Hiii, Does anyone have an idea about the typical duration for Databricks to create logs in an S3 bucket using the databricks_mws_log_delivery Terraform resource? I've implemented the code provided in the Databricks official documentation, but I've be...
Hello,Everyday a new file of the same name gets sent to my storage account with old and new data appended at the end. Columns may also be added during one of these file updates. This file does a complete overwrite of the previous file. Is it possibl...
Can anyone point me towards some resources for achieving this? I already have the token.Trying with: dbsql.WithAccessToken(settings.Token)But I'm getting the following error:Unable to load OAuth Config: request error after 1 attempt(s): unexpected HT...
Hi,I'm trying to set up a local development environment using python / vscode / poetry. Also, linting is enabled (Microsoft pylance extension) and the python.analysis.typeCheckingMode is set to strict.We are using python files for our code (.py) whit...
Hi All,we are executing databricks notebook activity inside the child pipeline thru ADF. we are getting child pipeline name in job name while executing databricks job. Is it possible to get master pipeline name as job name or customize job name thr...
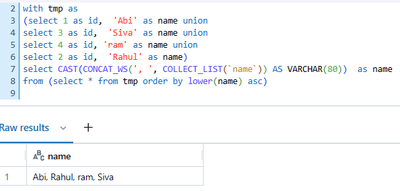
I have a CTE table with the below names as values. My objective is to create another table by concatenating all the rows from the CTE table in ascending order, resulting in the final output sequence: "Abi, Rahul, ram, Siva". When executing the query ...
when writing, order is not guaranteed due to the nature of distributed processing.If you want the order to be guaranteed, you should order it when reading the data.Your query does not write any data, DLT does, that is the difference.
A critical issue has arisen that is impacting our deployment planning for our client. We have encountered a challenge with our Azure CI/CD pipeline integration, specifically concerning the deployment of Python files (.py). Despite our best efforts, w...
I am trying to reading json from aws s3 using with open in databricks notebook using shared cluster.Error message:No such file or directory:'/dbfs/mnt/datalake/input_json_schema.json'In single instance cluster the above error is not found.
Hey,Thanks for suggesting this approach.But I want to know why the json file cannot be read from AWS S3 bucket using "with open" in python with shared instance mode cluster. The code works perfectly fine if I'm using a single instance mode cluster.co...
Hi there!Hope somebody here can help me. We have created a new Databricks Account on Azure with the ARM template for VNET injection.We have all the subnets etc., unitiy catalog active and the connector for databricks.I want now to create my first tab...
Hi,To solve this problem, the following Microsoft documentation can be used to configure the NCC to enable the connection between the private Azure storage and the serverless resources.https://learn.microsoft.com/en-us/azure/databricks/security/netwo...
Hi alliam working on a data containing JSON fields with embedded commas into CSV format. iam facing challenges due to the commas within the JSON being misinterpreted as column delimiters during the conversion process.i tried several methods to modify...
Hi Sai,
I assume that the problem comes not from the PySpark, but from Excel.
I tried to reproduce the error and didn't find the way - that a good thing, right ? Please try the following :
df.write.format("csv").save("/Volumes/<my_catalog_name>/<m...
I recently got access to delta sharing and I am looking to access the data from the tables in share through ADF. I used linked services such as REST API and HTTP and successfully established connection using the credential file token and http path, h...
Hey, I think you'll need to use a Databricks activity instead of Copy
See :
https://learn.microsoft.com/en-us/azure/data-factory/connector-overview#integrate-with-more-data-storeshttps://learn.microsoft.com/en-us/azure/data-factory/transform-data-dat...
Hey everyone!I've some previous experience with Data Engineering, but totally new in Databricks and Delta Tables.Starting this thread hoping to ask some questions and asking for help on how to design a process.So I have essentially 2 delta tables (sa...
Hi @databird ,
You can review the code of each demo by opening the content via "View the Notebooks" or by exploring the following repo : https://github.com/databricks-demos (you can try to search for "merge" to see all the occurrences, for example)
T...
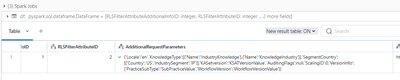
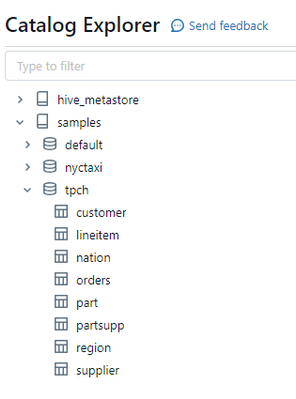
Hi everyoneiam trying to fetch the metadata of every columns from an table and every tables from the database under an catalogue for that iam trying to use the samples catalogue that provided by databricks and get details for tpch database that provi...
I enrolled myself for the Databricks data engineer certification recently and gave a shot at the exam and i did clear it successfully. I have received the certificate in the form of a pdf file along with a URL in which i can see my certificate and ba...
Hi @vinay076 Thanks for asking! Our support team can provide you with a credential ID. Please file a ticket with our support team, give them your email associated with your certification, and they can get you the credential ID.
Hi @VabethRamirez ,
Also, instead of using directly the API, you can use databricks Python sdk :
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
job_list = w.jobs...