Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How to convert records in Azure Databricks del...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 08:42 AM
Let's say I have a delta table in Azure databricks that stores the staff details (denormalized).

I wanted to export the data in the JSON format and save it as a single file on a storage location. I need help with the databricks sql query to group/construct the data in the JSON format.
Here is the sample code and desired output:
Delta Table schema:
%sql
create table if not exists staff_details (
department_id int comment 'id of the department',
department_name string comment 'name of the department',
employee_id int comment 'employee id of the staff',
first_name string comment 'first name of the staff',
last_name string comment 'last name of the staff'
)
using deltaScript to populate the delta table:
%sql
insert into staff_details(department_id, department_name, employee_id, first_name, last_name)
values(1,'Dept-A',101,'Guru','Datt'), (1,'Dept-A',102,'Tom','Cruise'), (2,'Dept-B',201,'Angelina','Jolie')Show records:
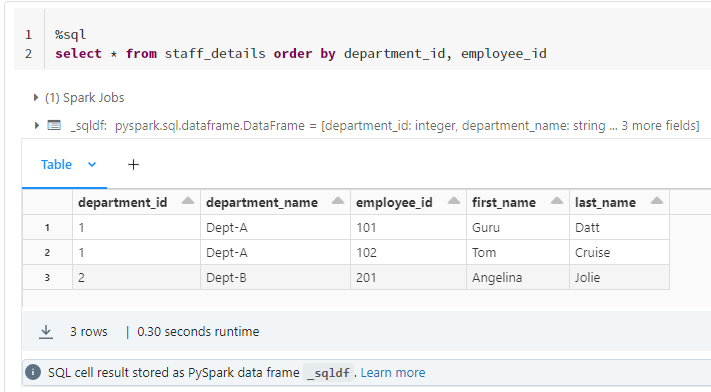
%sql
select * from staff_details order by department_id, employee_idDesired output:
{
"staff_details":[
{
"department_id":1,
"department_name": "Dept-A",
"staff_members": [
{
"employee_id":101,
"first_name":"Guru",
"last_name":"Datt"
},
{
"employee_id":102,
"first_name":"Tom",
"last_name":"Cruise"
}
]
},
{
"department_id":2,
"department_name": "Dept-B",
"staff_members": [
{
"employee_id":201,
"first_name":"Angelina",
"last_name":"Jolie"
}
]
}
]
}I tried using the to_json() function, and also using manual string concatenation with group by etc, but none of that is working well.
Please help.
Labels:


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 02:02 PM
If you want to do this in SQL, here you go:
%sql
select department_id, department_name, collect_list(struct(employee_id, first_name, last_name)) as staff_members
from staff_details
group by department_id, department_nameBelow is how to do the same in Pyspark:
from pyspark.sql.functions import *
df = spark.read.table("staff_details")
df1 = df.groupby("department_id", "department_name").agg(
collect_list(struct(col("employee_id"), col("first_name"), col("last_name"))).alias("staff_members")
)Both Give you identical dataframe structure to write out to JSON however you would like to:


14 REPLIES 14
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:03 AM
Why do you want to convert the records to JSON? Does it have to be SQL?
You could read the table with the DataFrame APIs and write a JSON file out. Please note that "coalesce" is only there so that it produces a single file. It would be something like this:
df = spark.read.table("YOUR TABLE")
df.coalesce(1).write.format('json').save("/path/to/file")Also, can you show your example with the to_json() function?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:32 AM
repartition(1) is slightly better than coalesce for getting down to one file.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:38 AM
Good call. Thanks @Joseph Kambourakis
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:35 AM
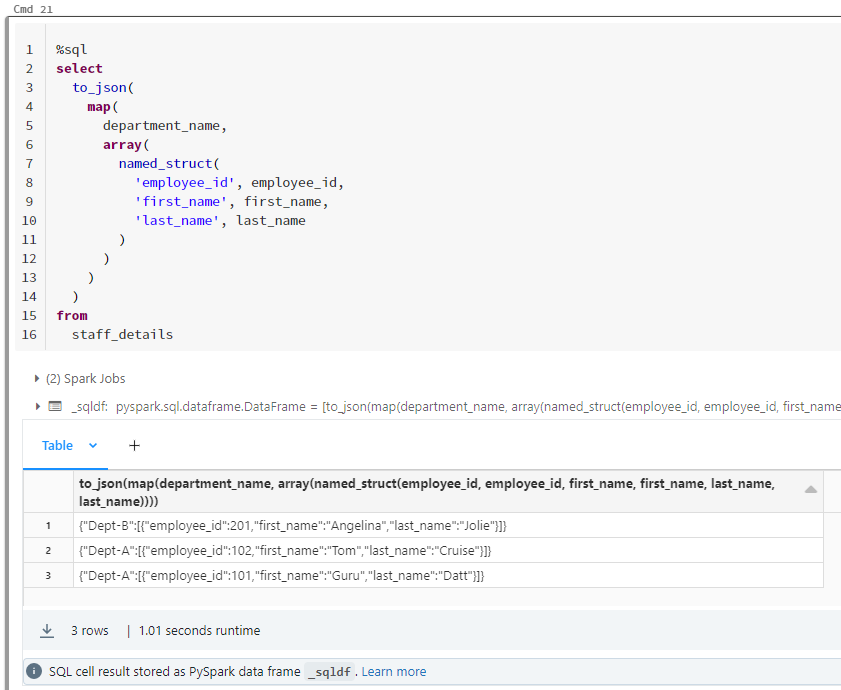
I had tried this, but it creates in the delta format, viz., the json output file contains one row for each record in the table.

And the same thing happens if I use to_json as shown below. Since the examples in the databricks docs, I'm unable to construct a proper query:

Lastly, the intension of required json output as a file, is for the file based integration with other systems.
Hope that clarifies!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:38 AM
That is actually not a delta format. Spark writes data this way. The file you have highlighted is a JSON file.
Why do you need to have a json file?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:55 AM
On Microsoft SQL Server, the following TSQL query would produce the desired output. But, I'm unable to replicate the same in Databricks SQL 😞
SELECT DISTINCT department_id, department_name
,(
SELECT employee_id
,first_name
,last_name
FROM staff_details sdi
WHERE sdi.department_id = sdo.department_id
FOR JSON PATH
) AS staff_members
FROM staff_details sdo
ORDER BY sdo.department_id
FOR JSON PATH, ROOT ('staff_details');Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 10:58 AM
Delta is the default format, but if you put using JSON it will write a json file. The success and committed files are just the way that spark ensures you don't get partial writes.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 11:48 AM
I see. Here is a good example from another community post.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 05:27 PM
@Ryan Chynoweth , regarding your question "Why do you need to have a json file?", the intension of required JSON output as a file, is for the file based integration with other systems downstream.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 02:02 PM
If you want to do this in SQL, here you go:
%sql
select department_id, department_name, collect_list(struct(employee_id, first_name, last_name)) as staff_members
from staff_details
group by department_id, department_nameBelow is how to do the same in Pyspark:
from pyspark.sql.functions import *
df = spark.read.table("staff_details")
df1 = df.groupby("department_id", "department_name").agg(
collect_list(struct(col("employee_id"), col("first_name"), col("last_name"))).alias("staff_members")
)Both Give you identical dataframe structure to write out to JSON however you would like to:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 05:24 PM
@Nathan Anthony , Thank you, Thank you so much!
Thank you @Ryan Chynoweth and @Joseph Kambourakis as well! All of you guys are great helping the community. There is a lot to learn from the community!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 05:31 PM
How do I mark this question as answered?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 05:36 PM
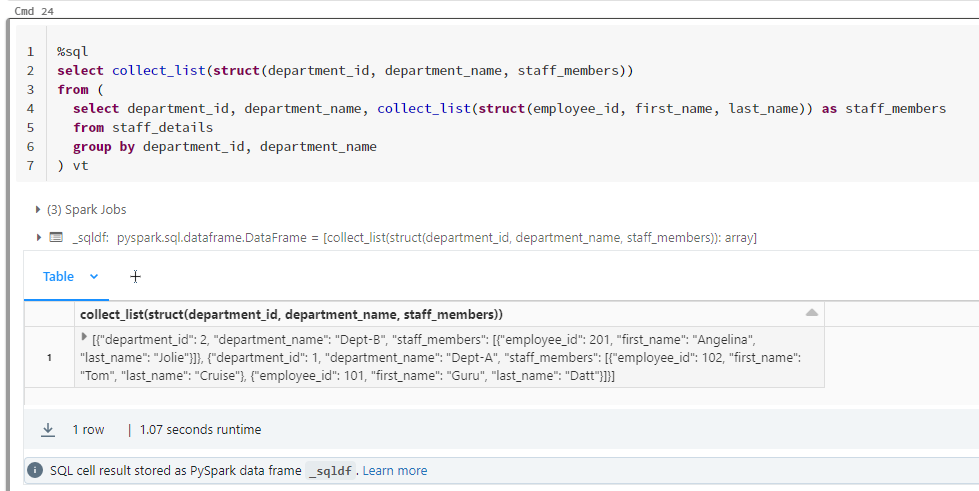
Final sql:
%sql
select
collect_list(
struct(department_id, department_name, staff_members)
)
from
(
select
department_id,
department_name,
collect_list(struct(employee_id, first_name, last_name)) as staff_members
from
staff_details
group by
department_id,
department_name
) vtAnd the output:

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-24-2023 06:14 PM
Glad it worked for you!!
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Transitioning from ADF to Databricks Workflows: Best Practices in a Multi-Workspace (dev-prod) in Data Engineering
- Stop Refreshing. Start Querying. in Data Engineering
- Data Loss in Incremental Batch Jobs Due to Latency in delta file write to blob in Data Engineering
- Knowledge cutoff for Genie in Generative AI
- Delta Sharing with Materialized View - recepient data not refreshing when using Open Protocol in Data Engineering