I am exploring the use of the "file arrival" trigger for a workflow for a use case I am working on. I understand from the documentation that it checks every minute for new files in an external location, then initiates the workflow when it detects a ...
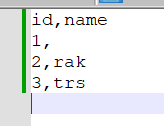
Hi all,I need to perform an Update on a Delta Table adding elements to a column of ArrayType(StringType()) which is initialized empty.Before UpdateCol_1 StringType()Col_2 StringType()Col_3 ArrayType()ValVal[ ]After UpdateCol_1 StringType()Col_2 Strin...
Hi @carlosancassani, It seems like you’re trying to append a string to an array column in a Delta table. The error you’re encountering is because you’re trying to assign a string value to an array column, which is not allowed due to type mismatch.
To...
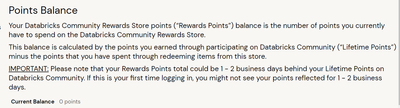
Hi Team,Can anyone help me why my reward point still showing 0 balance. My databricks community points is not reflecting on reward claim portal.i was login first time . Also I was wait for 3 business days but its still not reflecting
Hi,I am trying to read one file which having some blank value in column and we know spark convert blank value to null value during reading, how to read blank/empty value as empty value ?? tried DBR 13.2,14.3I have tried all possible way but its not w...
dont quote something from stackoverflow because those are old version in spark tried.. have you tried the thing on your own to verify if this really working or not in spark3??
Hi,I'm looking for information how to create/mount ephemeral storage to Databricks driver node in Azure Cloud. Does anyone have any experience working with ephemeral storage?Thanks,
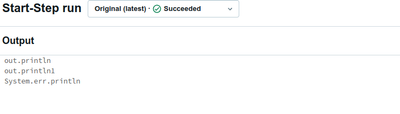
Hi,I have an issue when running JAR jobs. I expect to see logs in the output window of a run. Unfortunately, I can only see messages of that are generated with "System.out.println" or "System.err.println". Everything that is logged via slf4j is only ...
Hi @Dom1,
Ensure that both the slf4j-api and exactly one implementation binding (such as slf4j-simple, logback, or another compatible library) are present in your classpath1.If you’re developing a library, it’s recommended to depend only on slf4j-ap...
I'm facing an issue while trying to run my job in db and my notebooks located in Git Lab. When I run job under my personal user_Id it works fine, because I added Git Lab token to my user_Id profile and job able to pull branch from repository. But whe...
Hi,I'm looking for a DataBricks client for Rust. I could only find these SDK implementations.Alternatively, I would be very happy with the OpenAPI spec. Clearly one exists: the Go SDK implementation contains code to generate itself from such a spec...
Databricks REST API referenceThis reference contains information about the Databricks application programming interfaces (APIs). Each API reference page is presented primarily from a representational state transfer (REST) perspective. Databricks REST...
Hi there,Im trying to run DE 2.1 - Querying Files Directly on my workspace with a default cluster configuration for found below,but I cannot seem to run this file (or any other labs) as it gives me this error message Resetting the learning environme...
Hello,I'm using the auto loader to stream a table of data and have added schema hints to specify field values.I've observed that when my initial data file is missing fields specified in the schema hint,the auto loader correctly identifies this and ad...
Hi @Kaniz Thanks for your help!Your solution works for the initial issue,and I've implemented it first in my code.but it creates a other problem.When we explicitly define the struct hint as 'bbb STRUCT<ccc: INT>',it works until someone adds more fiel...
We have a data feed with files whose filenames stays the same but the contents change over time (brand_a.csv, brand_b.csv, brand_c.csv ....).Copy Into seems to ignore the files when they change.If we set the Force flag to true and run it, we end up w...
If you do not have control over the content of the files I suggest the following:Each day you get new files/data (I suppose these are not incremental). These files contain new, updated and deleted data, and are overwritten.Because of this, autoloade...
Hi Community,I'm trying to load data from the landing zone to the bronze layer via DLT- Autoloader, I want to add a column record_id to the bronze table while I fetch my data. I'm also using file arrival trigger in the workflow to update my table inc...
I would like to create a regular PySpark session in an isolated environment against which I can run my Spark based tests. I don't see how that's possible with the new Databricks Connect. I'm going in circles here, is it even possible?I don't want to ...
Ok, so the best solution as it stands today (for me personally at least) is this:Have pyspark ^3.4 installed with the connect extra feature.My unit tests then don't have to change at all, as they use the regular spark session created on the flyFor ru...
Hi all!Recently we've been getting lots of these errors when running Databricks notebooks:At that time we observed DRIVER_NOT_RESPONDING (Driver is up but is not responsive, likely due to GC.) log on the single-user cluster we use.Previously when thi...