Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: High cost of storage when using structured str...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
High cost of storage when using structured streaming
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-08-2023 02:12 PM
Hi there,
I read data from Azure Event Hub and after manipulating with data I write the dataframe back to Event Hub (I use this connector for that):
#read data
df = (spark.readStream
.format("eventhubs")
.options(**ehConf)
.load()
)
#some data manipulation
#write data
ds = df \
.select("body", "partitionKey") \
.writeStream \
.format("eventhubs") \
.options(**output_ehConf) \
.option("checkpointLocation", "/checkpoin/eventhub-to-eventhub/savestate.txt") \
.trigger(processingTime='1 seconds') \
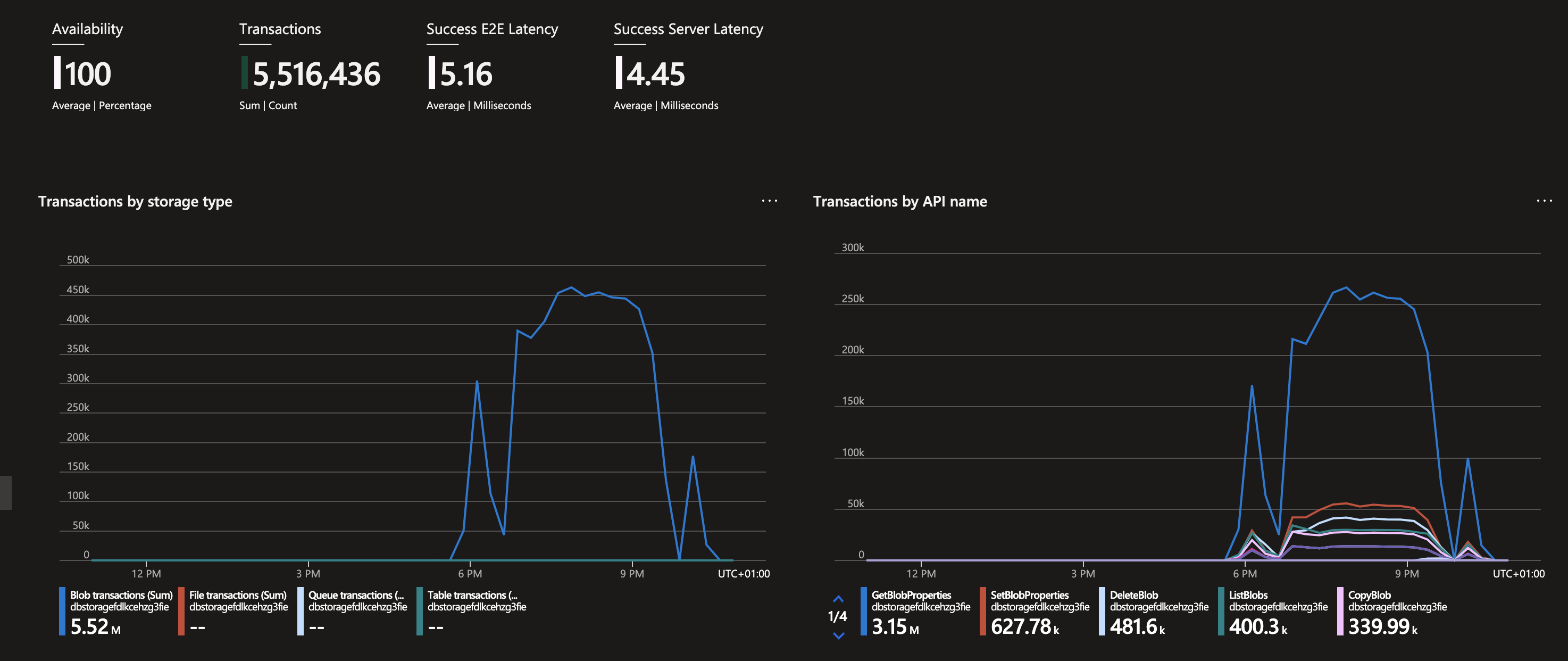
.start()In this case, I get high storage costs, which far exceed my computational costs (4 times). The expense is caused by a large number of transactions to the storage:

Question: am I using structured streaming correctly, and if so, how can I optimize storage costs?
Thank you for your time!
Labels:


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2023 09:19 PM
Hi, Could you please refer https://www.databricks.com/blog/2022/10/18/best-practices-cost-management-databricks.html and let us know if this helps?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2023 10:42 AM
Debayan, thanks for your recommendation, I read this article, but it does not answer my question.
I'm just learning how to work with Databricks, and perhaps these costs are normal for structured stream processing?
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-12-2023 10:50 PM
Hi @Serhii Dovhanich
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-31-2023 06:22 AM
Hi,
I ran into the same problem today. The core of my problem was with an aggregation and join, my stream does not generate massive amounts of data but it still used 200 shuffle partitions. After scaling this down to 2 (you have to clear checkpoints to take effect) my transactions went down significantly. Hope this helps!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-31-2023 07:02 AM
I had the same problem when starting with databricks. As outlined above, it is the shuffle partitions setting that results in number of files equal to number of partitions. Thus, you are writing low data volume but get taxed on the amount of write (and subsequent sequentialread) operations. Lowering amount of shuffle partitions helps solve this. On top of that, consider using spark.sql.streaming.noDataMicroBatches.enabled so that empty microbatches are ignored.
Announcements





{kind=link}
Related Content
- V.E.N.K.A.T Framework™ in Data Engineering
- DLT pipeline cloning to another workspace. in Data Engineering
- How to Prepare Enterprise Data for AI Agents: A Practical Guide in Data Engineering
- PySpark AnalysisException: Ambiguous reference to field t when parsing nested JSON in Data Engineering
- Lakeflow SDP (DLT) produce external tables, or only UC-managed in Data Engineering