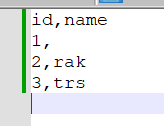
Hi,I am trying to read one file which having some blank value in column and we know spark convert blank value to null value during reading, how to read blank/empty value as empty value ?? tried DBR 13.2,14.3I have tried all possible way but its not w...
We have a data feed with files whose filenames stays the same but the contents change over time (brand_a.csv, brand_b.csv, brand_c.csv ....).Copy Into seems to ignore the files when they change.If we set the Force flag to true and run it, we end up w...
If you do not have control over the content of the files I suggest the following:Each day you get new files/data (I suppose these are not incremental). These files contain new, updated and deleted data, and are overwritten.Because of this, autoloade...
Hi Community,I'm trying to load data from the landing zone to the bronze layer via DLT- Autoloader, I want to add a column record_id to the bronze table while I fetch my data. I'm also using file arrival trigger in the workflow to update my table inc...
Hi,I'm looking for a DataBricks client for Rust. I could only find these SDK implementations.Alternatively, I would be very happy with the OpenAPI spec. Clearly one exists: the Go SDK implementation contains code to generate itself from such a spec...
Databricks REST API referenceThis reference contains information about the Databricks application programming interfaces (APIs). Each API reference page is presented primarily from a representational state transfer (REST) perspective. Databricks REST...
I would like to create a regular PySpark session in an isolated environment against which I can run my Spark based tests. I don't see how that's possible with the new Databricks Connect. I'm going in circles here, is it even possible?I don't want to ...
Ok, so the best solution as it stands today (for me personally at least) is this:Have pyspark ^3.4 installed with the connect extra feature.My unit tests then don't have to change at all, as they use the regular spark session created on the flyFor ru...
Hi all!Recently we've been getting lots of these errors when running Databricks notebooks:At that time we observed DRIVER_NOT_RESPONDING (Driver is up but is not responsive, likely due to GC.) log on the single-user cluster we use.Previously when thi...
Hi there,Im trying to run DE 2.1 - Querying Files Directly on my workspace with a default cluster configuration for found below,but I cannot seem to run this file (or any other labs) as it gives me this error message Resetting the learning environme...
Hi @Phani1, When it comes to code review tools for your Databricks tech stack, here are some options you might find useful:
Built-in Interactive Debugger in Databricks Notebook:
The interactive debugger is available exclusively for Python code withi...
Hey Community!Just curious if anyone has tried using Azure Synapse for orchestration and passing parameters from Synapse to a Databricks Notebook. My team is testing out Databricks, and I'm replacing Synapse Notebooks with Databricks Notebooks, but I...
Hi @SPres You can definitely pass these parameters to databricks notebook also.Please refer below docs - Run a Databricks Notebook with the activity - Azure Data Factory | Microsoft Learn
Hi community,Currently, I am training models on databricks cluster and use mlflow to log and register models. My goal is to send notification to me when a new version of registered model happens (if the new run achieves some model performance baselin...
I see two articles on databricks documentationshttps://docs.databricks.com/en/archive/azure/synapse-polybase.html#language-pythonhttps://docs.databricks.com/en/connect/external-systems/synapse-analytics.html#service-principal Polybase one is legacy o...
Hi @dilkushpatel, Thank you for sharing your confusion regarding PolyBase and the COPY INTO command in Databricks when working with Azure Synapse.
PolyBase (Legacy):
PolyBase was previously used for data loading and unloading operations in Azure...
Dear Members,I need your help in below scenario.I am passing few parameters from ADF pipeline to Databricks notebook.If I execute ADF pipeline to run my databricks notebook and use these variables as is in my code (python) then it works fine.But as s...
I renamed our service principal in Terraform, which forces a replacement where the old service principal is removed and a new principal with the same permission is recreated. The Terraform succeeds to apply, but when I try to run dbt that creates tab...
This is also true for removing groups before unassigning them (removing and unassigning in Terraform)│ Error: cannot update grants: Could not find principal with name <My Group Name>
Hello,I'm using the auto loader to stream a table of data and have added schema hints to specify field values.I've observed that when my initial data file is missing fields specified in the schema hint,the auto loader correctly identifies this and ad...
Hi @my_super_name,
Default Schema Inference: By default, Auto Loader schema inference aims to avoid schema evolution issues due to type mismatches. For formats like JSON, CSV, and XML that don’t encode data types explicitly, Auto Loader infers a...