Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Data ingest of csv files from S3 using Autoloa...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Data ingest of csv files from S3 using Autoloader is slow
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2022 01:44 PM
I have 150k small csv files (~50Mb) stored in S3 which I want to load into a delta table.
All CSV files are stored in the following structure in S3:
bucket/folder/name_00000000_00000100.csv
bucket/folder/name_00000100_00000200.csv
This is the code I use to start the auto loader:
## mount external s3 bucket
dbutils.fs.mount(f"s3a://{access_key}:{encoded_secret_key}@{aws_bucket_name}", f"/mnt/{mount_name}")
## autoloader function
def autoload_csv (data_source, table_name, checkpoint_path, schema):
query = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header","true")
.option("delimiter", ";")
.option("rescuedDataColumn", "_rescue")
.schema(schema)
.load(data_source)
.withColumn("timestamp",col("timestamp").cast(TimestampType()))
.writeStream.format("delta")
.trigger(once=True)
.option("mergeSchema", "true")
.option("checkpointLocation", checkpoint_path)
.toTable(tableName=table_name)
)
return query
## Define schema
schema = StructType([
StructField("timestamp", LongType(), True),
StructField(“aaa”, LongType(), True),
StructField(“bbb”, LongType(), True),
StructField(“ccc”, LongType(), True),
StructField(“eee”, LongType(), True),
StructField(“fff”, LongType(), True),
StructField(“ggg”, StringType(), True),
])
## start script (schema is
input_data_path = ‘/input_data
table_name = ‘default.input_data’
chkpt_path = '/tmp/input_data/_checkpoints'
query = autoload_csv(data_source=input_data_path, table_name=table_name,checkpoint_path=chkpt_path, schema=schema)It takes two hours on eight 4 core/32GB RAW workers to import all files right now. There must be something wrong.
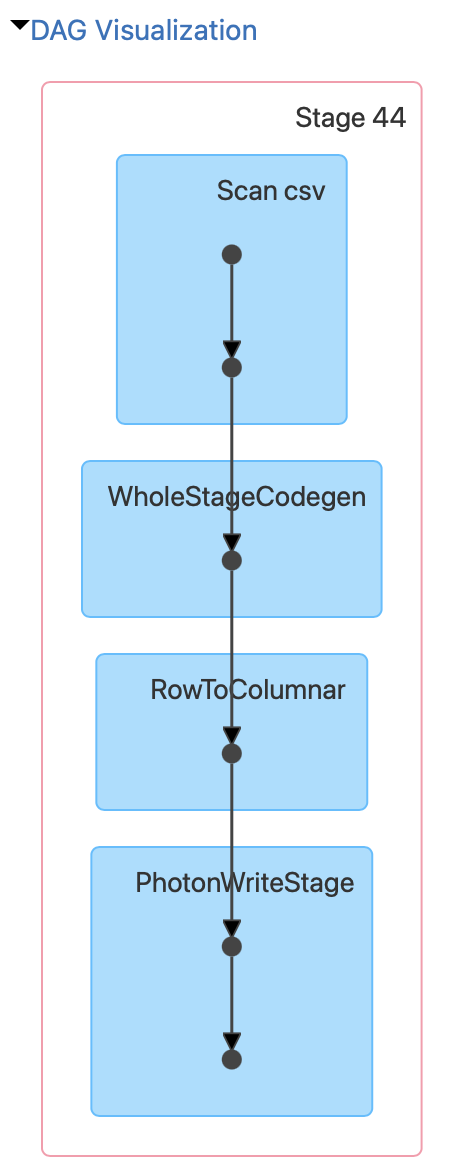
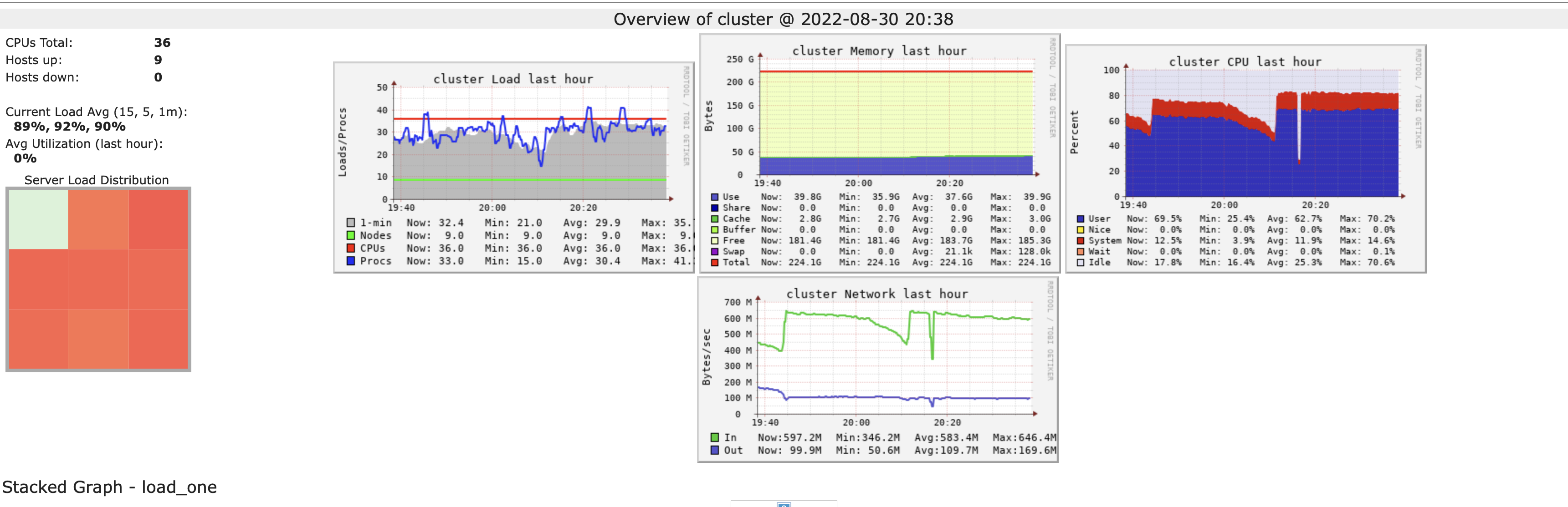
I have attached the following images:
- Cluster overview
- Cluster metrics (Ganglia)
- SparkUI (DAG, Event Timeline, Job)
How can I speed up the data import?
How can I debug the issue further by myself?





EDIT:
I just tried the same import pipeline with the same number but smaller files (<1Mb). I noticed that it runs more smoothly when I delete trigger(once=True). Unfortunately this doesn't help with bigger files. With bigger files the auto loader takes for ever to initialise the stream.
Labels:
- Labels:
-
Data


7 REPLIES 7
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2022 08:19 PM
50mb in total or each of your 150,000 files is of size 50mb which is approx 7.15 TB?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-30-2022 10:43 PM
Some files are a bit smaller some are a bit bigger. All files combined are probably between 4.5TB and 7 TB.
The import is also slow for much smaller files. I tried the same setup for 100k small files (<1MB) and it also takes a while (see edit).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2022 04:46 PM
You are using .trigger(once=True) so it will try to process all the data in a single micro-batch. I will recommend to use availableNow trigger to process your data in multiple micro-batches. Then you can check streaming metrics to check how many records per batch are you processing and how long is taking
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2022 06:29 PM
Good pointer thank you! Is the feature also available in Python? Looking at the docs it looks like it's only available in Scala.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-31-2022 12:47 AM
You should be using a cluster with a heavy drive node with 2-4 worker nodes. As this is just inserts and no joins are being performed.
Use like an i3.4xl driver and i3.xl worker type.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-09-2022 06:17 PM
Hi,
I have ran more experiments regarding the data throughput. Will share my results soon.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-17-2022 12:45 AM
Hi @Jan R
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Data Engineering
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Administration & Architecture
- Zerobus ingestion fails in Databricks in Administration & Architecture
- Zerobus ingestion fails in Databricks Free Edition using Service Principal OAuth in Administration & Architecture
- Lakeflow connect Native connectors (tik, meta ads, Google Ads) - one table per account in Data Engineering