Hi,Would anyone happen to know whether it's possible to cache a dataframe in memory that the result of a query on a federated table?I have a notebook that queries a federated table, does some transformations on the dataframe and then writes this data...
Thanks for your answer Lakshay. I have tried caching the df by using the cache() function, but it does not seem to do anything (the dataset in this case is tiny, so I'm pretty sure it would fit into memory). So I'm indeed back to writing to file firs...
I am reaching out to bring attention to a performance issue we are encountering while processing XML files using Spark-XML, particularly with the configuration spark.read().format("com.databricks.spark.xml").Currently, we are experiencing significant...
@amar1995 - Can you try this streaming approach and see if it works for your use case (using autoloader) - https://kb.databricks.com/streaming/stream-xml-auto-loader
I managed to extract the Google Analytics data via lakehouse federation and the Big Query connection but the events table values are in a weird JSON format{"v":[{"v":{"f":[{"v":"ga_session_number"},{"v":{"f":[{"v":null},{"v":"2"},{"v":null},{"v":null...
@AnaMocanu I was using this function, with a little modifications on my end:https://gist.github.com/shreyasms17/96f74e45d862f8f1dce0532442cc95b2Maybe this will be helpful for you
Hi Community,i was trying to load a ML Model from a Azure Storageaccount (abfss://....) with: model = PipelineModel.load(path) i set the spark config: spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provi...
@daniel_sahal i already tried it out with the "longer" version for spark configs as mentioned in the article.Tbh. for regular spark.read.load(path) commands both versions work just fine. I guess the one i used is a general conf. and the one in the ar...
I have an Azure web app running flask web server. From flask server, I want to run some queries on the data stored in ADLS Gen2 storage. I already created Databricks notebooks running these queries. The flask server will pass some parameters in ...
We have a data feed with files whose filenames stays the same but the contents change over time (brand_a.csv, brand_b.csv, brand_c.csv ....).Copy Into seems to ignore the files when they change.If we set the Force flag to true and run it, we end up w...
Thanks for the validation, Werners! That's the path we've been heading down (copy + merge). I still have some DLT experiments planned but - at least for this situation - copy + merge works just fine.
I would like to share the following links https://www.databricks.com/product/machine-learning/large-language-models
https://docs.databricks.com/en/large-language-models/index.html
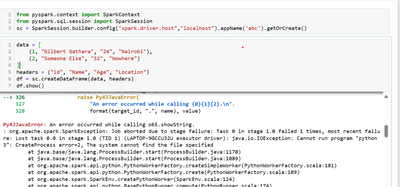
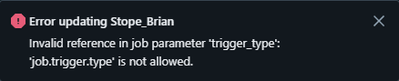
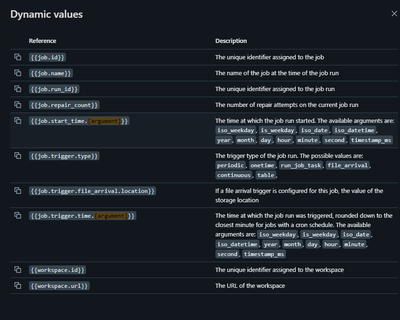
Following the instruction on the Job Parameter Dynamic values, I am able to use {{job.id}}{{job.name}}{{job.run_id}}{{job.repair_count}}{{job.start_time.[argument]}}However, when I set trigger_type as trigger_type: {{job.trigger.type}} and hit SAVE, ...
Hi All! Im in a project where i need to connect azure devops and databricks using managed identity to avoid the using of service account, PAT, etc.The thing is i cant move forward with the connection since i cannot take the ownership of the files wh...
I've defined a streaming deltlive table in a notebook using python.running on "preview" channeldelta cache accelerated (Standard_D4ads_v5) computeIt fails withorg.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] Query [id = xxx, ru...
Hi Team,Is there any impact when integrating Databricks with Boomi as opposed to Azure Event Hub? Could you offer some insights on the integration of Boomi with Databricks?https://boomi.com/blog/introducing-boomi-event-streams/Regards,Janga
Hi!I want to migrate all my databricks related code from one github repo to another. I knew this wouldn't be straight forward. When I copy my code for one DLT, I get the errororg.apache.spark.sql.catalyst.ExtendedAnalysisException: Table 'vessel_batt...
Hello Community -I am trying to deploy only one workflow from my CICD. But whenever I am trying to deploy one workflow using "databricks bundle deploy - prod", it is deleting all the existing workflow in the target environment. Is there any option av...
@Rajani : This is what I am doing. I am having git actions to kick off which will run - name: bundle-deployrun: | cd ${{ vars.HOME }}/dev-ops/databricks_cicd_deployment databricks bundle deploy --debug Before running this step, I am creatin...
Hello! My company wants us to only use managed identities for authentication. We have set up Databricks using Terraform, got Unity Catalog and everything, but we're a very small team and I'm struggling to control permissions outside of Unity Catalog....
Thanks a lot. Then I guess we will try to use dbmanagedidentity for most of our needs, and create service principals +secret scopes when there are more specific needs, such as for limiting access to sensitive data. A bit of a hassle to scale, probabl...