESS_WITH_FAILURES" and it passes, potentially deploying a broken p...
Awesome answer, I will try the first approach. I think it is a less intrusive solution than changing the rules of my pipeline in development scenarios. This way, I can maintain a general pipeline for deployment across all environments. We plan to imp...
I've defined a streaming deltlive table in a notebook using python.running on "preview" channeldelta cache accelerated (Standard_D4ads_v5) computeIt fails withorg.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] Query [id = xxx, ru...
Hi @smedegaard,
You’re encountering a StreamingQueryException with the message: “getPrimaryKeys not implemented for debezium SQLSTATE: XXKST.”
This error suggests that the getPrimaryKeys operation is not supported for the Debezium connector in your ...
Hi Team,Is there any impact when integrating Databricks with Boomi as opposed to Azure Event Hub? Could you offer some insights on the integration of Boomi with Databricks?https://boomi.com/blog/introducing-boomi-event-streams/Regards,Janga
Hi @Phani1, Let’s explore the integration of Databricks with Boomi and compare it to Azure Event Hub.
Databricks Integration with Boomi:
Databricks is a powerful data analytics platform that allows you to process large-scale data and build machin...
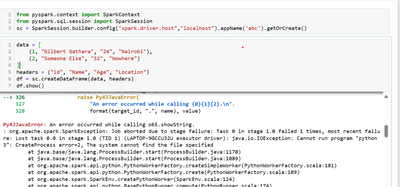
Hello All,My scenario required me to create a code that reads tables from the source catalog and writes them to the destination catalog using Spark. Doing one by one is not a good option when there are 300 tables in the catalog. So I am trying the pr...
Hi @ETLdeveloper You can use the multithreading that help you to run notebook in parallel.Attaching code for your reference - from concurrent.futures import ThreadPoolExecutor
class NotebookData:
def __init__(self, path, timeout, parameters = Non...
Hi All! Im in a project where i need to connect azure devops and databricks using managed identity to avoid the using of service account, PAT, etc.The thing is i cant move forward with the connection since i cannot take the ownership of the files wh...
Hi @TitaMn, Connecting Azure DevOps and Azure Databricks using managed identity is a great approach to enhance security and avoid using service accounts or personal access tokens (PATs).
Let’s explore some options:
Azure Managed Identity for Dat...
Hi,Would anyone happen to know whether it's possible to cache a dataframe in memory that the result of a query on a federated table?I have a notebook that queries a federated table, does some transformations on the dataframe and then writes this data...
@daniel_sahal , this is the code snippet:lsn_incr_batch = spark.sql(f"""select start_lsn,tran_begin_time,tran_end_time,tran_id,tran_begin_lsn,cast('{current_run_ts}' as timestamp) as appendedfrom externaldb.cdc.lsn_time_mappingwhere tran_end_time > '...
Hi Community,i was trying to load a ML Model from a Azure Storageaccount (abfss://....) with: model = PipelineModel.load(path) i set the spark config: spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provi...
I am reaching out to bring attention to a performance issue we are encountering while processing XML files using Spark-XML, particularly with the configuration spark.read().format("com.databricks.spark.xml").Currently, we are experiencing significant...
@amar1995 - Can you try this streaming approach and see if it works for your use case (using autoloader) - https://kb.databricks.com/streaming/stream-xml-auto-loader
I managed to extract the Google Analytics data via lakehouse federation and the Big Query connection but the events table values are in a weird JSON format{"v":[{"v":{"f":[{"v":"ga_session_number"},{"v":{"f":[{"v":null},{"v":"2"},{"v":null},{"v":null...
@AnaMocanu I was using this function, with a little modifications on my end:https://gist.github.com/shreyasms17/96f74e45d862f8f1dce0532442cc95b2Maybe this will be helpful for you
I have an Azure web app running flask web server. From flask server, I want to run some queries on the data stored in ADLS Gen2 storage. I already created Databricks notebooks running these queries. The flask server will pass some parameters in ...