Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Autoloader works on compute cluster, but does ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2023 12:49 AM
I feel like I am going crazy with this. I have tested a data pipeline on my standard compute cluster. I am loading new files as batch from a Google Cloud Storage bucket. Autoloader works exactly as expected from my notebook on my compute cluster. Then, I simply used this notebook as a first task in a workflow using a new job cluster. In order to test this pipeline as a workflow I first removed all checkpoint files and directories before starting the run using this command.
dbutils.fs.rm(checkpoint_path, True)
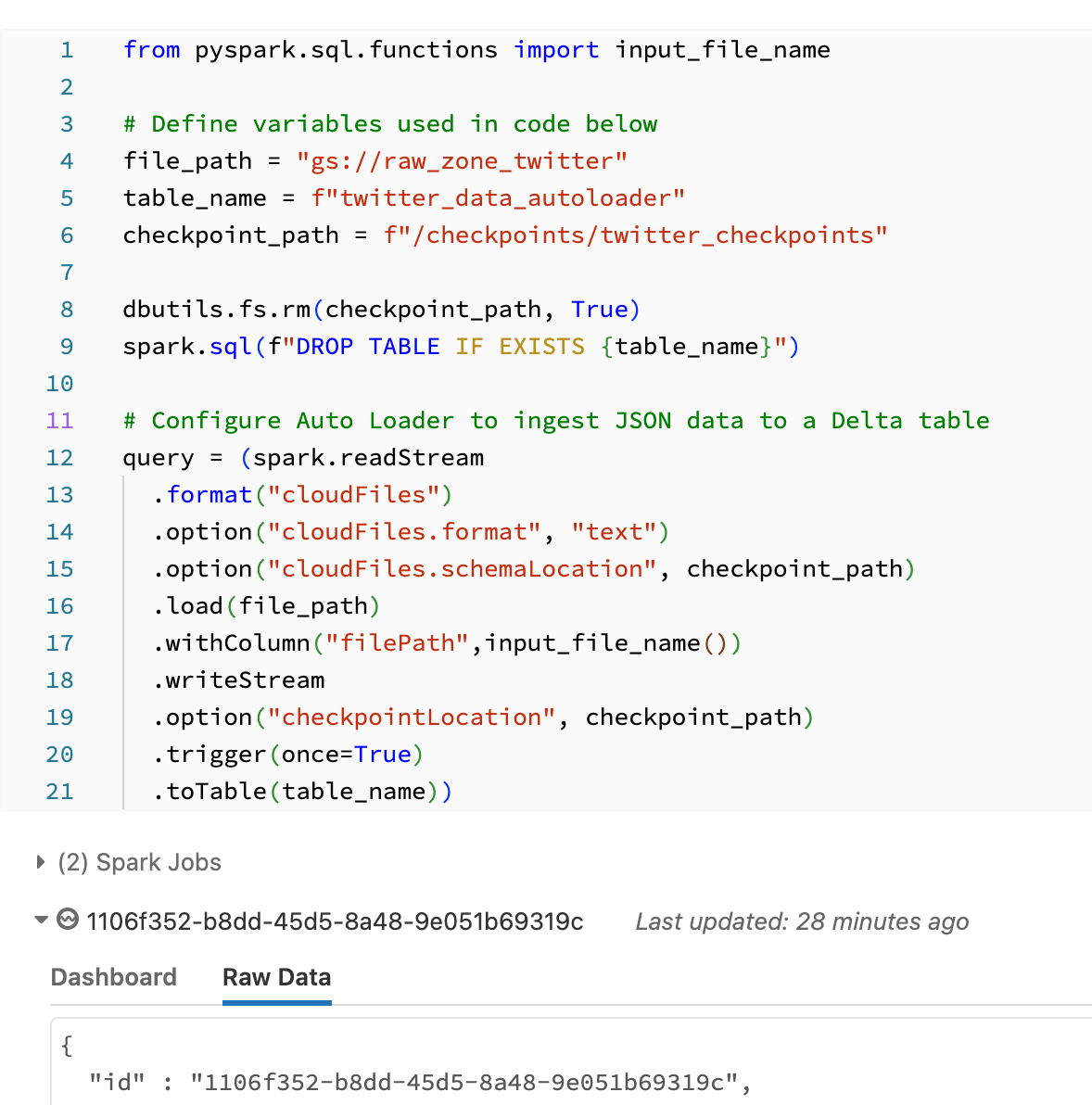
For some reason, the code works perfectly when testing, but in workflows, I get "streaming stopped" and no data from autoloader. Here is my config for autoloader:
file_path = "gs://raw_zone_twitter"
table_name = f"twitter_data_autoloader"
checkpoint_path = f"/tmp/_checkpoint/twitter_checkpoint"
spark.sql(f"DROP TABLE IF EXISTS {table_name}")
query = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "text")
.option("cloudFiles.schemaLocation", checkpoint_path)
.load(file_path)
.withColumn("filePath", input_file_name())
.writeStream
.option("checkpointLocation", checkpoint_path)
.trigger(once=True)
.toTable(table_name))
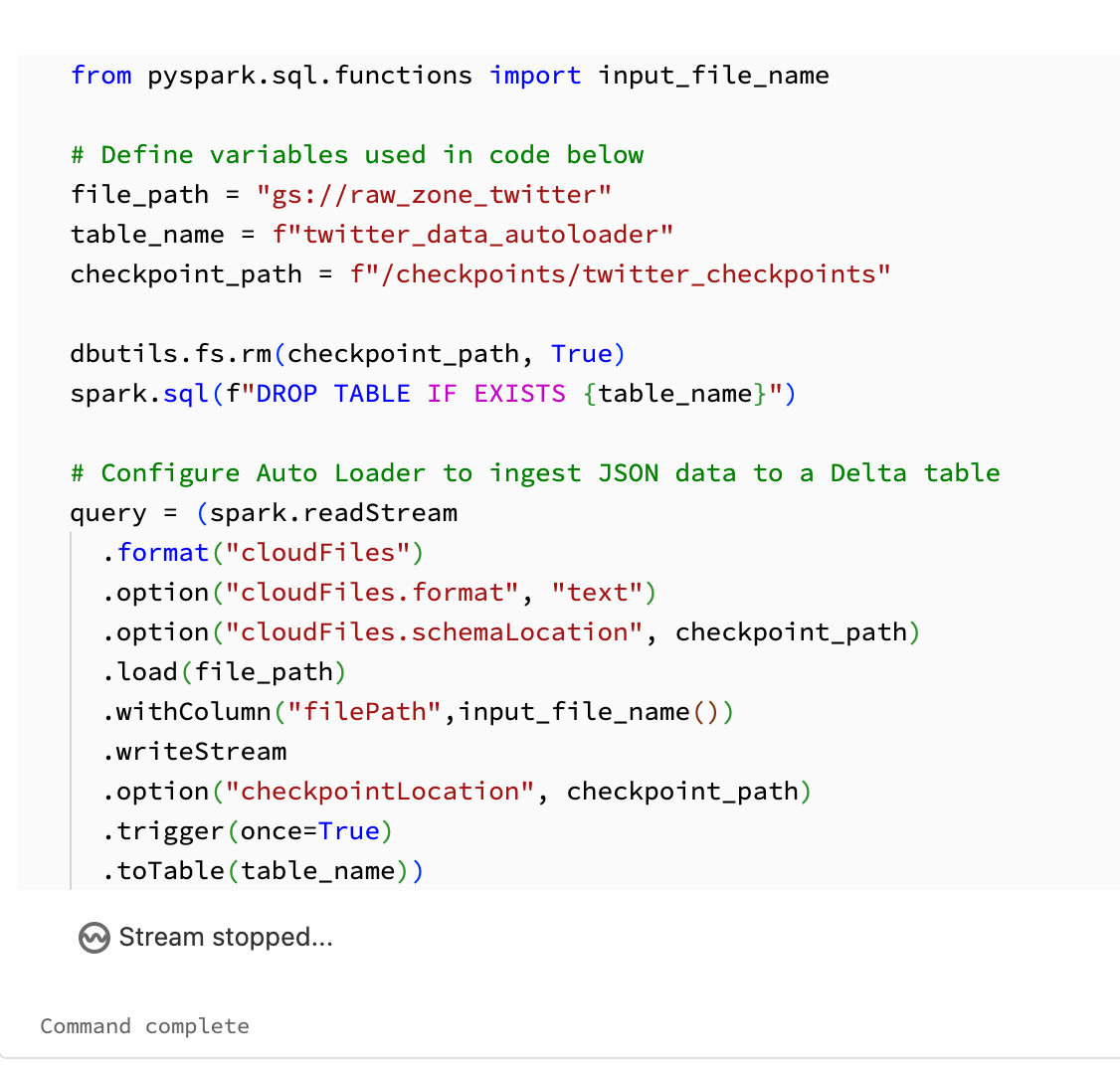
When running this as a workflow I see that the checkpoint directory is created, but there is no data inside.
The code between testing on my compute cluster, and the task in my workflow is exactly the same (same notebook), so I really have no idea why autoloader is not working within my workflow...


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-23-2023 07:09 AM
I found the issue. I describe the solution in the following SO post. https://stackoverflow.com/questions/76287095/databricks-autoloader-works-on-compute-cluster-but-does...
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2023 03:42 AM
@Vidula Khanna I see you have responded to previous autoloader questions. Can you help me?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-22-2023 08:54 AM
Still no progress on this. I want to confirm that my cluster configurations are identical in my notebook running on my general purpose compute cluster and my job cluster. Also I am using the same GCP service account. On my compute cluster autoloader works exactly as expected. Here is the code being used for autoloader (this works on compute cluster).

However, when I run this exact same code (from the same notebook) as a job autoloader stops the stream (it seems at .writeStream) and i simply see "stream stopped" with no real clue as to why, as seen below.


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-22-2023 09:17 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-23-2023 07:09 AM
I found the issue. I describe the solution in the following SO post. https://stackoverflow.com/questions/76287095/databricks-autoloader-works-on-compute-cluster-but-does...
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Autoscaling with the autoloader without SDP in Data Engineering
- Best option for parallel processing in Data Engineering
- Databricks workflows for APIs with different frequencies (cluster keeps restarting) in Data Engineering
- setup justfile command in order to launch your spark application in Data Engineering
- Cost-Effective Databricks Pipeline for API Ingestion - Best Practices? in Data Engineering