Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: DLT Pipeline failed to Start due to "The Exec...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
DLT Pipeline failed to Start due to "The Execution Contained atleast one disallowed language
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 03:12 AM
Hi ,
im trying to setup DLT pipeline ,its a basic pipeline for testing purpose im facing the issue while starting the pipeline , any help is appreciated


@dlt.table(name="dlt_bronze_cisco_hardware")
def dlt_cisco_networking_bronze_hardware():
return (
spark.readStream.format("cloudFiles")\
.option("cloudFiles.format", "json")\
.option("cloudFiles.schemaLocation","abfss://adt-calfit-adls@adtedfdatalake.dfs.core.windows.net/DLT_Schema")\
.load("abfss://adt-calfit-adls@adtedfdatalake.dfs.core.windows.net/Landing/DLT_Testing/Hardware/*/*/*/*.json")
)
Labels:
- Labels:
-
DLT
-
DLT Pipeline


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 04:47 AM
HI @Arumugam Ramachandran ,
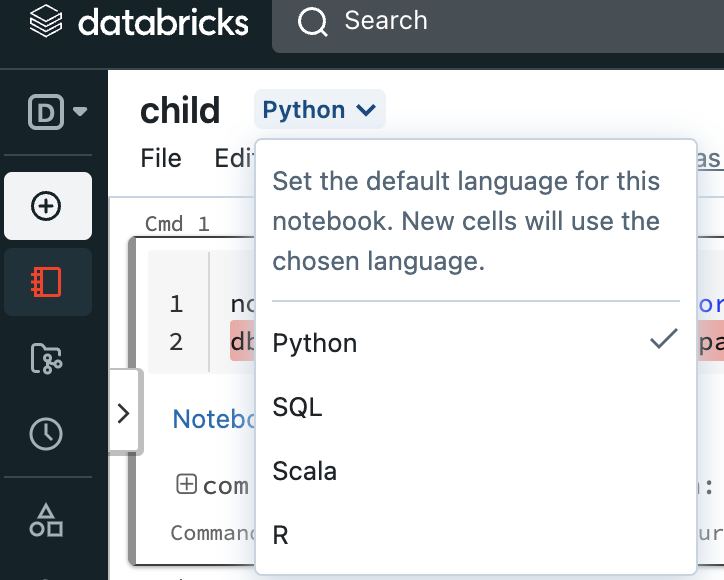
first though - did you chose PYTHON CELL for your code?
or maybe this post will help: https://community.databricks.com/s/question/0D58Y00009DD3LZSA1/python-code-not-working-in-dbr-104-lt...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 05:23 AM
Hi Pat , Yes i have selected Python as the script for the cell
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 05:30 AM
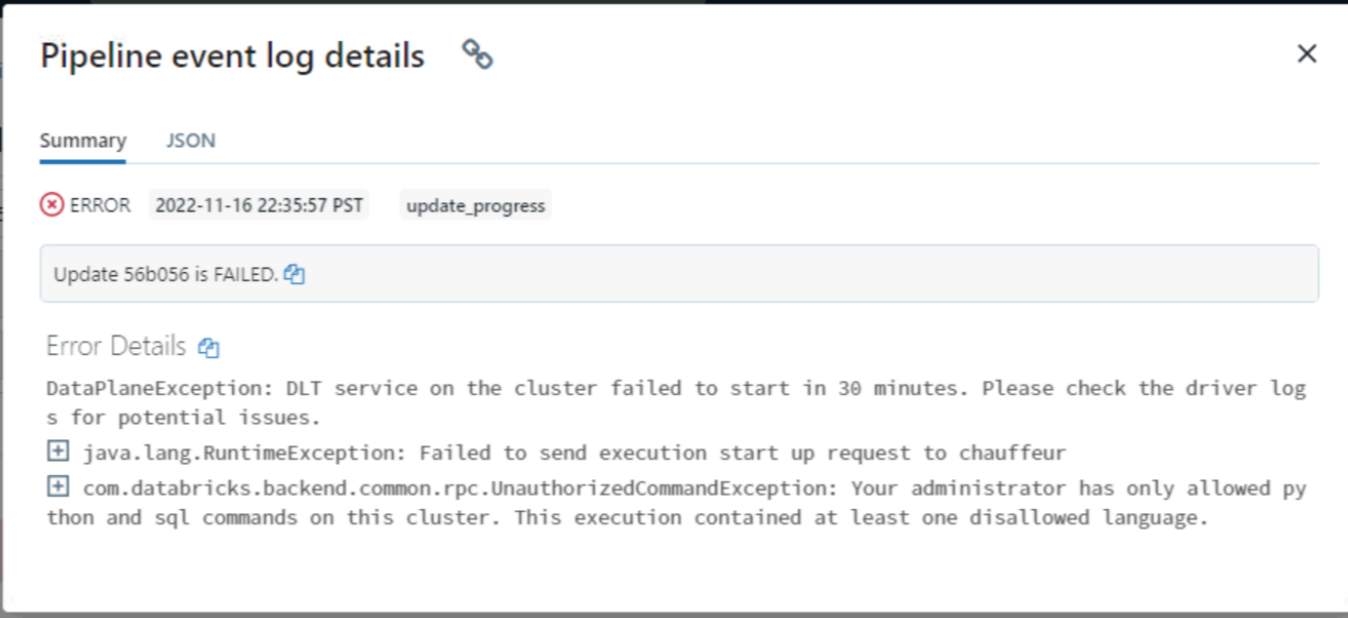
Hi @Arumugam Ramachandran seems like you have a spark config set on your DLT job cluster that allows only python and SQL code. Check the spark config (cluster policy).
In any case, the python code should work. Verify the notebook's default language, it should not be scala.

https://docs.databricks.com/notebooks/notebooks-manage.html#execution-contexts
Mark a comment as 'best answer' to resolve the query, thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 06:40 AM
Hi vivian , the notebook has default as python , but still facing the issue
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 07:04 AM
@Arumugam Ramachandran Please remove "spark.databricks.repl.allowedLanguages" config for the DLT clusters if you have it in the policy. DLT only works with python and SQL notebook anyways and we don't need to explicitly set this config.
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Read each cell contains SQL from one notebook and execute it on another notebook and export result in Data Engineering
- Asset Bundles Scala in Data Engineering
- Permission on Hive Metastore DBX 10.4 in Data Governance
- Hive Metastore permission on DBX 10.4 Cluster in Data Governance
- Hive Metastore Schema Permissions in Data Governance