Hi,
My question will be more about the architecture solutions and potential implementation of these solutions.
The project :
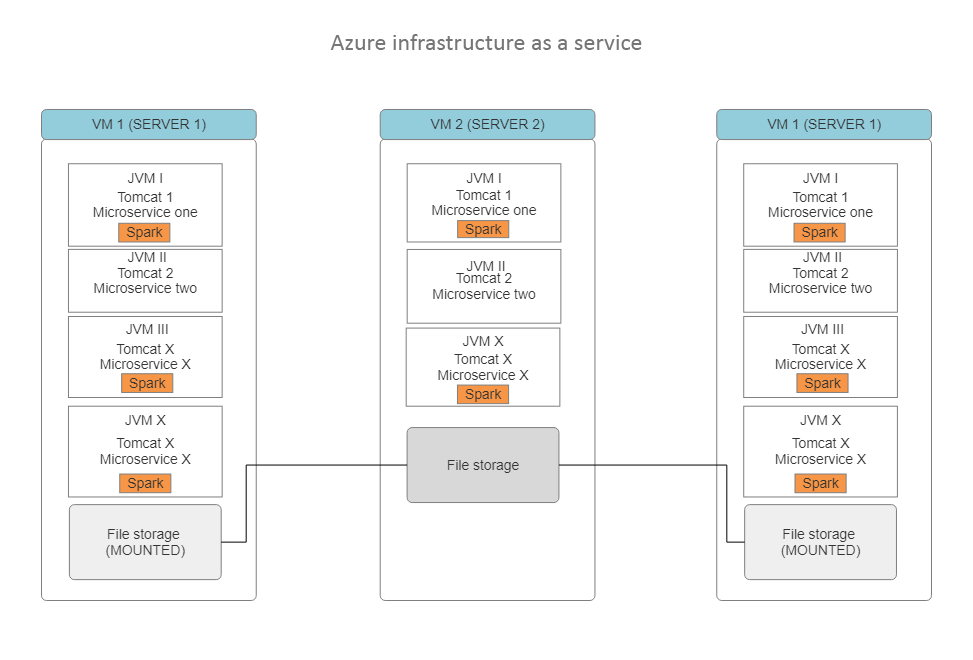
Multiple microservices each one deployed on a Tomcat and each Tomcat is running in one of the tree VM existing in Azure.
Each microservice is a spring boot application exposing a couple of endpoints that could be consumed by other microservice or a final client (browser), some of those microservice will contain an embedded Spark.
The file storage is a folder in one of the VM hard disks, this folder is mounted in the other two servers.

Below is a workflow example for more clearty:
From their browser, a user can click on a function (Filter / Aggregate...) that will start executing a function in one of the service (service A), this function will execute a Spark SQL query in a file located in the file storage (folder in hard disk), and spark will generate a new file that will be the result returned to the Client.
**This service can also handle other request that doesn't need to use spark

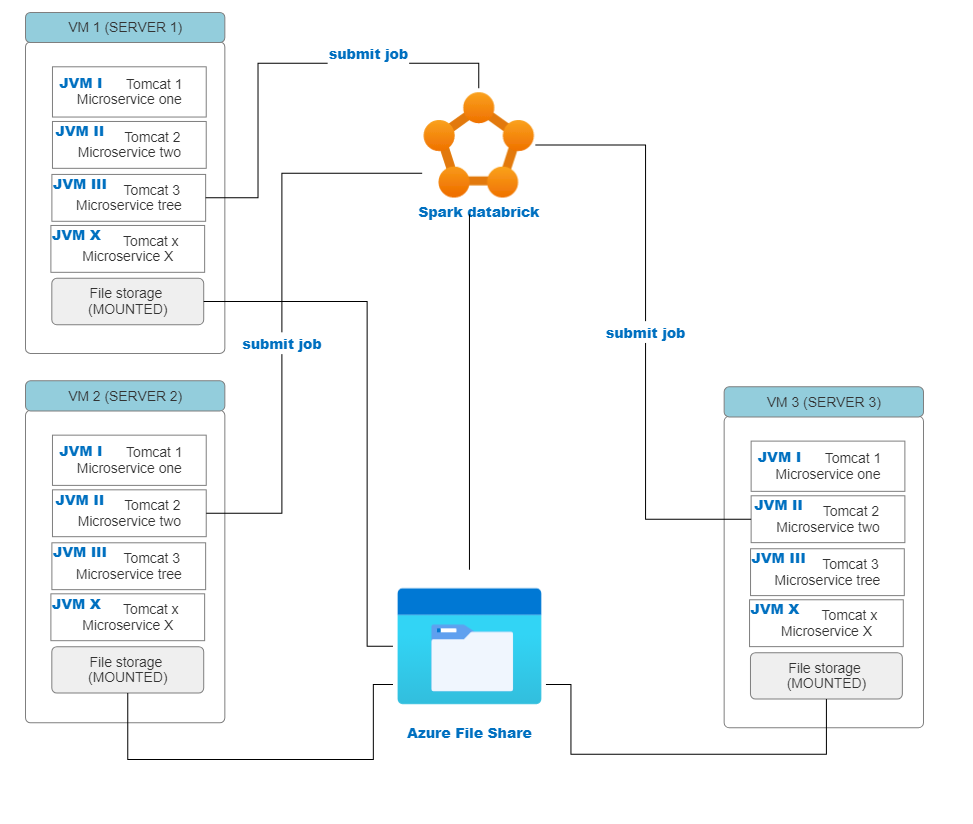
The objective is to use spark in Azure Databricks instead of the embedded that we are using now, while keeping the services deployed on Tomcat.
For the file system I'm thing to move all the file storage to Azure File Share.

The most unclear point form me is how to use spark from Spring boot service while the cluster is on Databricks, knowing that spark jobs will be triggered by an end user from their browser any time he wants. Do I need only to change the config on spark connexion to point to the databricks server :
conf.setMaster("spark://databricks.server.url:port");
Or I should edit the code to submit the job (re-write the spark part in a separate class with a main method and submit it!) ?
Please feel free for any suggestion / recomandation, and thank you for your help and time.
If any information is messing, I will add it just let me know.







{kind=link}
{kind=link}
{kind=link}