Team,I did setup a SQL Warehouse Cluster to support request from Mobile devices through REST API. I read through the documentation of concurrent query limit which is 10. But in my scenario I had 5 small clusters and the query monitoring indicated the...
Hi @Ramakrishnan83,
Databricks SQL does indeed support concurrent read requests. However, the exact definition of concurrency can vary based on the cluster configuration and workload.By default, Databricks limits the number of concurrent queries per...
Rest assured that our movers will handle your belongings with the highest level of care and protection, and we have all the necessary tools to provide convenience to your highest satisfaction. Whatever the need, as one of the best local movers in Mia...
When choosing a moving company, it's essential to prioritize trust and reliability, and Moving Companies Burlington stands out in delivering exactly that. Rest assured that our movers will handle your belongings with the highest level of care and pro...
In relational data warehouse systems it was best practise to represent date values as YYYYMMDD integer type values in tables. Date comparison could be done easily without using date-functions and with low performance impact.Is this still the recomme...
Is there any business use-case where profile_metrics and drift_metrics are used by Databricks customers.If so,kindly provide the scenario where to leverage this feature e.g data lineage,table metadata updates.
hey @pankaj2264. both profile metric and drift metric tables are created and used by Lakehouse monitoring to assess the performance of your model and data over time or relative to a baseline table. you can find all the relevant information here Intro...
Hi,Is it possible to convert existing delta table with partition having data to clustering? If so can you please suggest the steps required? I tried and searched but couldn't find any. Is it that liquid clustering can be done only for new Delta table...
I wrote simple code:from pyspark.sql import SparkSession
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number, max
import pyspark.sql.functions as F
streaming_data = spark.read.table("x")
window = Window.partitionBy("BK...
Hi,In my opinion the result is correctWhat needs to be noted in the result is that it is sorted by the "Onboarding_External_LakehouseId" column so if there is "BK_AccountApplicationId" with the same code, it will be partitioned into 2 row_numbersJust...
Hi!I receive three streams from a postgres CDC. These 3 tables, invoices users and products, need to be joined. I want to use a left join with respect the invoices stream. In order to compute correct results and release old states, I use watermarks a...
Hi @jcozar, It seems you’re encountering an issue with multiple event time columns in your Spark Structured Streaming join.
Let’s break down the problem and find a solution.
Event Time Columns:
In Spark Structured Streaming, event time is crucia...
Hi!I am exploring the read state functionality in spark streaming: https://docs.databricks.com/en/structured-streaming/read-state.htmlWhen I start a streaming query like this: (
...
.writeStream
.option("checkpointLocation", f"{CHECKPOIN...
Hi @jcozar,
Execute the streaming query again to construct the state schema.Ensure that the checkpoint location (dbfs:/tmp/checkpoints/experiment_2_2) is correct and accessible.
I'm creating dashboard with multiple visualizations from a notebook.Whenever I add a new visualization, the default position in dashboard is top left which mess up all the format I did for previous graph. Is there a way to default add to the bottom o...
Hi,I am trying to make Stream - Static join with aggregation with no luck. I have a streaming table where I am getting events with two nasted arraysID Array1 Array21 [1,2] [3,4]I need make two joins to static dictionary tables (without an...
Hi @rocky5, . You want to perform a stream-static join with aggregation in Databricks SQL, where you have a streaming table with nested arrays and need to join it with static dictionary tables based on IDs contained in those arrays.
Here are the ...
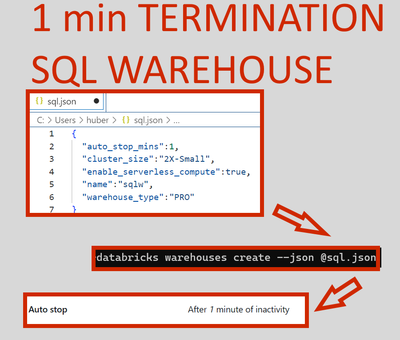
SQL warehouse can auto-terminate after 1 minute, not 5, as in UI. Just run a simple CLI command. Of course, with such a low auto termination, you lose the benefit of CACHE, but for some ad-hoc queries, it is the perfect setup when combined with serve...
Hi @Hubert-Dudek , Hope you are doing well!
Could you please clarify more on your ask here?
However, from the above details, the SQL warehouse mentioned is auto-terminating after 1 minute of inactivity because the Auto stop is set to 1 minute. Howe...
Hi all! The Databricks Looker Studio connector has now been available for a few weeks. Tested the connector but running into several issues: I am used to working with dynamic queries, so I am able to use date parameters (similar to BigQuery Looker St...
Hi @Kaniz Hope you're doing well! I am very curious about the following thing: However, there might be workarounds or alternative approaches to achieve similar functionality. You could explore using Looker’s native features for dynamic filtering or c...
Im trying to set up a connection to Iceberg on S3 via Snowflake as described https://medium.com/snowflake/how-to-integrate-databricks-with-snowflake-managed-iceberg-tables-7a8895c2c724 and https://docs.snowflake.com/en/user-guide/tables-iceberg-catal...
Hi @Kaniz ,We've been working on setting up Glue as catalog, which is working fine so far. However, Glue takes place of the hive_metastore, which appears to be a legacy way of setting this up. Is the way proposed here the recommended way to set it up...
I'm just curious whether, in the future, Databricks will offer a certification for AI, GenAI, or any other AI-related fields. I'm very interested and looking forward to it.
Hi @jensen22, Thank you for posting your concern on Community!
To expedite your request, please list your concerns on our ticketing portal. Our support staff would be able to act faster on the resolution (our standard resolution time is 24-48 hours).
Hi,I want to remove duplicate rows from my managed delta table in my unity catalog. I use a query on a SQL warehouse similar to this: WITH cte AS (
SELECT
id, ROW_NUMBER() OVER (PARTITION BY id,##,##,## ORDER BY ts) AS row_num
FROM
catalog.sch...
I have first tried to use _metadata.row_index to delete the correct rows but also this resulted in an error. My solution was now to use spark and overwrite the table.table_name = "catalog.schema.table"
df = spark.read.table(table_name)
count_df = df....