Hello, recently I've tried to upgrade my runtime env to the 13.3 LTS ML and found that it breaks my workload during applyInPandas.
My job started to hang during the applyInPandas execution. Thread dump shows that it hangs on direct memory allocation:
sun.misc.Unsafe.setMemory(Native Method)
sun.misc.Unsafe.setMemory(Unsafe.java:529)
org.apache.spark.unsafe.Platform.allocateMemory(Platform.java:202)
org.apache.spark.unsafe.Platform.allocateDirectBuffer(Platform.java:237)
org.apache.spark.util.DirectByteBufferOutputStream.grow(DirectByteBufferOutputStream.scala:62)
org.apache.spark.util.DirectByteBufferOutputStream.ensureCapacity(DirectByteBufferOutputStream.scala:49)
org.apache.spark.util.DirectByteBufferOutputStream.write(DirectByteBufferOutputStream.scala:44)
java.io.DataOutputStream.write(DataOutputStream.java:107) => holding Monitor(java.io.DataOutputStream@1991477395})
java.nio.channels.Channels$WritableByteChannelImpl.write(Channels.java:458) => holding Monitor(java.lang.Object@2018869193})
org.apache.arrow.vector.ipc.WriteChannel.write(WriteChannel.java:112)
org.apache.arrow.vector.ipc.WriteChannel.write(WriteChannel.java:135)
org.apache.arrow.vector.ipc.message.MessageSerializer.writeBatchBuffers(MessageSerializer.java:303)
org.apache.arrow.vector.ipc.message.MessageSerializer.serialize(MessageSerializer.java:276)
org.apache.arrow.vector.ipc.ArrowWriter.writeRecordBatch(ArrowWriter.java:136)
org.apache.arrow.vector.ipc.ArrowWriter.writeBatch(ArrowWriter.java:122)
org.apache.spark.sql.execution.python.BasicPythonArrowInput.writeNextInputToArrowStream(PythonArrowInput.scala:149)
org.apache.spark.sql.execution.python.BasicPythonArrowInput.writeNextInputToArrowStream$(PythonArrowInput.scala:134)
org.apache.spark.sql.execution.python.ArrowPythonRunner.writeNextInputToArrowStream(ArrowPythonRunner.scala:30)
org.apache.spark.sql.execution.python.PythonArrowInput$ArrowWriter.writeNextInputToStream(PythonArrowInput.scala:123)
org.apache.spark.api.python.BasePythonRunner$ReaderInputStream.writeAdditionalInputToPythonWorker(PythonRunner.scala:928)
org.apache.spark.api.python.BasePythonRunner$ReaderInputStream.read(PythonRunner.scala:851)
java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
java.io.BufferedInputStream.read(BufferedInputStream.java:265) => holding Monitor(java.io.BufferedInputStream@1972989904})
java.io.DataInputStream.readInt(DataInputStream.java:387)
org.apache.spark.sql.execution.python.PythonArrowOutput$$anon$1.read(PythonArrowOutput.scala:104)
org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:635)
org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
org.apache.spark.sql.execution.datasources.FileFormatDataWriter.writeWithIterator(FileFormatDataWriter.scala:91)
org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeTask$2(FileFormatWriter.scala:531)
org.apache.spark.sql.execution.datasources.FileFormatWriter$$$Lambda$2268/313061404.apply(Unknown Source)
org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1743)
org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:538)
org.apache.spark.sql.execution.datasources.WriteFilesExec.$anonfun$doExecuteWrite$1(WriteFiles.scala:116)
org.apache.spark.sql.execution.datasources.WriteFilesExec$$Lambda$2117/703248354.apply(Unknown Source)
org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:931)
org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:931)
org.apache.spark.rdd.RDD$$Lambda$2113/847512910.apply(Unknown Source)
org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:60)
org.apache.spark.rdd.RDD.$anonfun$computeOrReadCheckpoint$1(RDD.scala:407)
org.apache.spark.rdd.RDD$$Lambda$1350/1516776629.apply(Unknown Source)
com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:404)
org.apache.spark.rdd.RDD.iterator(RDD.scala:371)
org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:82)
org.apache.spark.scheduler.ResultTask$$Lambda$2058/1782952762.apply(Unknown Source)
com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:82)
org.apache.spark.scheduler.ResultTask$$Lambda$2055/2060074874.apply(Unknown Source)
com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:62)
org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:196)
org.apache.spark.scheduler.Task.doRunTask(Task.scala:181)
org.apache.spark.scheduler.Task.$anonfun$run$5(Task.scala:146)
org.apache.spark.scheduler.Task$$Lambda$1135/1245833457.apply(Unknown Source)
com.databricks.unity.EmptyHandle$.runWithAndClose(UCSHandle.scala:125)
org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:146)
org.apache.spark.scheduler.Task$$Lambda$1117/2113811715.apply(Unknown Source)
com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
org.apache.spark.scheduler.Task.run(Task.scala:99)
org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$8(Executor.scala:897)
org.apache.spark.executor.Executor$TaskRunner$$Lambda$1115/949204975.apply(Unknown Source)
org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1709)
org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:900)
org.apache.spark.executor.Executor$TaskRunner$$Lambda$1071/753832407.apply$mcV$sp(Unknown Source)
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:795)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:750)
The thing is that this class
DirectByteBufferOutputStream
should be introduced only in spark 4.0.0 (SPARK-44705 ) and it corresponds to significant changes for PythonRunner
Looks like there is a problem with the allocation relatively big amount of memory.
Here are steps to reproduce the issue:
driver: r5d.large
executor: r5d.xlarge
from random import random
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
import pandas as pd
import time
def long_running_pandas_udf(pdf:pd.DataFrame):
time.sleep(random() * 20)
print("printing for simulating logging from python function")
return pdf
def test_df():
data = []
# create a big table of data. we need to make it relatevly heavy.
dict_ = {f"some_field{i}": f"{random()}" for i in range(36)}
for i in range(100_000):
dict_1 = {k: v for k, v in dict_.items()}
dict_1.update({f"group_key": '0'})
data.append(dict_1)
dict_2 = {k: v for k, v in dict_.items()}
dict_2.update({f"group_key": '1'})
data.append(dict_2)
df = spark.createDataFrame(data)
return df
# increase the size of final dataset even more
ndf = df
for i in range(4):
ndf = ndf.unionAll(ndf)
result = ndf.groupBy("group_key").applyInPandas(long_running_pandas_udf, schema=df.schema)
result.write.mode("overwrite").parquet(some_path)
This code hangs with the thread dump above.
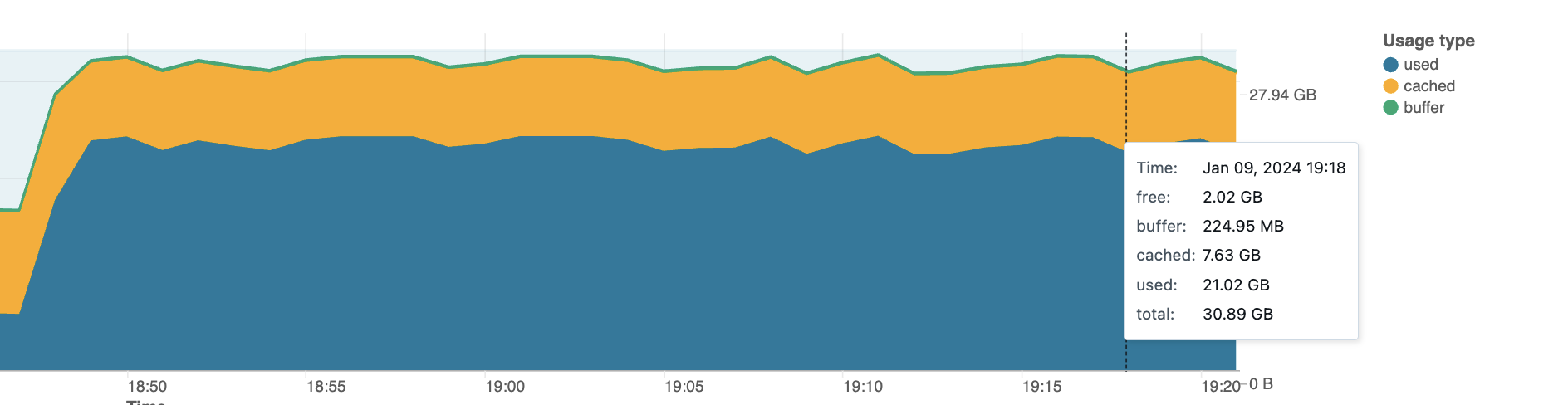
I'll also include screenshots of memory consumption, etc.
Note that this code finishes successfully with the same cluster config on runtime 12.2 LTS ML.
So there are two concerns:
1. looks like runtimes contain patched versions of spark. These patches are poorly tested.
2. This workload will pass if I significantly increase node sizes, but it is meaningless if the job succeeds on the same cluster with the previous version of the runtime







{kind=link}
{kind=link}