Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: BQ partition data deleted fully even though 's...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-10-2024 11:00 PM
We have a date (DD/MM/YYYY) partitioned BQ table. We want to update a specific partition data in 'overwrite' mode using PySpark. So to do this, I applied 'spark.sql.sources.partitionOverwriteMode' to 'DYNAMIC' as per the spark bq connector documentation. But still it deleted the other partitioned data which should not be happening.
df_with_partition.write.format("bigquery") \
.option("table", f"{bq_table_full}") \
.option("partitionField", f"{partition_date}") \
.option("partitionType", f"{bq_partition_type}") \
.option("temporaryGcsBucket", f"{temp_gcs_bucket}") \
.option("spark.sql.sources.partitionOverwriteMode", "DYNAMIC") \
.option("writeMethod", "indirect") \
.mode("overwrite") \
.save()
Can anyone please suggest me what I am doing wrong or how to implement this dynamic partitionOverwriteMode. Many thanks.
#pyspark #overwrite #partition #dynamic #bigquery


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-13-2025 10:18 PM
22 REPLIES 22
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-11-2024 03:36 AM
It appears that the issue is related to the behavior of the Spark BigQuery connector and how it handles partition overwrites. Here are a few points to consider:
-
Ensure that the configuration setting spark.sql.sources.partitionOverwriteMode is correctly applied. This can be set at the session level using spark.conf.set("spark.sql.sources.partitionOverwriteMode", "DYNAMIC") before performing the write operation.
- If the dynamic partition overwrite mode is not working as expected, you might consider using the replaceWhere option as an alternative. This option allows you to specify a condition to selectively overwrite data. For example:
df_with_partition.write.format("bigquery") \
.option("table", f"{bq_table_full}") \
.option("partitionField", f"{partition_date}") \
.option("partitionType", f"{bq_partition_type}") \
.option("temporaryGcsBucket", f"{temp_gcs_bucket}") \
.option("replaceWhere", f"{partition_date} = 'specific_date'") \
.mode("overwrite") \
.save()
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-11-2024 11:52 PM - edited 12-11-2024 11:55 PM
Hi @Walter_C ,
Thank you for your response over this issue.
I tried both the options:
- setting up the spark configuration at session level, but did not work
- used the replaceWhere option for a specific partition date, but that also did not work.
In both the cases, all bq table records are getting overwritten or deleted for all partition dates which is not acceptable.
I checked the spark bq connector documentation page, I could not find the 'replaceWhere' option as well.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2024 06:39 AM
Got it, can you also test the following code:
df_with_partition.write.format("bigquery") \
.option("table", f"{bq_table_full}") \
.option("partitionField", f"{partition_date}") \
.option("partitionType", f"{bq_partition_type}") \
.option("temporaryGcsBucket", f"{temp_gcs_bucket}") \
.option("partitionOverwriteMode", "dynamic") \
.option("writeMethod", "indirect") \
.mode("overwrite") \
.save()Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2024 06:48 AM
I already tried this before, which was not worked. Then I tried with 'DYNAMIC' instead of 'dynamic'. But no luck.
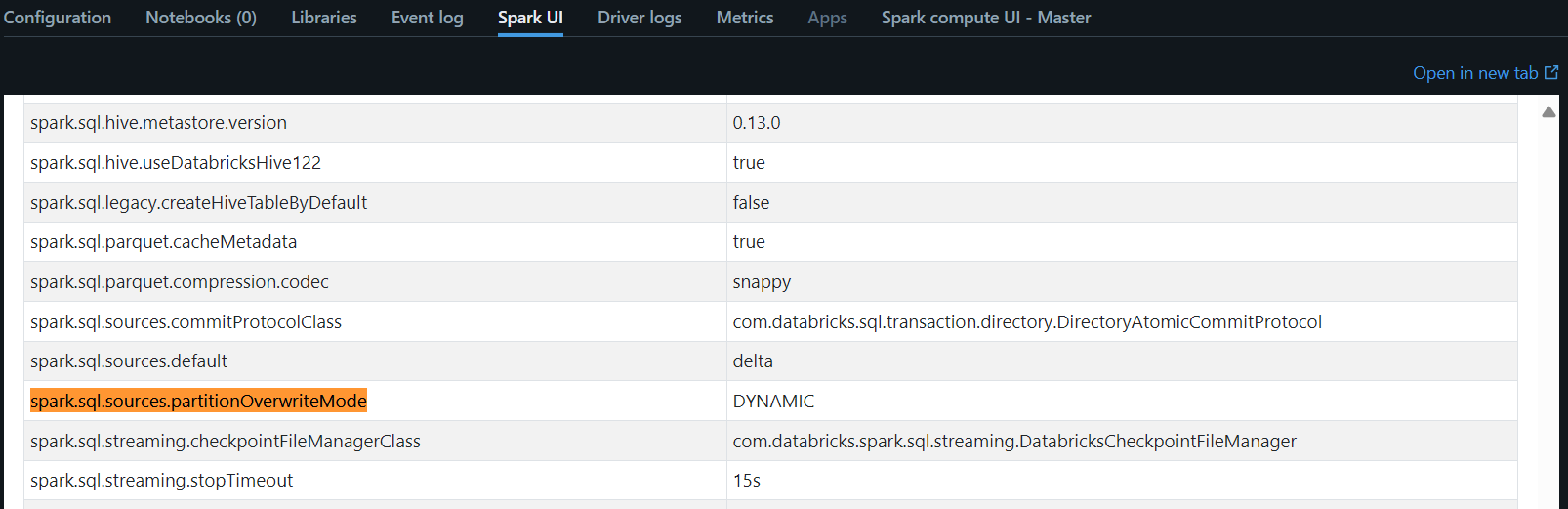
One thing I found that, even though I set the 'spark.sql.sources.partitionOverwriteMode' to 'DYNAMIC' in cluster advance options or even in the notebook before writer dataframe, in all the cases, this partitionOverwriteMode property is not being actually set up in the Spark UI SQL/Dataframe Properties whereas I can see the other properties very well which I set up during cluster creation or even in the notebook.
So this could be the problem with 'spark.sql.sources.partitionOverwriteMode' property set up within the databricks cluster. Any idea how to overcome this?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2024 07:15 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2024 07:34 AM
I reviewed this with an Spark resource, seems that for this Indirect method will be required, you can follow information in https://github.com/GoogleCloudDataproc/spark-bigquery-connector?tab=readme-ov-file#indirect-write
BigQuery data source for Apache Spark: Read data from BigQuery into DataFrames, write DataFrames into BigQuery tables. - GoogleCloudDataproc/spark-bigquery-connector
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2024 10:21 PM
I raised an issue to spark-biquery-connector where they mentioned to use 'spark-3.5-bigauery-0.41.0.jar' whereas I was using Databricks Runtime Version: 15.4 LTS (includes Apache Spark 3.5.0, Scala 2.12) which include spark-bigquery-with-dependencies_2.12-0.41.0.jar.
So, I tried this:
spark_v1 = SparkSession.builder \
.appName("SampleSparkSession") \
.config("spark.jars.packages", "/Workspace/Users/xxxxxxx@xxxx.xxxx/spark-3.5-bigquery-0.41.0.jar") \
.config("spark.jars.excludes", "/databricks/jars/spark-bigquery-with-dependencies_2.12-0.41.0.jar") \
.getOrCreate()But apply the above include and exclude the packages using spark config, the jars not even included or excluded in the actual running cluster. (by checking the Spark UI System Properties)
So, any idea how these jars can be included or excluded to the Databricks cluster which is using Databricks Runtime Version: 15.4 LTS.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2024 04:03 AM
-
Remove the Default JAR:
- Since
spark-bigquery-with-dependencies_2.12-0.41.0.jaris included by default in Databricks Runtime 15.4 LTS, and you need to exclude it. This can be done by creating an init script to remove the JAR file from the cluster.
- Since
-
Create an Init Script:
-
Create an init script that removes the default
spark-bigquery-with-dependencies_2.12-0.41.0.jarfrom the cluster. Here is an example of what the script might look like:#!/bin/bash rm /databricks/jars/spark-bigquery-with-dependencies_2.12-0.41.0.jar
-
-
Upload the Init Script:
- Upload this script to a location accessible by Databricks, such as DBFS (Databricks File System).
-
Configure the Cluster to Use the Init Script:
- Go to the cluster configuration page in Databricks.
- Under the "Advanced Options" section, find the "Init Scripts" tab.
- Add the path to your init script (e.g.,
dbfs:/path/to/your/init-script.sh).
-
Add the Custom JAR:
- Upload the
spark-3.5-bigquery-0.41.0.jarto DBFS or another accessible location. - In the cluster configuration, go to the "Libraries" tab.
- Choose "Install New" and select "DBFS" or the appropriate option where your JAR is stored.
- Provide the path to the
spark-3.5-bigquery-0.41.0.jar.
- Upload the
-
Restart the Cluster:
- Restart the cluster to apply the changes. The init script will run, removing the default JAR, and the new JAR will be added to the cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-22-2024 11:09 PM
The init_script worked to remove the unwanted jars from the cluster. This is good news.
But whenever I tried to install the required jar on cluster configuration using library source as GCS path (gs://spark-lib/bigquery/spark-3.5-bigquery-0.41.0.jar), the UI shows that the jar is installed. Then when I execute the notebook to run the spark job, it returned me the below error which indicate that either the spark session unable to identify the spark-bigquery-connector jar or the jar is not installed successfully.
Py4JJavaError: An error occurred while calling o574.save.
: org.apache.spark.SparkClassNotFoundException: [DATA_SOURCE_NOT_FOUND] Failed to find the data source: com.google.cloud.spark.bigquery.BigQueryRelationProvider. Make sure the provider name is correct and the package is properly registered and compatible with your Spark version. SQLSTATE: 42K02I tried to verify whether the jar was installed on the cluster successfully or not by checking the Spark UI classpath properties or even other properties. But could not found such. Screenshot attached below to refer that the jar was installed from GCS path.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-31-2024 02:34 AM
@soumiknow this sounds like the jar was probably installed, but not distributed to the spark cluster, do you see from the Spark logs (Driver/Executors) the jar getting distributed and localized? You may also add the classloading verbose flag to understand if there's a problem with some older version getting distributed before this new jar is placed first in the classpath.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-31-2024 04:59 AM
Hi @VZLA ,
Please guide me to find whether the jar getting distributed and localized as well as how to add the classloading verbose flag.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-31-2024 05:32 AM
You can add to both the driver and executors extraJavaOptions the -verbose:class option, and then check the Spark Logs, example:
- spark.driver.extraJavaOptions -verbose:class
- spark.executor.extraJavaOptions -verbose:class
Same with regard to the jar distribution and localization, this will be visible in the Spark Logs.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2025 11:49 PM
Hi @VZLA ,
I added the extraJavaOptions and after that I can see the following the in the logs:
downloading https://maven-central.storage-download.googleapis.com/maven2/com/google/cloud/spark/spark-bigquery-connector-common/0.41.0/spark-bigquery-connector-common-0.41.0.jar ...
[SUCCESSFUL ] com.google.cloud.spark#spark-bigquery-connector-common;0.41.0!spark-bigquery-connector-common.jar (379ms)
:: modules in use:
com.google.cloud.spark#bigquery-connector-common;0.41.0 from preferred-maven-central-mirror in [default]
com.google.cloud.spark#spark-3.5-bigquery;0.41.0 from preferred-maven-central-mirror in [default]
com.google.cloud.spark#spark-bigquery-connector-common;0.41.0 from preferred-maven-central-mirror in [default]
com.google.cloud.spark#spark-bigquery-dsv2-common;0.41.0 from preferred-maven-central-mirror in [default]When I execute my notebook, it returned the same error:
Py4JJavaError: An error occurred while calling o438.save.
: org.apache.spark.SparkClassNotFoundException: [DATA_SOURCE_NOT_FOUND] Failed to find the data source: com.google.cloud.spark.bigquery.BigQueryRelationProvider. Make sure the provider name is correct and the package is properly registered and compatible with your Spark version. SQLSTATE: 42K02Can you please suggest any Databricks Runtime Version which include spark-bigquery-connector version 0.41.0 with spark 3.5?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2025 08:11 AM - edited 01-03-2025 08:13 AM
- This is not the output from -verbose:class, what you see is likely coming from importing the library from an external repository and its showing the add dependencies process. Telling it has pulled and downloaded the "com.google.cloud.spark#spark-bigquery-connector-common;0.41.0!spark-bigquery-connector-common.jar", which is probably added via a sparkSession or Cluster Library with Maven as source. The verbose:class flag, prints in the STDOUT output, something like this(classloading):
- [Loaded com.google.cloud.spark.bigquery.BigQueryRelationProvider from file:/databricks/jars/----ws_3_5--third_party--bigquery-connector--spark-bigquery-connector-hive-2.3__hadoop-3.2_2.12--118181791--fatJar-assembly-0.22.2-SNAPSHOT.jar]
- In DBR 15.4 LTS, which you're already using, you also have already available the:
- ----ws_3_5--third_party--bigquery-connector--spark-bigquery-connector-hive-2.3__hadoop-3.2_2.12--118181791--fatJar-assembly-0.22.2-SNAPSHOT.jar, and
- ----ws_3_5--third_party--bigquery-connector--spark-bigquery-connector-upgrade_scala-2.12--118181791--spark-bigquery-with-dependencies_2.12-0.41.0.jar
- The answer you got from the Google Support team, is referring to the fatJar-assembly-0.22.2-SNAPSHOT. But the spark-bigquery v0.22, does have the "com.google.cloud.spark.bigquery.BigQueryRelationProvider" available as you can see in here https://github.com/GoogleCloudDataproc/spark-bigquery-connector/blob/branch-0.22/connector/src/main/... So the problem you're running into, is not related to the jar file version itself.
So at this point you have two different issues, 1) Need to use the v0.40, and 2) Currently getting a DATA_SOURCE_NOT_FOUND error.
- If you encounter the DATA_SOURCE_NOT_FOUND error, it means the data source name provided to Spark is not resolvable either in its built-in registry or through any dynamically loaded libraries. I'm honestly unsure how are you running into this error, and would need your clarification comments about the current cluster status and setup to help you with it. If I had to guess, I would say you have manually deleted this fat jar v0.20 from the cluster altogheter, using an init script maybe?
- When you call "format("bigquery")" this is what will happen behind the scenes in the DataSource.scala:
case name if name.equalsIgnoreCase("bigquery") => "com.google.cloud.spark.bigquery.BigQueryRelationProvider" - So lookupDataSource will try to find the "com.google.cloud.spark.bigquery.BigQueryRelationProvider" and then Spark instantiates the "BigQueryRelationProvider". In other words, when you use spark.read.format("bigquery"), Spark uses this mapping to locate and load the appropriate class.
Could you please run this from a notebook in DBR 15.4 LTS with no additional libraries attached to it:
%python
class_name = "com.google.cloud.spark.bigquery.BigQueryRelationProvider"
try:
# Get the class reference
cls = spark._jvm.Thread.currentThread().getContextClassLoader().loadClass(class_name)
# Get the JAR file path
jar_path = cls.getProtectionDomain().getCodeSource().getLocation().getPath()
print(f"The class {class_name} is loaded from: {jar_path}")
except Exception as e:
print(f"Error locating the class {class_name}: {e}")
It should return:
The class com.google.cloud.spark.bigquery.BigQueryRelationProvider is loaded from: /databricks/jars/----ws_3_5--third_party--bigquery-connector--spark-bigquery-connector-hive-2.3__hadoop-3.2_2.12--118181791--fatJar-assembly-0.22.2-SNAPSHOT.jar
If it does not then, the reason clearly is the absence of a jar file with the class mentioned in the error message.
The MVN output you've shared though is actually interesting, solely based on my personal assumption, you've attempted to add the spark-bigquery artifact through Cluster Library with Maven as source, but the artifact that you have pulled does not have the BigQueryRelationProvider as well, if you're ok with going with the latest version, the Maven coordinates you should be using are "com.google.cloud.spark:spark-bigquery_2.12:0.41.1"
Then rerunning the same code:
class_name = "com.google.cloud.spark.bigquery.BigQueryRelationProvider"
try:
cls = spark._jvm.Thread.currentThread().getContextClassLoader().loadClass(class_name)
jar_path = cls.getProtectionDomain().getCodeSource().getLocation().getPath()
print(f"The class {class_name} is loaded from: {jar_path}")
# Print the package information (often contains version info)
package = cls.getPackage()
print(f"Package Specification Title: {package.getSpecificationTitle()}")
print(f"Package Specification Version: {package.getSpecificationVersion()}")
print(f"Package Implementation Version: {package.getImplementationVersion()}")
except Exception as e:
print(f"Error: {e}")
Should return:
The class com.google.cloud.spark.bigquery.BigQueryRelationProvider is loaded from: /local_disk0/tmp/addedFile235d6f3b981a4f61bb72e599c2d013986386268607538077001/com_google_cloud_spark_spark_bigquery_2_12_0_41_1.jar
Package Specification Title: BigQuery DataSource v1 for Scala 2.12
Package Specification Version: 0.41
Package Implementation Version: 0.41.1
Whether the library and your current cluster status after the changes is stable, supported or not, I'm not sure., but you're always welcome to raise a support ticket and one of our engineers will kindly continue with the assistance.
Announcements





{kind=link}
{kind=link}
Related Content
- Getting 'Unauthorized Access' when Serverless compute is trying to read s3 bucket data in Data Engineering
- CHECKPOINT_RDD_BLOCK_ID_NOT_FOUND randomly appears in Data Engineering
- Lakeflow Connect - Pending ‘full refresh’ process that needs to be removed in gateway pipeline. in Data Engineering
- Auto CDC Delete Propagation Issue: Streaming CDF Reads Don't Capture Delete Events from Auto CDC in Data Engineering
- DISTINCT is the major bottleneck because of the heavy shuffle. in Data Engineering